 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised Video Semantic Segmentation Using Unreliable Pseudo Labels for PVUW2024
Paper and Code
Jun 02, 2024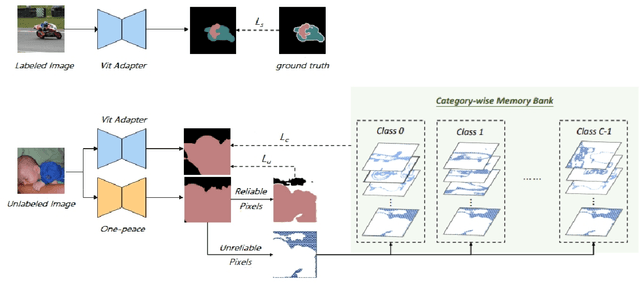

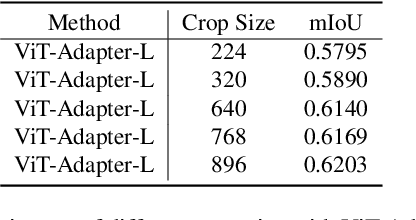

Pixel-level Scene Understanding is one of the fundamental problems in computer vision, which aims at recognizing object classes, masks and semantics of each pixel in the given image. Compared with image scene parsing, video scene parsing introduces temporal information, which can effectively improve the consistency and accuracy of prediction,because the real-world is actually video-based rather than a static state. In this paper, we adopt semi-supervised video semantic segmentation method based on unreliable pseudo labels. Then, We ensemble the teacher network model with the student network model to generate pseudo labels and retrain the student network. Our method achieves the mIoU scores of 63.71% and 67.83% on development test and final test respectively. Finally, we obtain the 1st place in the Video Scene Parsing in the Wild Challenge at CVPR 2024.