 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All NVFP4 QAT Recipes Are Equal: How Architecture and Scale Shape Model Quality for Anomaly Segmentation
May 26, 2026Real-time anomaly segmentation demands both high recall and efficient low-precision inference. We study the three-way interaction of model architecture, model scale, and FP4 quantization-aware training (QAT) recipe on a recall-critical brain tumor segmentation task, evaluating multiple architectures, scales, and QAT recipes under a unified protocol. We find that architecture choice has the largest impact on quantization robustness, with attention-based architectures showing remarkable resilience to recipe choice while CNN degrades under gradient-quantizing recipes at larger scales. At low capacity, FP4 can discretize softmax attention, but advanced QAT recipes prevent this collapse. At larger scales, advanced recipes mitigate gradient quantization noise that degrades CNN quality. Five-fold patient-level cross-validation confirms these findings are robust to data partition. Our results show that the Swin Transformer is robust to QAT recipe choice across all scales, making it the recommended architecture for FP4-quantized anomaly segmentation.
Nemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
Quantization-Aware Distillation for NVFP4 Inference Accuracy Recovery
Jan 27, 2026This technical report presents quantization-aware distillation (QAD) and our best practices for recovering accuracy of NVFP4-quantized large language models (LLMs) and vision-language models (VLMs). QAD distills a full-precision teacher model into a quantized student model using a KL divergence loss. While applying distillation to quantized models is not a new idea, we observe key advantages of QAD for today's LLMs: 1. It shows remarkable effectiveness and stability for models trained through multi-stage post-training pipelines, including supervised fine-tuning (SFT), reinforcement learning (RL), and model merging, where traditional quantization-aware training (QAT) suffers from engineering complexity and training instability; 2. It is robust to data quality and coverage, enabling accuracy recovery without full training data. We evaluate QAD across multiple post-trained models including AceReason Nemotron, Nemotron 3 Nano, Nemotron Nano V2, Nemotron Nano V2 VL (VLM), and Llama Nemotron Super v1, showing consistent recovery to near-BF16 accuracy.
NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model
Aug 21, 2025



We introduce Nemotron-Nano-9B-v2, a hybrid Mamba-Transformer language model designed to increase throughput for reasoning workloads while achieving state-of-the-art accuracy compared to similarly-sized models. Nemotron-Nano-9B-v2 builds on the Nemotron-H architecture, in which the majority of the self-attention layers in the common Transformer architecture are replaced with Mamba-2 layers, to achieve improved inference speed when generating the long thinking traces needed for reasoning. We create Nemotron-Nano-9B-v2 by first pre-training a 12-billion-parameter model (Nemotron-Nano-12B-v2-Base) on 20 trillion tokens using an FP8 training recipe. After aligning Nemotron-Nano-12B-v2-Base, we employ the Minitron strategy to compress and distill the model with the goal of enabling inference on up to 128k tokens on a single NVIDIA A10G GPU (22GiB of memory, bfloat16 precision). Compared to existing similarly-sized models (e.g., Qwen3-8B), we show that Nemotron-Nano-9B-v2 achieves on-par or better accuracy on reasoning benchmarks while achieving up to 6x higher inference throughput in reasoning settings like 8k input and 16k output tokens. We are releasing Nemotron-Nano-9B-v2, Nemotron-Nano12B-v2-Base, and Nemotron-Nano-9B-v2-Base checkpoints along with the majority of our pre- and post-training datasets on Hugging Face.
Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
Apr 10, 2025



As inference-time scaling becomes critical for enhanced reasoning capabilities, it is increasingly becoming important to build models that are efficient to infer. We introduce Nemotron-H, a family of 8B and 56B/47B hybrid Mamba-Transformer models designed to reduce inference cost for a given accuracy level. To achieve this goal, we replace the majority of self-attention layers in the common Transformer model architecture with Mamba layers that perform constant computation and require constant memory per generated token. We show that Nemotron-H models offer either better or on-par accuracy compared to other similarly-sized state-of-the-art open-sourced Transformer models (e.g., Qwen-2.5-7B/72B and Llama-3.1-8B/70B), while being up to 3$\times$ faster at inference. To further increase inference speed and reduce the memory required at inference time, we created Nemotron-H-47B-Base from the 56B model using a new compression via pruning and distillation technique called MiniPuzzle. Nemotron-H-47B-Base achieves similar accuracy to the 56B model, but is 20% faster to infer. In addition, we introduce an FP8-based training recipe and show that it can achieve on par results with BF16-based training. This recipe is used to train the 56B model. All Nemotron-H models will be released, with support in Hugging Face, NeMo, and Megatron-LM.
Methods of improving LLM training stability
Oct 22, 2024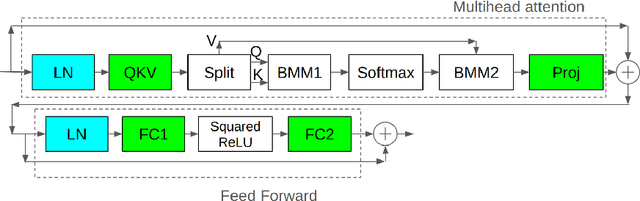

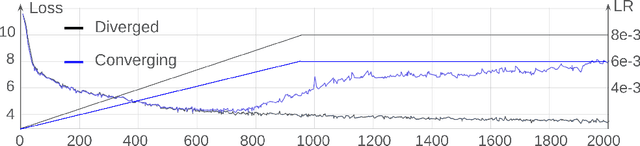

Training stability of large language models(LLMs) is an important research topic. Reproducing training instabilities can be costly, so we use a small language model with 830M parameters and experiment with higher learning rates to force models to diverge. One of the sources of training instability is the growth of logits in attention layers. We extend the focus of the previous work and look not only at the magnitude of the logits but at all outputs of linear layers in the Transformer block. We observe that with a high learning rate the L2 norm of all linear layer outputs can grow with each training step and the model diverges. Specifically we observe that QKV, Proj and FC2 layers have the largest growth of the output magnitude. This prompts us to explore several options: 1) apply layer normalization not only after QK layers but also after Proj and FC2 layers too; 2) apply layer normalization after the QKV layer (and remove pre normalization). 3) apply QK layer normalization together with softmax capping. We show that with the last two methods we can increase learning rate by 1.5x (without model divergence) in comparison to an approach based on QK layer normalization only. Also we observe significant perplexity improvements for all three methods in comparison to the baseline model.
USM RNN-T model weights binarization
Jun 06, 2024



Large-scale universal speech models (USM) are already used in production. However, as the model size grows, the serving cost grows too. Serving cost of large models is dominated by model size that is why model size reduction is an important research topic. In this work we are focused on model size reduction using weights only quantization. We present the weights binarization of USM Recurrent Neural Network Transducer (RNN-T) and show that its model size can be reduced by 15.9x times at cost of word error rate (WER) increase by only 1.9% in comparison to the float32 model. It makes it attractive for practical applications.
SimulTron: On-Device Simultaneous Speech to Speech Translation
Jun 04, 2024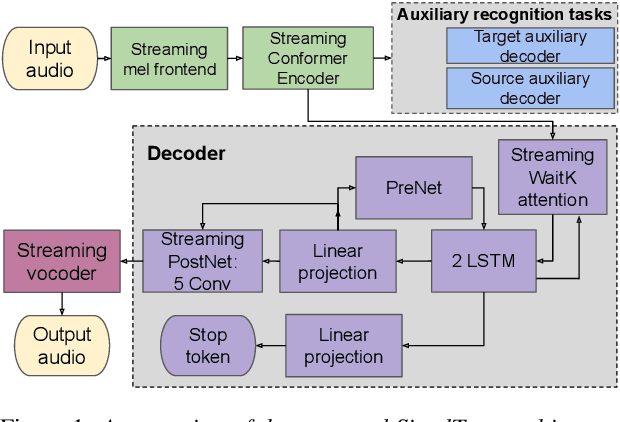
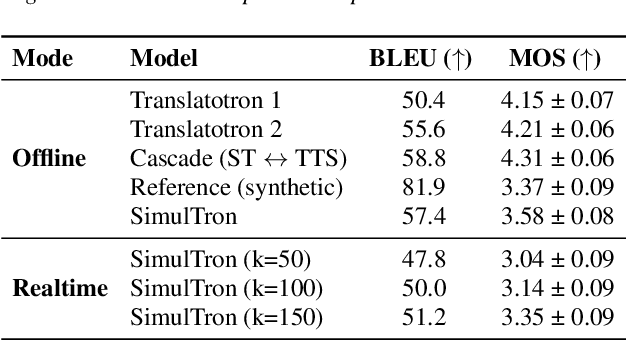

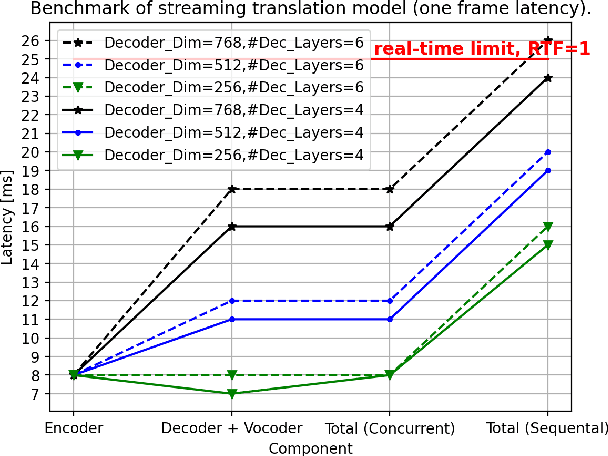
Simultaneous speech-to-speech translation (S2ST) holds the promise of breaking down communication barriers and enabling fluid conversations across languages. However, achieving accurate, real-time translation through mobile devices remains a major challenge. We introduce SimulTron, a novel S2ST architecture designed to tackle this task. SimulTron is a lightweight direct S2ST model that uses the strengths of the Translatotron framework while incorporating key modifications for streaming operation, and an adjustable fixed delay. Our experiments show that SimulTron surpasses Translatotron 2 in offline evaluations. Furthermore, real-time evaluations reveal that SimulTron improves upon the performance achieved by Translatotron 1. Additionally, SimulTron achieves superior BLEU scores and latency compared to previous real-time S2ST method on the MuST-C dataset. Significantly, we have successfully deployed SimulTron on a Pixel 7 Pro device, show its potential for simultaneous S2ST on-device.
USM-Lite: Quantization and Sparsity Aware Fine-tuning for Speech Recognition with Universal Speech Models
Jan 03, 2024End-to-end automatic speech recognition (ASR) models have seen revolutionary quality gains with the recent development of large-scale universal speech models (USM). However, deploying these massive USMs is extremely expensive due to the enormous memory usage and computational cost. Therefore, model compression is an important research topic to fit USM-based ASR under budget in real-world scenarios. In this study, we propose a USM fine-tuning approach for ASR, with a low-bit quantization and N:M structured sparsity aware paradigm on the model weights, reducing the model complexity from parameter precision and matrix topology perspectives. We conducted extensive experiments with a 2-billion parameter USM on a large-scale voice search dataset to evaluate our proposed method. A series of ablation studies validate the effectiveness of up to int4 quantization and 2:4 sparsity. However, a single compression technique fails to recover the performance well under extreme setups including int2 quantization and 1:4 sparsity. By contrast, our proposed method can compress the model to have 9.4% of the size, at the cost of only 7.3% relative word error rate (WER) regressions. We also provided in-depth analyses on the results and discussions on the limitations and potential solutions, which would be valuable for future studies.
2-bit Conformer quantization for automatic speech recognition
May 26, 2023

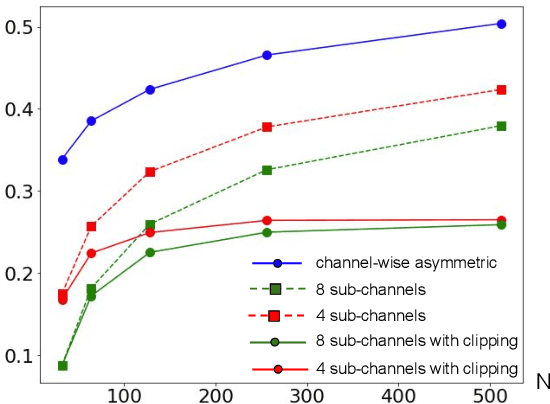

Large speech models are rapidly gaining traction in research community. As a result, model compression has become an important topic, so that these models can fit in memory and be served with reduced cost. Practical approaches for compressing automatic speech recognition (ASR) model use int8 or int4 weight quantization. In this study, we propose to develop 2-bit ASR models. We explore the impact of symmetric and asymmetric quantization combined with sub-channel quantization and clipping on both LibriSpeech dataset and large-scale training data. We obtain a lossless 2-bit Conformer model with 32% model size reduction when compared to state of the art 4-bit Conformer model for LibriSpeech. With the large-scale training data, we obtain a 2-bit Conformer model with over 40% model size reduction against the 4-bit version at the cost of 17% relative word error rate degradation