 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepNet-VSR: Reparameterizable Architecture for High-Fidelity Video Super-Resolution
Apr 22, 2025



As a fundamental challenge in visual computing, video super-resolution (VSR) focuses on reconstructing highdefinition video sequences from their degraded lowresolution counterparts. While deep convolutional neural networks have demonstrated state-of-the-art performance in spatial-temporal super-resolution tasks, their computationally intensive nature poses significant deployment challenges for resource-constrained edge devices, particularly in real-time mobile video processing scenarios where power efficiency and latency constraints coexist. In this work, we propose a Reparameterizable Architecture for High Fidelity Video Super Resolution method, named RepNet-VSR, for real-time 4x video super-resolution. On the REDS validation set, the proposed model achieves 27.79 dB PSNR when processing 180p to 720p frames in 103 ms per 10 frames on a MediaTek Dimensity NPU. The competition results demonstrate an excellent balance between restoration quality and deployment efficiency. The proposed method scores higher than the previous champion algorithm of MAI video super-resolution challenge.
USM RNN-T model weights binarization
Jun 06, 2024



Large-scale universal speech models (USM) are already used in production. However, as the model size grows, the serving cost grows too. Serving cost of large models is dominated by model size that is why model size reduction is an important research topic. In this work we are focused on model size reduction using weights only quantization. We present the weights binarization of USM Recurrent Neural Network Transducer (RNN-T) and show that its model size can be reduced by 15.9x times at cost of word error rate (WER) increase by only 1.9% in comparison to the float32 model. It makes it attractive for practical applications.
Semi-supervised Video Semantic Segmentation Using Unreliable Pseudo Labels for PVUW2024
Jun 02, 2024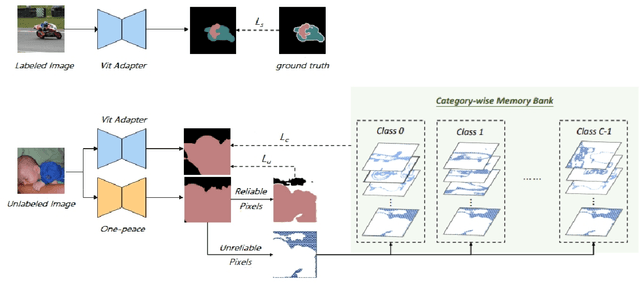

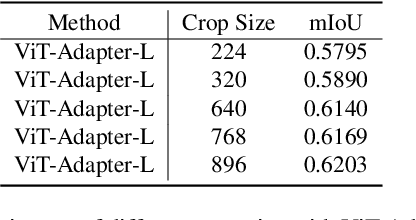

Pixel-level Scene Understanding is one of the fundamental problems in computer vision, which aims at recognizing object classes, masks and semantics of each pixel in the given image. Compared with image scene parsing, video scene parsing introduces temporal information, which can effectively improve the consistency and accuracy of prediction,because the real-world is actually video-based rather than a static state. In this paper, we adopt semi-supervised video semantic segmentation method based on unreliable pseudo labels. Then, We ensemble the teacher network model with the student network model to generate pseudo labels and retrain the student network. Our method achieves the mIoU scores of 63.71% and 67.83% on development test and final test respectively. Finally, we obtain the 1st place in the Video Scene Parsing in the Wild Challenge at CVPR 2024.
2nd Place Solution for PVUW Challenge 2024: Video Panoptic Segmentation
Jun 01, 2024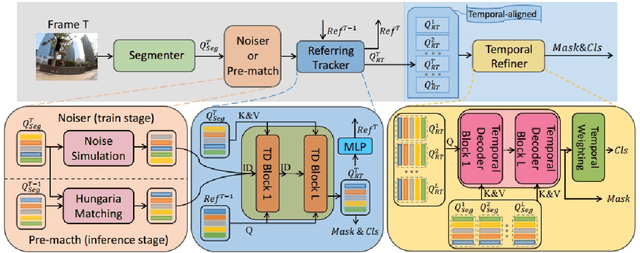
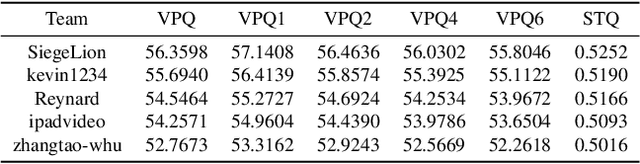
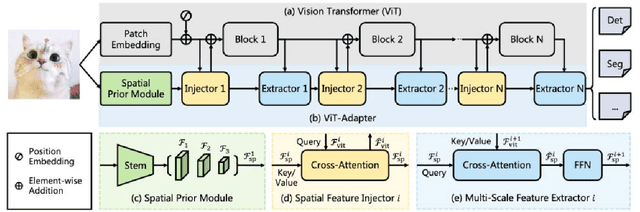
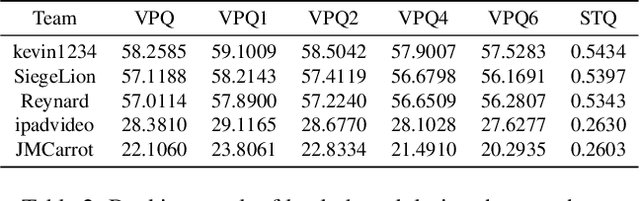
Video Panoptic Segmentation (VPS) is a challenging task that is extends from image panoptic segmentation.VPS aims to simultaneously classify, track, segment all objects in a video, including both things and stuff. Due to its wide application in many downstream tasks such as video understanding, video editing, and autonomous driving. In order to deal with the task of video panoptic segmentation in the wild, we propose a robust integrated video panoptic segmentation solution. We use DVIS++ framework as our baseline to generate the initial masks. Then,we add an additional image semantic segmentation model to further improve the performance of semantic classes.Finally, our method achieves state-of-the-art performance with a VPQ score of 56.36 and 57.12 in the development and test phases, respectively, and ultimately ranked 2nd in the VPS track of the PVUW Challenge at CVPR2024.
Real-Time 4K Super-Resolution of Compressed AVIF Images. AIS 2024 Challenge Survey
Apr 25, 2024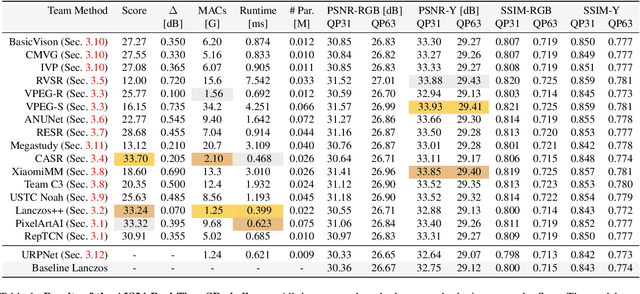
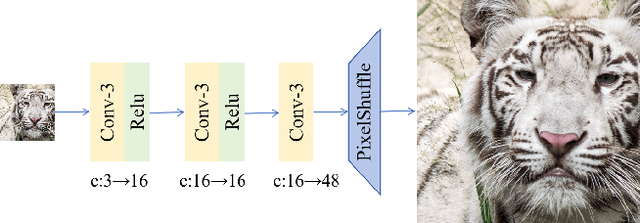
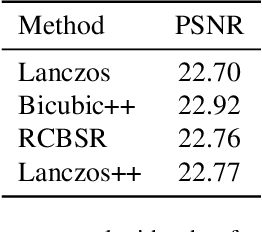
This paper introduces a novel benchmark as part of the AIS 2024 Real-Time Image Super-Resolution (RTSR) Challenge, which aims to upscale compressed images from 540p to 4K resolution (4x factor) in real-time on commercial GPUs. For this, we use a diverse test set containing a variety of 4K images ranging from digital art to gaming and photography. The images are compressed using the modern AVIF codec, instead of JPEG. All the proposed methods improve PSNR fidelity over Lanczos interpolation, and process images under 10ms. Out of the 160 participants, 25 teams submitted their code and models. The solutions present novel designs tailored for memory-efficiency and runtime on edge devices. This survey describes the best solutions for real-time SR of compressed high-resolution images.
Recyclable Semi-supervised Method Based on Multi-model Ensemble for Video Scene Parsing
Jun 05, 2023



Pixel-level Scene Understanding is one of the fundamental problems in computer vision, which aims at recognizing object classes, masks and semantics of each pixel in the given image. Since the real-world is actually video-based rather than a static state, learning to perform video semantic segmentation is more reasonable and practical for realistic applications. In this paper, we adopt Mask2Former as architecture and ViT-Adapter as backbone. Then, we propose a recyclable semi-supervised training method based on multi-model ensemble. Our method achieves the mIoU scores of 62.97% and 65.83% on Development test and final test respectively. Finally, we obtain the 2nd place in the Video Scene Parsing in the Wild Challenge at CVPR 2023.
Power Efficient Video Super-Resolution on Mobile NPUs with Deep Learning, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022



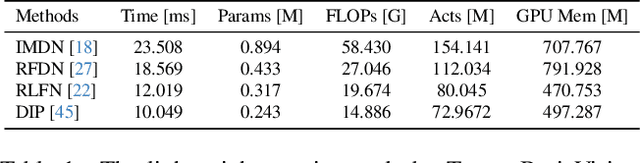
Video super-resolution is one of the most popular tasks on mobile devices, being widely used for an automatic improvement of low-bitrate and low-resolution video streams. While numerous solutions have been proposed for this problem, they are usually quite computationally demanding, demonstrating low FPS rates and power efficiency on mobile devices. In this Mobile AI challenge, we address this problem and propose the participants to design an end-to-end real-time video super-resolution solution for mobile NPUs optimized for low energy consumption. The participants were provided with the REDS training dataset containing video sequences for a 4X video upscaling task. The runtime and power efficiency of all models was evaluated on the powerful MediaTek Dimensity 9000 platform with a dedicated AI processing unit capable of accelerating floating-point and quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 500 FPS rate and 0.2 [Watt / 30 FPS] power consumption. A detailed description of all models developed in the challenge is provided in this paper.
Accelerating RNN-T Training and Inference Using CTC guidance
Oct 29, 2022We propose a novel method to accelerate training and inference process of recurrent neural network transducer (RNN-T) based on the guidance from a co-trained connectionist temporal classification (CTC) model. We made a key assumption that if an encoder embedding frame is classified as a blank frame by the CTC model, it is likely that this frame will be aligned to blank for all the partial alignments or hypotheses in RNN-T and it can be discarded from the decoder input. We also show that this frame reduction operation can be applied in the middle of the encoder, which result in significant speed up for the training and inference in RNN-T. We further show that the CTC alignment, a by-product of the CTC decoder, can also be used to perform lattice reduction for RNN-T during training. Our method is evaluated on the Librispeech and SpeechStew tasks. We demonstrate that the proposed method is able to accelerate the RNN-T inference by 2.2 times with similar or slightly better word error rates (WER).
NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video: Dataset, Methods and Results
Apr 25, 2022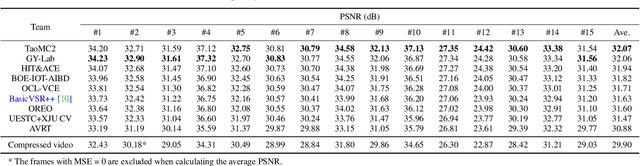
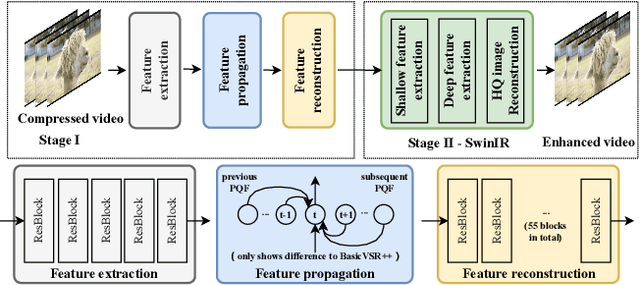
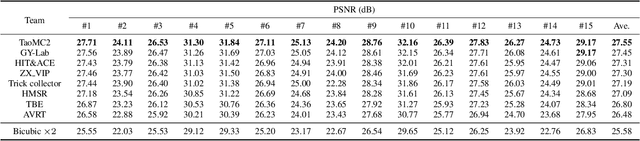

This paper reviews the NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video. In this challenge, we proposed the LDV 2.0 dataset, which includes the LDV dataset (240 videos) and 95 additional videos. This challenge includes three tracks. Track 1 aims at enhancing the videos compressed by HEVC at a fixed QP. Track 2 and Track 3 target both the super-resolution and quality enhancement of HEVC compressed video. They require x2 and x4 super-resolution, respectively. The three tracks totally attract more than 600 registrations. In the test phase, 8 teams, 8 teams and 12 teams submitted the final results to Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution and quality enhancement of compressed video. The proposed LDV 2.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge (including open-sourced codes) is at https://github.com/RenYang-home/NTIRE22_VEnh_SR.