 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing the State-of-the-Art in Empirical Privacy Auditing
Jun 09, 2026Parameter-efficient fine-tuning of large language models (LLMs) can exhibit problematic memorization of individual training examples. Empirical privacy auditing (EPA) quantifies this risk by measuring realistic data leakage on membership inference (MI) or reconstruction attacks. A key challenge in EPA is designing ``canary'' examples that are mixed with the privacy-sensitive training data. We propose generating synthetic canaries via high-temperature sampling ($T \geq 0.8$) from LLMs, using prompts tailored to the privacy-sensitive training data. These canaries act as high-influence outliers, ensuring high identifiability and hence strong audits. Further, since the canaries are themselves non-private, they are inspectable and can be inserted with repetition without jeopardizing the privacy of the real data. An important use of models fine-tuned on privacy-sensitive data is the generation of synthetic data. This also comes with privacy risk. We introduce a powerful synthetic data audit based on fine-tuning an auxiliary model on the synthetic data. Auditing the auxiliary model for the original canaries then provides a strong estimate of the privacy leakage through the synthetic data. Finally, leveraging our strong auditing methodologies, we perform a systematic investigation into the interacting effects of model capacity and canary entropy on memorization.
Machine Unlearning Doesn't Do What You Think: Lessons for Generative AI Policy, Research, and Practice
Dec 09, 2024



We articulate fundamental mismatches between technical methods for machine unlearning in Generative AI, and documented aspirations for broader impact that these methods could have for law and policy. These aspirations are both numerous and varied, motivated by issues that pertain to privacy, copyright, safety, and more. For example, unlearning is often invoked as a solution for removing the effects of targeted information from a generative-AI model's parameters, e.g., a particular individual's personal data or in-copyright expression of Spiderman that was included in the model's training data. Unlearning is also proposed as a way to prevent a model from generating targeted types of information in its outputs, e.g., generations that closely resemble a particular individual's data or reflect the concept of "Spiderman." Both of these goals--the targeted removal of information from a model and the targeted suppression of information from a model's outputs--present various technical and substantive challenges. We provide a framework for thinking rigorously about these challenges, which enables us to be clear about why unlearning is not a general-purpose solution for circumscribing generative-AI model behavior in service of broader positive impact. We aim for conceptual clarity and to encourage more thoughtful communication among machine learning (ML), law, and policy experts who seek to develop and apply technical methods for compliance with policy objectives.
Fine-Tuning Large Language Models with User-Level Differential Privacy
Jul 10, 2024We investigate practical and scalable algorithms for training large language models (LLMs) with user-level differential privacy (DP) in order to provably safeguard all the examples contributed by each user. We study two variants of DP-SGD with: (1) example-level sampling (ELS) and per-example gradient clipping, and (2) user-level sampling (ULS) and per-user gradient clipping. We derive a novel user-level DP accountant that allows us to compute provably tight privacy guarantees for ELS. Using this, we show that while ELS can outperform ULS in specific settings, ULS generally yields better results when each user has a diverse collection of examples. We validate our findings through experiments in synthetic mean estimation and LLM fine-tuning tasks under fixed compute budgets. We find that ULS is significantly better in settings where either (1) strong privacy guarantees are required, or (2) the compute budget is large. Notably, our focus on LLM-compatible training algorithms allows us to scale to models with hundreds of millions of parameters and datasets with hundreds of thousands of users.
Leveraging Function Space Aggregation for Federated Learning at Scale
Nov 17, 2023
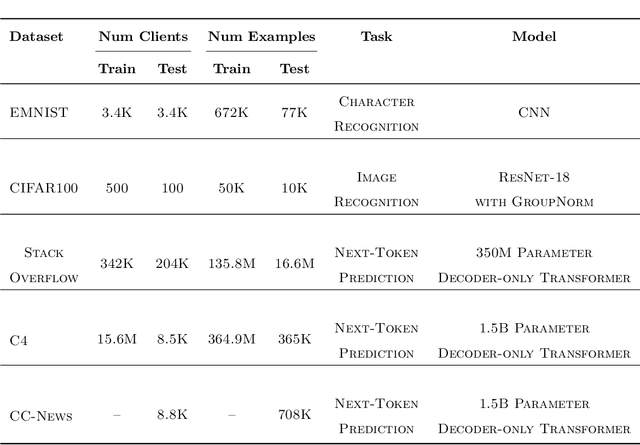
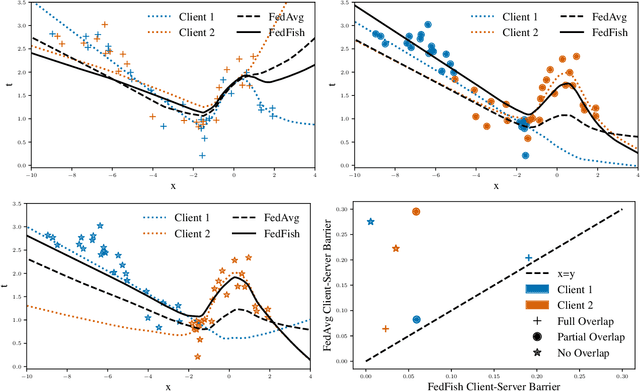
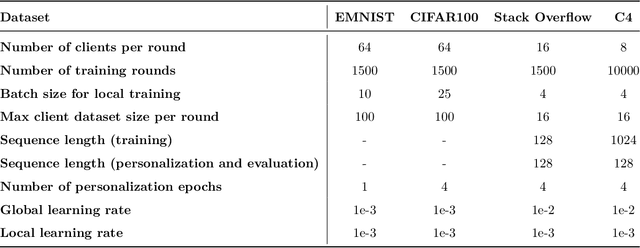
The federated learning paradigm has motivated the development of methods for aggregating multiple client updates into a global server model, without sharing client data. Many federated learning algorithms, including the canonical Federated Averaging (FedAvg), take a direct (possibly weighted) average of the client parameter updates, motivated by results in distributed optimization. In this work, we adopt a function space perspective and propose a new algorithm, FedFish, that aggregates local approximations to the functions learned by clients, using an estimate based on their Fisher information. We evaluate FedFish on realistic, large-scale cross-device benchmarks. While the performance of FedAvg can suffer as client models drift further apart, we demonstrate that FedFish is more robust to longer local training. Our evaluation across several settings in image and language benchmarks shows that FedFish outperforms FedAvg as local training epochs increase. Further, FedFish results in global networks that are more amenable to efficient personalization via local fine-tuning on the same or shifted data distributions. For instance, federated pretraining on the C4 dataset, followed by few-shot personalization on Stack Overflow, results in a 7% improvement in next-token prediction by FedFish over FedAvg.
Towards Federated Foundation Models: Scalable Dataset Pipelines for Group-Structured Learning
Jul 18, 2023We introduce a library, Dataset Grouper, to create large-scale group-structured (e.g., federated) datasets, enabling federated learning simulation at the scale of foundation models. This library allows the creation of group-structured versions of existing datasets based on user-specified partitions, and directly leads to a variety of useful heterogeneous datasets that can be plugged into existing software frameworks. Dataset Grouper offers three key advantages. First, it scales to settings where even a single group's dataset is too large to fit in memory. Second, it provides flexibility, both in choosing the base (non-partitioned) dataset and in defining partitions. Finally, it is framework-agnostic. We empirically demonstrate that Dataset Grouper allows for large-scale federated language modeling simulations on datasets that are orders of magnitude larger than in previous work. Our experimental results show that algorithms like FedAvg operate more as meta-learning methods than as empirical risk minimization methods at this scale, suggesting their utility in downstream personalization and task-specific adaptation.
JaxPruner: A concise library for sparsity research
May 02, 2023


This paper introduces JaxPruner, an open-source JAX-based pruning and sparse training library for machine learning research. JaxPruner aims to accelerate research on sparse neural networks by providing concise implementations of popular pruning and sparse training algorithms with minimal memory and latency overhead. Algorithms implemented in JaxPruner use a common API and work seamlessly with the popular optimization library Optax, which, in turn, enables easy integration with existing JAX based libraries. We demonstrate this ease of integration by providing examples in four different codebases: Scenic, t5x, Dopamine and FedJAX and provide baseline experiments on popular benchmarks.
Optimizing the Communication-Accuracy Trade-off in Federated Learning with Rate-Distortion Theory
Jan 07, 2022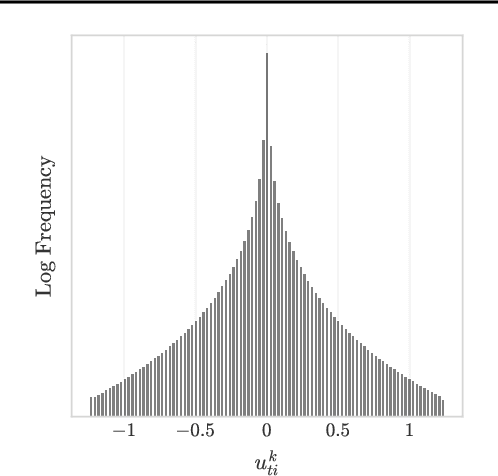

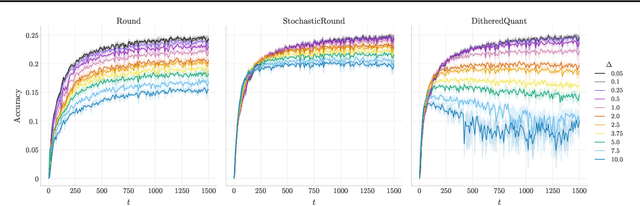
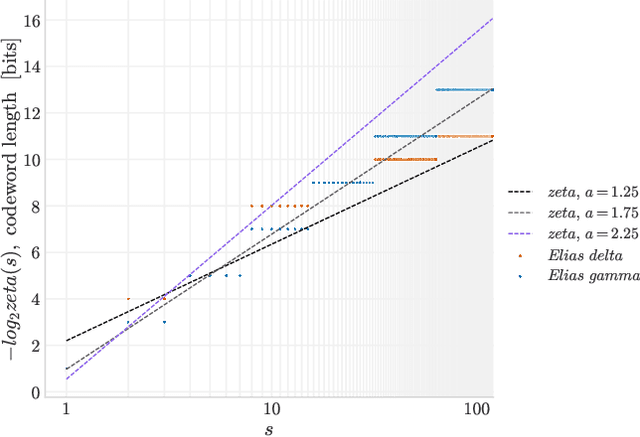
A significant bottleneck in federated learning is the network communication cost of sending model updates from client devices to the central server. We propose a method to reduce this cost. Our method encodes quantized updates with an appropriate universal code, taking into account their empirical distribution. Because quantization introduces error, we select quantization levels by optimizing for the desired trade-off in average total bitrate and gradient distortion. We demonstrate empirically that in spite of the non-i.i.d. nature of federated learning, the rate-distortion frontier is consistent across datasets, optimizers, clients and training rounds, and within each setting, distortion reliably predicts model performance. This allows for a remarkably simple compression scheme that is near-optimal in many use cases, and outperforms Top-K, DRIVE, 3LC and QSGD on the Stack Overflow next-word prediction benchmark.