 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Mono-to-Binaural Speech Synthesis
Dec 11, 2024


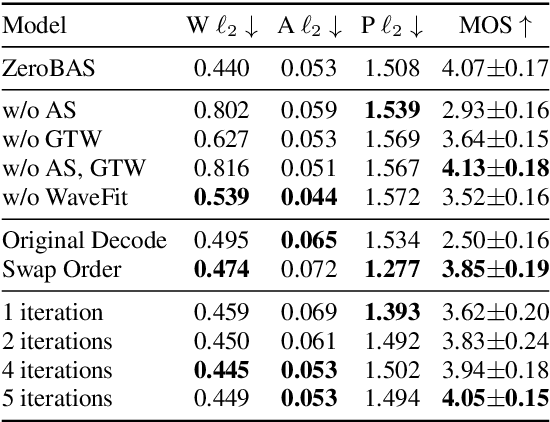
We present ZeroBAS, a neural method to synthesize binaural audio from monaural audio recordings and positional information without training on any binaural data. To our knowledge, this is the first published zero-shot neural approach to mono-to-binaural audio synthesis. Specifically, we show that a parameter-free geometric time warping and amplitude scaling based on source location suffices to get an initial binaural synthesis that can be refined by iteratively applying a pretrained denoising vocoder. Furthermore, we find this leads to generalization across room conditions, which we measure by introducing a new dataset, TUT Mono-to-Binaural, to evaluate state-of-the-art monaural-to-binaural synthesis methods on unseen conditions. Our zero-shot method is perceptually on-par with the performance of supervised methods on the standard mono-to-binaural dataset, and even surpasses them on our out-of-distribution TUT Mono-to-Binaural dataset. Our results highlight the potential of pretrained generative audio models and zero-shot learning to unlock robust binaural audio synthesis.
SimulTron: On-Device Simultaneous Speech to Speech Translation
Jun 04, 2024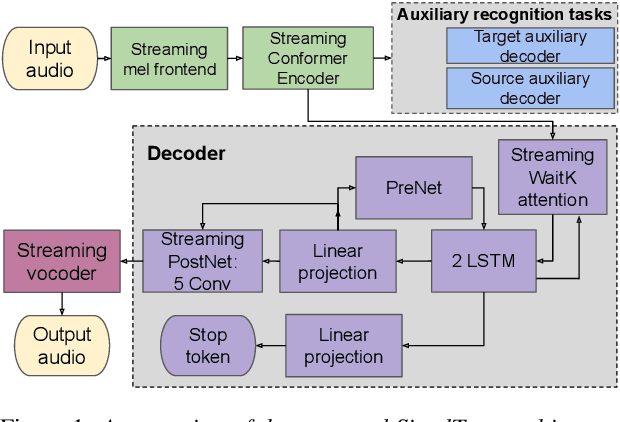
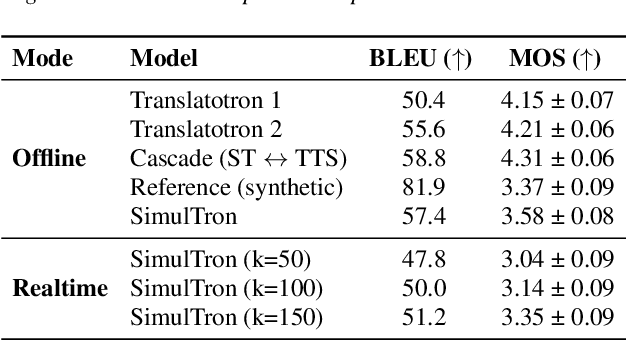

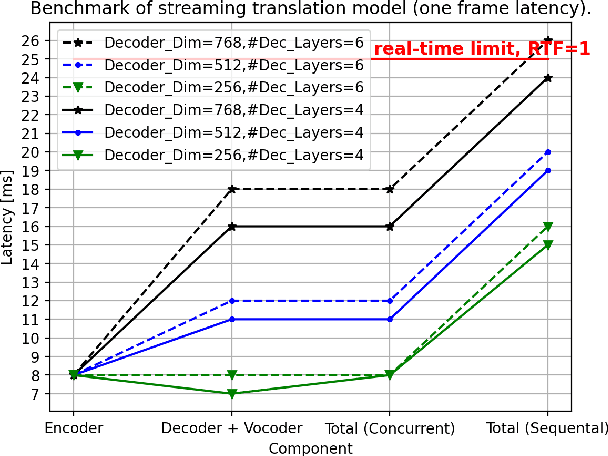
Simultaneous speech-to-speech translation (S2ST) holds the promise of breaking down communication barriers and enabling fluid conversations across languages. However, achieving accurate, real-time translation through mobile devices remains a major challenge. We introduce SimulTron, a novel S2ST architecture designed to tackle this task. SimulTron is a lightweight direct S2ST model that uses the strengths of the Translatotron framework while incorporating key modifications for streaming operation, and an adjustable fixed delay. Our experiments show that SimulTron surpasses Translatotron 2 in offline evaluations. Furthermore, real-time evaluations reveal that SimulTron improves upon the performance achieved by Translatotron 1. Additionally, SimulTron achieves superior BLEU scores and latency compared to previous real-time S2ST method on the MuST-C dataset. Significantly, we have successfully deployed SimulTron on a Pixel 7 Pro device, show its potential for simultaneous S2ST on-device.
Efficient Data Generation for Source-grounded Information-seeking Dialogs: A Use Case for Meeting Transcripts
May 02, 2024Existing methods for creating source-grounded information-seeking dialog datasets are often costly and hard to implement due to their sole reliance on human annotators. We propose combining large language models (LLMs) prompting with human expertise for more efficient and reliable data generation. Instead of the labor-intensive Wizard-of-Oz (WOZ) method, where two annotators generate a dialog from scratch, role-playing agent and user, we use LLM generation to simulate the two roles. Annotators then verify the output and augment it with attribution data. We demonstrate our method by constructing MISeD -- Meeting Information Seeking Dialogs dataset -- the first information-seeking dialog dataset focused on meeting transcripts. Models finetuned with MISeD demonstrate superior performance on our test set, as well as on a novel fully-manual WOZ test set and an existing query-based summarization benchmark, suggesting the utility of our approach.
Border-Peeling Clustering
Dec 14, 2016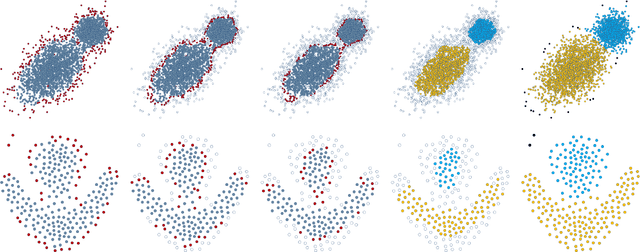
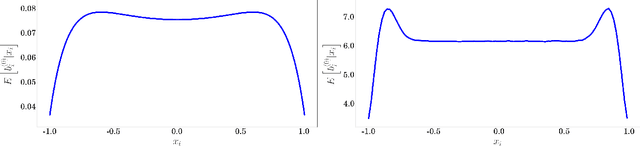
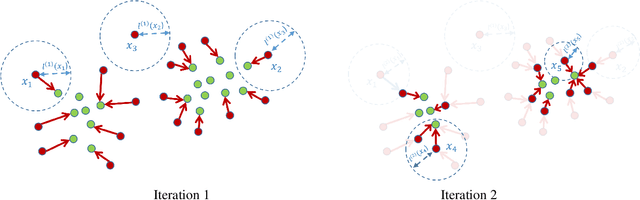
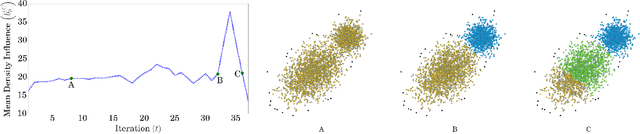
In this paper, we present a novel non-parametric clustering technique, which is based on an iterative algorithm that peels off layers of points around the clusters. Our technique is based on the notion that each latent cluster is comprised of layers that surround its core, where the external layers, or border points, implicitly separate the clusters. Analyzing the K-nearest neighbors of the points makes it possible to identify the border points and associate them with points of inner layers. Our clustering algorithm iteratively identifies border points, peels them, and separates the latent clusters. We show that the peeling process adapts to the local density and successfully separates adjacent clusters. A notable quality of the Border-Peeling algorithm is that it does not require any parameter tuning in order to outperform state-of-the-art finely-tuned non-parametric clustering methods, including Mean-Shift and DBSCAN. We further assess our technique on high-dimensional datasets that vary in size and characteristics. In particular, we analyze the space of deep features that were trained by a convolutional neural network.