 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Parrotron for on-device speech-to-speech conversion
Oct 25, 2022



We present a fully on-device and streaming Speech-To-Speech (STS) conversion model that normalizes a given input speech directly to synthesized output speech (a.k.a. Parrotron). Deploying such an end-to-end model locally on mobile devices pose significant challenges in terms of memory footprint and computation requirements. In this paper, we present a streaming-based approach to produce an acceptable delay, with minimal loss in speech conversion quality, when compared to a non-streaming server-based approach. Our approach consists of first streaming the encoder in real time while the speaker is speaking. Then, as soon as the speaker stops speaking, we run the spectrogram decoder in streaming mode along the side of a streaming vocoder to generate output speech in real time. To achieve an acceptable delay quality trade-off, we study a novel hybrid approach for look-ahead in the encoder which combines a look-ahead feature stacker with a look-ahead self-attention. We also compare the model with int4 quantization aware training and int8 post training quantization and show that our streaming approach is 2x faster than real time on the Pixel4 CPU.
Real time spectrogram inversion on mobile phone
Mar 10, 2022
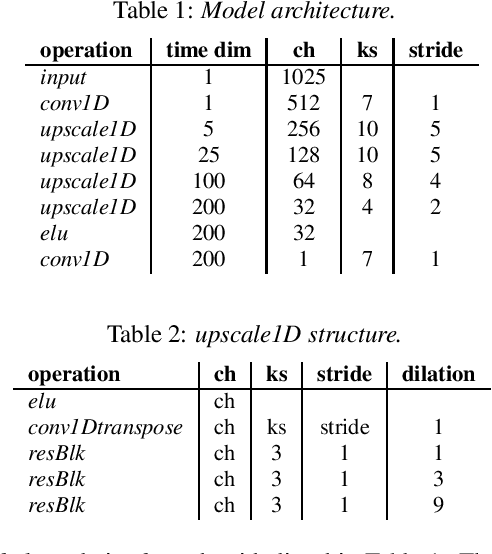


With the growth of computing power on mobile phones and privacy concerns over user's data, on-device real time speech processing has become an important research topic. In this paper, we focus on methods for real time spectrogram inversion, where an algorithm receives a portion of the input signal (e.g., one frame) and processes it incrementally, i.e., operating in streaming mode. We present a real time Griffin Lim(GL) algorithm using a sliding window approach in STFT domain. The proposed algorithm is 2.4x faster than real time on the ARM CPU of a Pixel4. In addition we explore a neural vocoder operating in streaming mode and demonstrate the impact of looking ahead on perceptual quality. As little as one hop size (12.5ms) of lookahead is able to significantly improve perceptual quality in comparison to a causal model. We compare GL with the neural vocoder and show different trade-offs in terms of perceptual quality, on-device latency, algorithmic delay, memory footprint and noise sensitivity. For fair quality assessment of the GL approach, we use input log magnitude spectrogram without mel transformation. We evaluate presented real time spectrogram inversion approaches on clean, noisy and atypical speech.