 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScore Based Error Correcting Code Decoder
May 27, 2026Error-correcting codes enable reliable communication, yet practical soft decoding remains challenging across code families and block lengths. We propose SB-ECC, a score-based decoder that casts decoding as continuous-time denoising. A neural denoiser defines a probability-flow ordinary differential equation (ODE) that iteratively updates the noisy channel observation toward a valid codeword, guided by parity constraints. The model is trained across noise levels without time/SNR conditioning, enabling inference without SNR estimation and supporting a direct latency accuracy trade off controlled by the ODE solver budget. We use the raw signed channel observation as input for learning a continuous denoising field. Across 42 code/SNR settings, SB-ECC achieves the best BER in 39/42 entries, with an average SNR gain of 0.17dB and a maximum gain of 0.46dB over the strongest competing baseline, we showed that swapping the solver from Euler to DPM preserves -ln(BER) while reducing end-to-end decoding time by 8.86% on average (up to 12.82%).
SAFEdit: Does Multi-Agent Decomposition Resolve the Reliability Challenges of Instructed Code Editing?
Apr 28, 2026Instructed code editing is a significant challenge for large language models (LLMs). On the EditBench benchmark, 39 of 40 evaluated models obtain a task success rate (TSR) below 60 percent, highlighting a gap between general code generation and the ability to perform instruction-driven editing under executable test constraints. To address this, we propose SAFEdit, a multi-agent framework for instructed code editing that decomposes the editing process into specialized roles to improve reliability and reduce unintended code changes. A Planner Agent produces an explicit, visibility-aware edit plan, an Editor Agent applies minimal, literal code modifications, and a Verifier Agent executes real test runs. When tests fail, SAFEdit uses a Failure Abstraction Layer (FAL) to transform raw test logs into structured diagnostic feedback, which is fed back to the Editor to support iterative refinement. We compare SAFEdit against both prior single-model results reported for EditBench and an implemented ReAct single-agent baseline under the same evaluation conditions. We used EditBench to evaluate SAFEdit on 445 code editing instances in five languages (English, Polish, Spanish, Chinese, and Russian) under varying spatial context variants. SAFEdit achieved 68.6 percent TSR, outperforming the single-model baseline by 3.8 percentage points and the ReAct single-agent baseline by 8.6 percentage points. The iterative refinement loop was found to contribute 17.4 percentage points to SAFEdit's overall success rate. SAFEdit's automated error analysis further indicates a reduction in instruction-level hallucinations compared to single-agent approaches, providing an additional framework component for interpreting failures beyond pass or fail outcomes.
ILRR: Inference-Time Steering Method for Masked Diffusion Language Models
Jan 29, 2026Discrete Diffusion Language Models (DLMs) offer a promising non-autoregressive alternative for text generation, yet effective mechanisms for inference-time control remain relatively underexplored. Existing approaches include sampling-level guidance procedures or trajectory optimization mechanisms. In this work, we introduce Iterative Latent Representation Refinement (ILRR), a learning-free framework for steering DLMs using a single reference sequence. ILRR guides generation by dynamically aligning the internal activations of the generated sequence with those of a given reference throughout the denoising process. This approach captures and transfers high-level semantic properties, with a tunable steering scale enabling flexible control over attributes such as sentiment. We further introduce Spatially Modulated Steering, an extension that enables steering long texts using shorter references by regulating guidance intensity across the sequence. Empirically, we demonstrate that ILRR achieves effective attribute steering on LLaDA and MDLM architectures with a minor computational overhead, requiring only one additional parallel forward pass per denoising step. Under the same compute budget, ILRR improves attribute accuracy over comparable baselines by 10$\%$ to 60$\%$ points, while maintaining high generation quality.
Neural Minimum Weight Perfect Matching for Quantum Error Codes
Jan 01, 2026Realizing the full potential of quantum computation requires Quantum Error Correction (QEC). QEC reduces error rates by encoding logical information across redundant physical qubits, enabling errors to be detected and corrected. A common decoder used for this task is Minimum Weight Perfect Matching (MWPM) a graph-based algorithm that relies on edge weights to identify the most likely error chains. In this work, we propose a data-driven decoder named Neural Minimum Weight Perfect Matching (NMWPM). Our decoder utilizes a hybrid architecture that integrates Graph Neural Networks (GNNs) to extract local syndrome features and Transformers to capture long-range global dependencies, which are then used to predict dynamic edge weights for the MWPM decoder. To facilitate training through the non-differentiable MWPM algorithm, we formulate a novel proxy loss function that enables end-to-end optimization. Our findings demonstrate significant performance reduction in the Logical Error Rate (LER) over standard baselines, highlighting the advantage of hybrid decoders that combine the predictive capabilities of neural networks with the algorithmic structure of classical matching.
Neural Brain Fields: A NeRF-Inspired Approach for Generating Nonexistent EEG Electrodes
Dec 20, 2025Electroencephalography (EEG) data present unique modeling challenges because recordings vary in length, exhibit very low signal to noise ratios, differ significantly across participants, drift over time within sessions, and are rarely available in large and clean datasets. Consequently, developing deep learning methods that can effectively process EEG signals remains an open and important research problem. To tackle this problem, this work presents a new method inspired by Neural Radiance Fields (NeRF). In computer vision, NeRF techniques train a neural network to memorize the appearance of a 3D scene and then uses its learned parameters to render and edit the scene from any viewpoint. We draw an analogy between the discrete images captured from different viewpoints used to learn a continuous 3D scene in NeRF, and EEG electrodes positioned at different locations on the scalp, which are used to infer the underlying representation of continuous neural activity. Building on this connection, we show that a neural network can be trained on a single EEG sample in a NeRF style manner to produce a fixed size and informative weight vector that encodes the entire signal. Moreover, via this representation we can render the EEG signal at previously unseen time steps and spatial electrode positions. We demonstrate that this approach enables continuous visualization of brain activity at any desired resolution, including ultra high resolution, and reconstruction of raw EEG signals. Finally, our empirical analysis shows that this method can effectively simulate nonexistent electrodes data in EEG recordings, allowing the reconstructed signal to be fed into standard EEG processing networks to improve performance.
SAQ: Stabilizer-Aware Quantum Error Correction Decoder
Dec 09, 2025



Quantum Error Correction (QEC) decoding faces a fundamental accuracy-efficiency tradeoff. Classical methods like Minimum Weight Perfect Matching (MWPM) exhibit variable performance across noise models and suffer from polynomial complexity, while tensor network decoders achieve high accuracy but at prohibitively high computational cost. Recent neural decoders reduce complexity but lack the accuracy needed to compete with computationally expensive classical methods. We introduce SAQ-Decoder, a unified framework combining transformer-based learning with constraint aware post-processing that achieves both near Maximum Likelihood (ML) accuracy and linear computational scalability with respect to the syndrome size. Our approach combines a dual-stream transformer architecture that processes syndromes and logical information with asymmetric attention patterns, and a novel differentiable logical loss that directly optimizes Logical Error Rates (LER) through smooth approximations over finite fields. SAQ-Decoder achieves near-optimal performance, with error thresholds of 10.99% (independent noise) and 18.6% (depolarizing noise) on toric codes that approach the ML bounds of 11.0% and 18.9% while outperforming existing neural and classical baselines in accuracy, complexity, and parameter efficiency. Our findings establish that learned decoders can simultaneously achieve competitive decoding accuracy and computational efficiency, addressing key requirements for practical fault-tolerant quantum computing systems.
Differential Mamba
Jul 08, 2025Sequence models like Transformers and RNNs often overallocate attention to irrelevant context, leading to noisy intermediate representations. This degrades LLM capabilities by promoting hallucinations, weakening long-range and retrieval abilities, and reducing robustness. Recent work has shown that differential design can mitigate this issue in Transformers, improving their effectiveness across various applications. In this paper, we explore whether these techniques, originally developed for Transformers, can be applied to Mamba, a recent architecture based on selective state-space layers that achieves Transformer-level performance with greater efficiency. We show that a naive adaptation of differential design to Mamba is insufficient and requires careful architectural modifications. To address this, we introduce a novel differential mechanism for Mamba, empirically validated on language modeling benchmarks, demonstrating improved retrieval capabilities and superior performance over vanilla Mamba. Finally, we conduct extensive ablation studies and empirical analyses to justify our design choices and provide evidence that our approach effectively mitigates the overallocation problem in Mamba-based models. Our code is publicly available.
Plan for Speed -- Dilated Scheduling for Masked Diffusion Language Models
Jun 23, 2025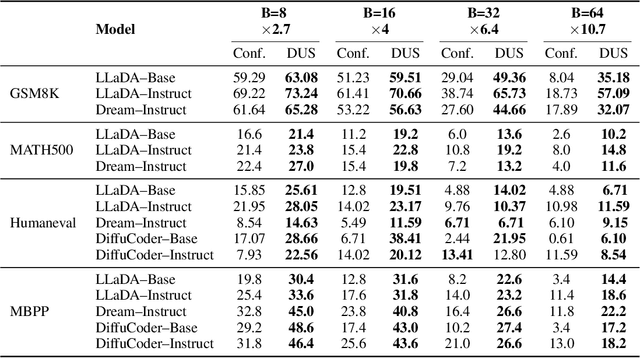



Masked diffusion language models (MDLM) have shown strong promise for non-autoregressive text generation, yet existing samplers act as implicit planners, selecting tokens to unmask via denoiser confidence or entropy scores. Such heuristics falter under parallel unmasking - they ignore pairwise interactions between tokens and cannot account for dependencies when unmasking multiple positions at once, limiting their inference time to traditional auto-regressive (AR) models. We introduce the Dilated-scheduled Unmasking Strategy (DUS), an inference-only, planner-model-free method that requires no additional training. DUS leverages a first-order Markov assumption to partition sequence positions into dilation-based groups of non-adjacent tokens, enabling independent, parallel unmasking steps that respect local context that minimizes the joint entropy of each iteration step. Unlike semi-AR block approaches (e.g., LLADA and Dream) that still invoke the denoiser per block, DUS reduces the number of denoiser calls to O(log B) per generation block - yielding substantial speedup over the O(B) run time of state-of-the-art diffusion models, where B is the block size in the semi-AR inference process. In experiments on math (GSM8K) and code completion (Humaneval, MBPP) benchmarks - domains suited to non-ordinal generation - DUS improves scores over parallel confidence-based planner, without modifying the underlying denoiser. DUS offers a lightweight, budget-aware approach to efficient, high-quality text generation, paving the way to unlock the true capabilities of MDLMs.
Toward Optimal ANC: Establishing Mutual Information Lower Bound
May 23, 2025Active Noise Cancellation (ANC) algorithms aim to suppress unwanted acoustic disturbances by generating anti-noise signals that destructively interfere with the original noise in real time. Although recent deep learning-based ANC algorithms have set new performance benchmarks, there remains a shortage of theoretical limits to rigorously assess their improvements. To address this, we derive a unified lower bound on cancellation performance composed of two components. The first component is information-theoretic: it links residual error power to the fraction of disturbance entropy captured by the anti-noise signal, thereby quantifying limits imposed by information-processing capacity. The second component is support-based: it measures the irreducible error arising in frequency bands that the cancellation path cannot address, reflecting fundamental physical constraints. By taking the maximum of these two terms, our bound establishes a theoretical ceiling on the Normalized Mean Squared Error (NMSE) attainable by any ANC algorithm. We validate its tightness empirically on the NOISEX dataset under varying reverberation times, demonstrating robustness across diverse acoustic conditions.
Hybrid Mamba-Transformer Decoder for Error-Correcting Codes
May 23, 2025We introduce a novel deep learning method for decoding error correction codes based on the Mamba architecture, enhanced with Transformer layers. Our approach proposes a hybrid decoder that leverages Mamba's efficient sequential modeling while maintaining the global context capabilities of Transformers. To further improve performance, we design a novel layer-wise masking strategy applied to each Mamba layer, allowing selective attention to relevant code features at different depths. Additionally, we introduce a progressive layer-wise loss, supervising the network at intermediate stages and promoting robust feature extraction throughout the decoding process. Comprehensive experiments across a range of linear codes demonstrate that our method significantly outperforms Transformer-only decoders and standard Mamba models.