 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Target Group Bias in Hate Speech Detectors
Paper and Code
Dec 07, 2021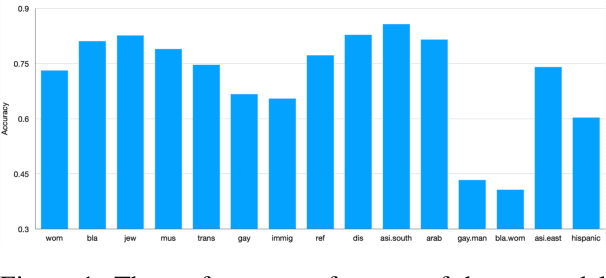
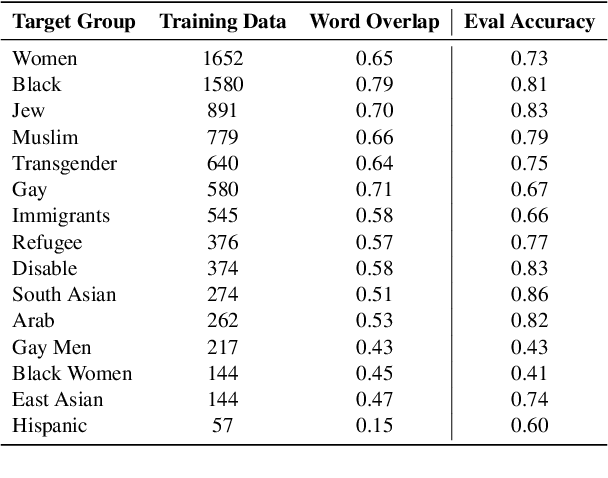
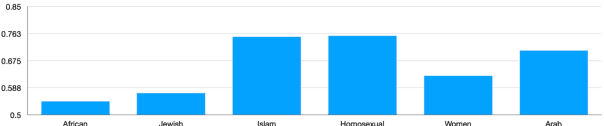
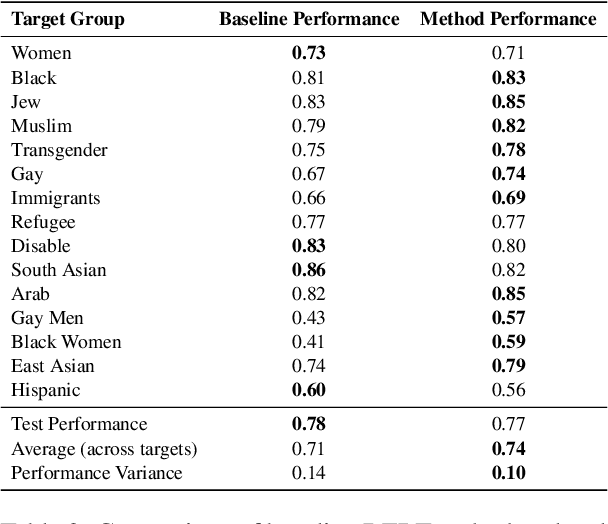
The ubiquity of offensive and hateful content on online fora necessitates the need for automatic solutions that detect such content competently across target groups. In this paper we show that text classification models trained on large publicly available datasets despite having a high overall performance, may significantly under-perform on several protected groups. On the \citet{vidgen2020learning} dataset, we find the accuracy to be 37\% lower on an under annotated Black Women target group and 12\% lower on Immigrants, where hate speech involves a distinct style. To address this, we propose to perform token-level hate sense disambiguation, and utilize tokens' hate sense representations for detection, modeling more general signals. On two publicly available datasets, we observe that the variance in model accuracy across target groups drops by at least 30\%, improving the average target group performance by 4\% and worst case performance by 13\%.