 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Agent Capability Problem: Predicting Solvability Through Information-Theoretic Bounds
Dec 08, 2025When should an autonomous agent commit resources to a task? We introduce the Agent Capability Problem (ACP), a framework for predicting whether an agent can solve a problem under resource constraints. Rather than relying on empirical heuristics, ACP frames problem-solving as information acquisition: an agent requires $\Itotal$ bits to identify a solution and gains $\Istep$ bits per action at cost $\Cstep$, yielding an effective cost $\Ceff = (\Itotal/\Istep), \Cstep$ that predicts resource requirements before search. We prove that $\Ceff$ lower-bounds expected cost and provide tight probabilistic upper bounds. Experimental validation shows that ACP predictions closely track actual agent performance, consistently bounding search effort while improving efficiency over greedy and random strategies. The framework generalizes across LLM-based and agentic workflows, linking principles from active learning, Bayesian optimization, and reinforcement learning through a unified information-theoretic lens. \
Toward Optimal ANC: Establishing Mutual Information Lower Bound
May 23, 2025Active Noise Cancellation (ANC) algorithms aim to suppress unwanted acoustic disturbances by generating anti-noise signals that destructively interfere with the original noise in real time. Although recent deep learning-based ANC algorithms have set new performance benchmarks, there remains a shortage of theoretical limits to rigorously assess their improvements. To address this, we derive a unified lower bound on cancellation performance composed of two components. The first component is information-theoretic: it links residual error power to the fraction of disturbance entropy captured by the anti-noise signal, thereby quantifying limits imposed by information-processing capacity. The second component is support-based: it measures the irreducible error arising in frequency bands that the cancellation path cannot address, reflecting fundamental physical constraints. By taking the maximum of these two terms, our bound establishes a theoretical ceiling on the Normalized Mean Squared Error (NMSE) attainable by any ANC algorithm. We validate its tightness empirically on the NOISEX dataset under varying reverberation times, demonstrating robustness across diverse acoustic conditions.
Focus Your Attention (with Adaptive IIR Filters)
May 24, 2023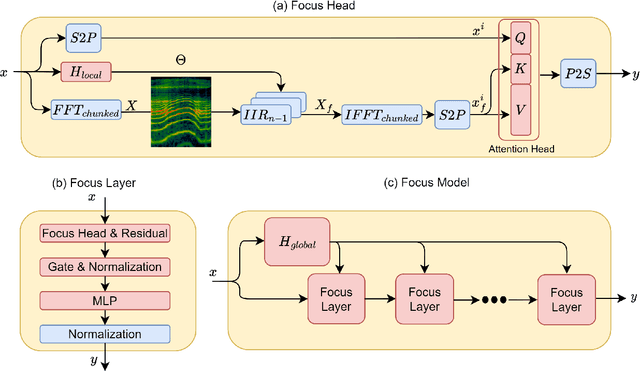
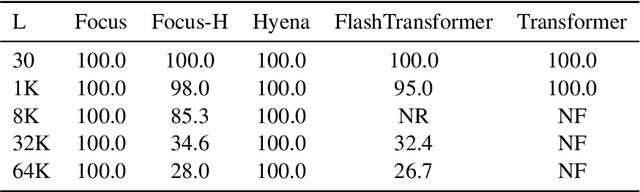
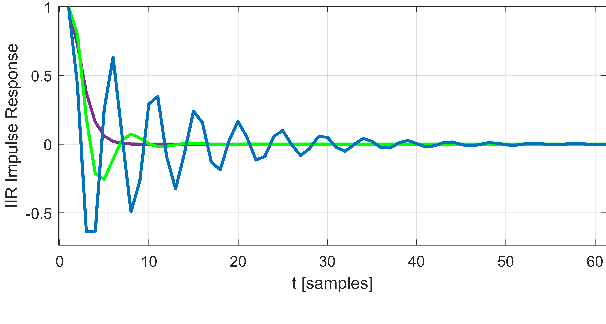

We present a new layer in which dynamic (i.e.,input-dependent) Infinite Impulse Response (IIR) filters of order two are used to process the input sequence prior to applying conventional attention. The input is split into chunks, and the coefficients of these filters are determined based on previous chunks to maintain causality. Despite their relatively low order, the causal adaptive filters are shown to focus attention on the relevant sequence elements. The layer performs on-par with state of the art networks, with a fraction of the parameters and with time complexity that is sub-quadratic with input size. The obtained layer is favorable to layers such as Heyna, GPT2, and Mega, both with respect to the number of parameters and the obtained level of performance on multiple long-range sequence problems.
Separate And Diffuse: Using a Pretrained Diffusion Model for Improving Source Separation
Jan 25, 2023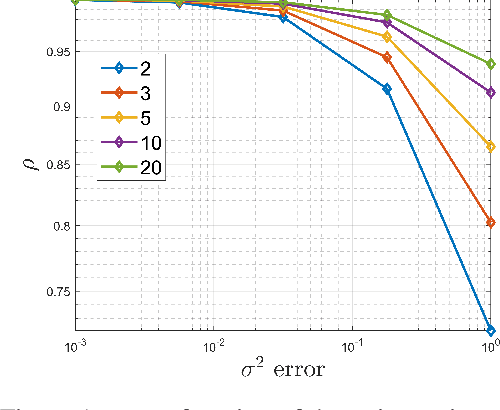
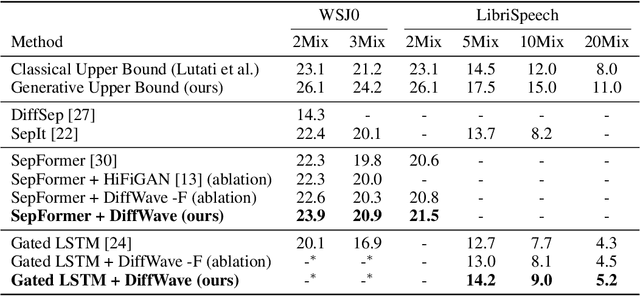

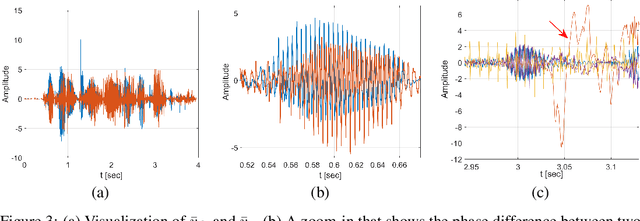
The problem of speech separation, also known as the cocktail party problem, refers to the task of isolating a single speech signal from a mixture of speech signals. Previous work on source separation derived an upper bound for the source separation task in the domain of human speech. This bound is derived for deterministic models. Recent advancements in generative models challenge this bound. We show how the upper bound can be generalized to the case of random generative models. Applying a diffusion model Vocoder that was pretrained to model single-speaker voices on the output of a deterministic separation model leads to state-of-the-art separation results. It is shown that this requires one to combine the output of the separation model with that of the diffusion model. In our method, a linear combination is performed, in the frequency domain, using weights that are inferred by a learned model. We show state-of-the-art results on 2, 3, 5, 10, and 20 speakers on multiple benchmarks. In particular, for two speakers, our method is able to surpass what was previously considered the upper performance bound.
OCD: Learning to Overfit with Conditional Diffusion Models
Oct 10, 2022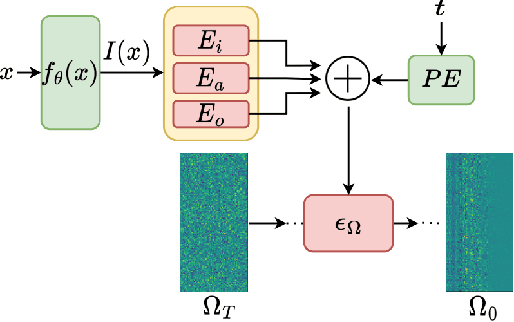
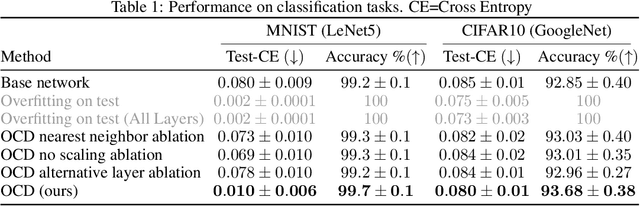
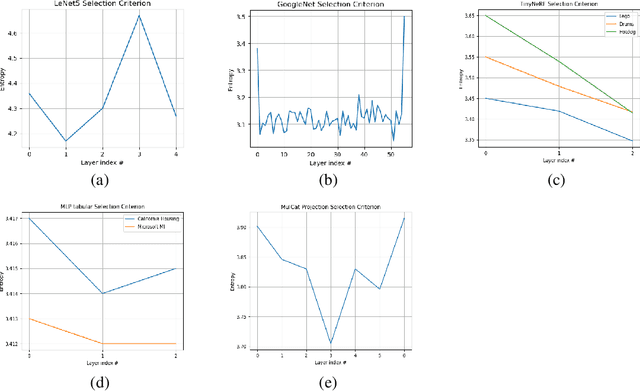
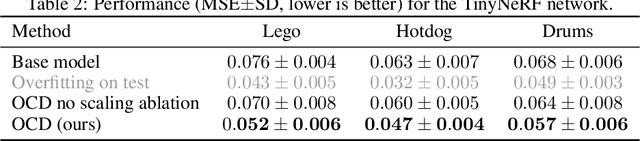
We present a dynamic model in which the weights are conditioned on an input sample x and are learned to match those that would be obtained by finetuning a base model on x and its label y. This mapping between an input sample and network weights is shown to be approximated by a linear transformation of the sample distribution, which suggests that a denoising diffusion model can be suitable for this task. The diffusion model we therefore employ focuses on modifying a single layer of the base model and is conditioned on the input, activations, and output of this layer. Our experiments demonstrate the wide applicability of the method for image classification, 3D reconstruction, tabular data, and speech separation. Our code is available at https://github.com/ShaharLutatiPersonal/OCD.
SepIt: Approaching a Single Channel Speech Separation Bound
May 25, 2022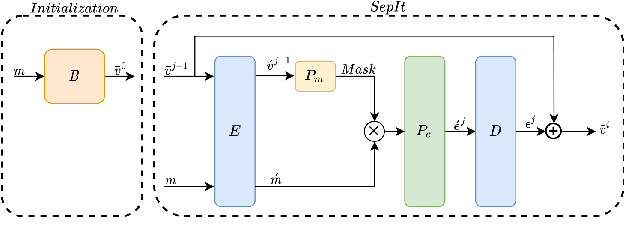
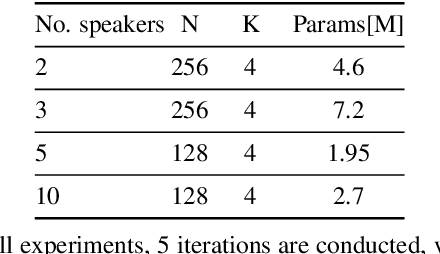
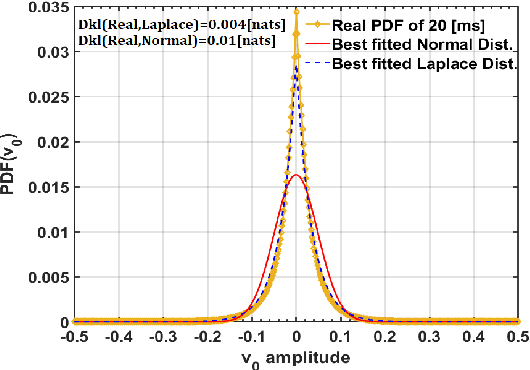
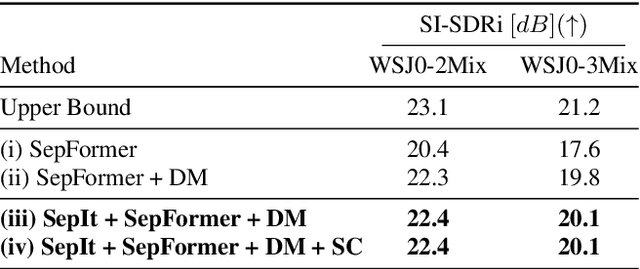
We present an upper bound for the Single Channel Speech Separation task, which is based on an assumption regarding the nature of short segments of speech. Using the bound, we are able to show that while the recent methods have made significant progress for a few speakers, there is room for improvement for five and ten speakers. We then introduce a Deep neural network, SepIt, that iteratively improves the different speakers' estimation. At test time, SpeIt has a varying number of iterations per test sample, based on a mutual information criterion that arises from our analysis. In an extensive set of experiments, SepIt outperforms the state-of-the-art neural networks for 2, 3, 5, and 10 speakers.
HyperHyperNetworks for the Design of Antenna Arrays
May 09, 2021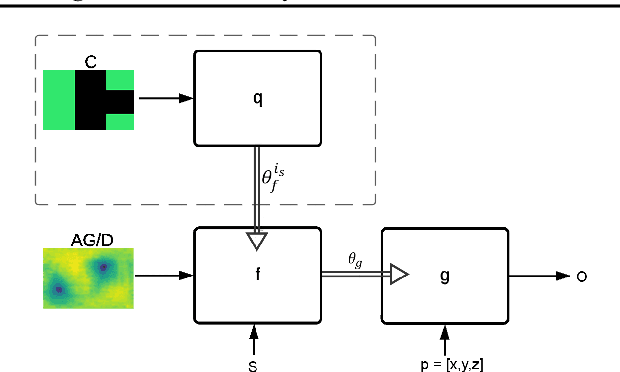
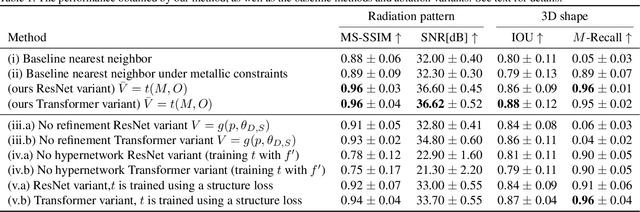
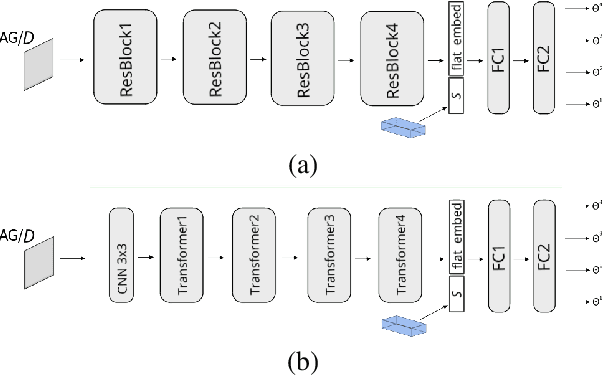

We present deep learning methods for the design of arrays and single instances of small antennas. Each design instance is conditioned on a target radiation pattern and is required to conform to specific spatial dimensions and to include, as part of its metallic structure, a set of predetermined locations. The solution, in the case of a single antenna, is based on a composite neural network that combines a simulation network, a hypernetwork, and a refinement network. In the design of the antenna array, we add an additional design level and employ a hypernetwork within a hypernetwork. The learning objective is based on measuring the similarity of the obtained radiation pattern to the desired one. Our experiments demonstrate that our approach is able to design novel antennas and antenna arrays that are compliant with the design requirements, considerably better than the baseline methods. We compare the solutions obtained by our method to existing designs and demonstrate a high level of overlap. When designing the antenna array of a cellular phone, the obtained solution displays improved properties over the existing one.