 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Cross-lingual Voice Transfer for TTS
Sep 20, 2024

In this paper, we introduce a zero-shot Voice Transfer (VT) module that can be seamlessly integrated into a multi-lingual Text-to-speech (TTS) system to transfer an individual's voice across languages. Our proposed VT module comprises a speaker-encoder that processes reference speech, a bottleneck layer, and residual adapters, connected to preexisting TTS layers. We compare the performance of various configurations of these components and report Mean Opinion Score (MOS) and Speaker Similarity across languages. Using a single English reference speech per speaker, we achieve an average voice transfer similarity score of 73% across nine target languages. Vocal characteristics contribute significantly to the construction and perception of individual identity. The loss of one's voice, due to physical or neurological conditions, can lead to a profound sense of loss, impacting one's core identity. As a case study, we demonstrate that our approach can not only transfer typical speech but also restore the voices of individuals with dysarthria, even when only atypical speech samples are available - a valuable utility for those who have never had typical speech or banked their voice. Cross-lingual typical audio samples, plus videos demonstrating voice restoration for dysarthric speakers are available here (google.github.io/tacotron/publications/zero_shot_voice_transfer).
Extending Multilingual Speech Synthesis to 100+ Languages without Transcribed Data
Feb 29, 2024



Collecting high-quality studio recordings of audio is challenging, which limits the language coverage of text-to-speech (TTS) systems. This paper proposes a framework for scaling a multilingual TTS model to 100+ languages using found data without supervision. The proposed framework combines speech-text encoder pretraining with unsupervised training using untranscribed speech and unspoken text data sources, thereby leveraging massively multilingual joint speech and text representation learning. Without any transcribed speech in a new language, this TTS model can generate intelligible speech in >30 unseen languages (CER difference of <10% to ground truth). With just 15 minutes of transcribed, found data, we can reduce the intelligibility difference to 1% or less from the ground-truth, and achieve naturalness scores that match the ground-truth in several languages.
Parallel Tacotron 2: A Non-Autoregressive Neural TTS Model with Differentiable Duration Modeling
Apr 13, 2021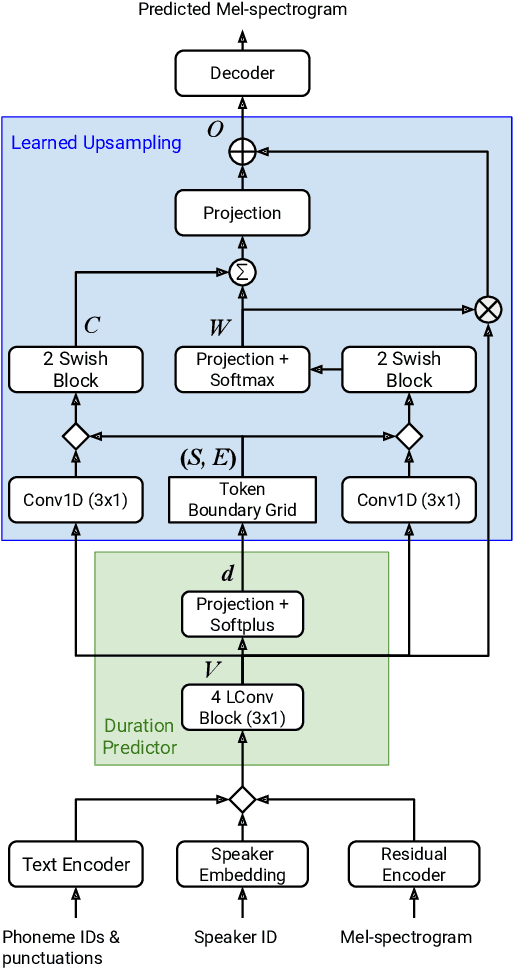
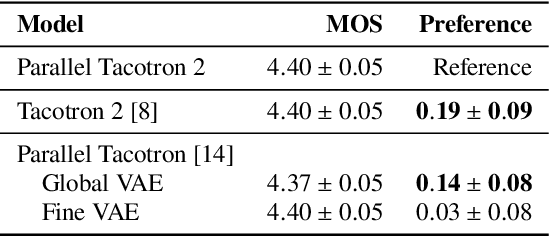
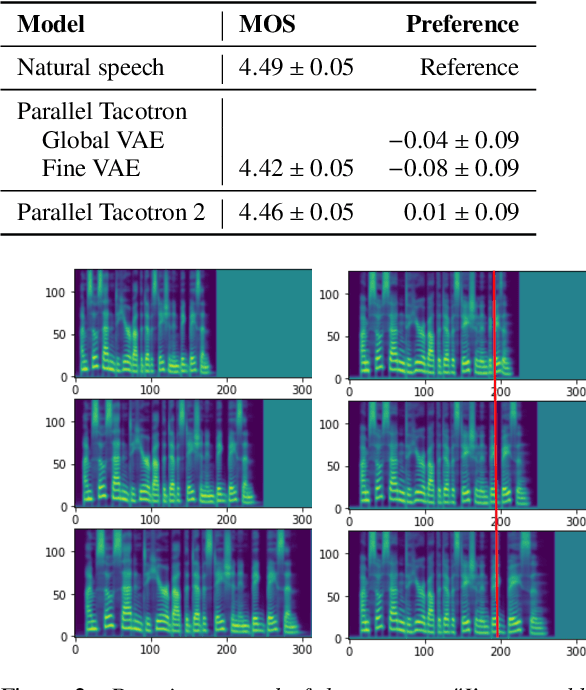

This paper introduces Parallel Tacotron 2, a non-autoregressive neural text-to-speech model with a fully differentiable duration model which does not require supervised duration signals. The duration model is based on a novel attention mechanism and an iterative reconstruction loss based on Soft Dynamic Time Warping, this model can learn token-frame alignments as well as token durations automatically. Experimental results show that Parallel Tacotron 2 outperforms baselines in subjective naturalness in several diverse multi speaker evaluations. Its duration control capability is also demonstrated.
Non-Attentive Tacotron: Robust and Controllable Neural TTS Synthesis Including Unsupervised Duration Modeling
Oct 08, 2020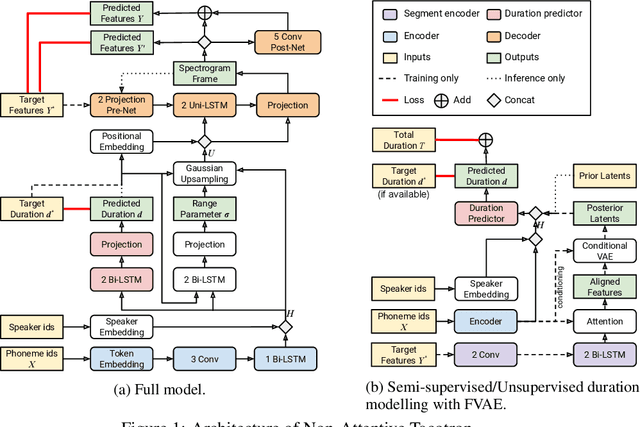

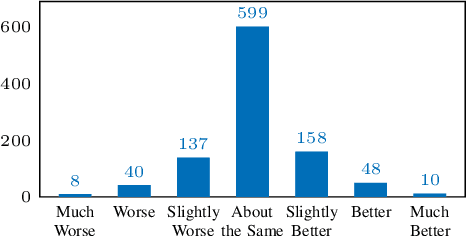

This paper presents Non-Attentive Tacotron based on the Tacotron 2 text-to-speech model, replacing the attention mechanism with an explicit duration predictor. This improves robustness significantly as measured by unaligned duration ratio and word deletion rate, two metrics introduced in this paper for large-scale robustness evaluation using a pre-trained speech recognition model. With the use of Gaussian upsampling, Non-Attentive Tacotron achieves a 5-scale mean opinion score for naturalness of 4.41, slightly outperforming Tacotron 2. The duration predictor enables both utterance-wide and per-phoneme control of duration at inference time. When accurate target durations are scarce or unavailable in the training data, we propose a method using a fine-grained variational auto-encoder to train the duration predictor in a semi-supervised or unsupervised manner, with results almost as good as supervised training.