 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReNCE: Learning to Reason by Noise Contrastive Estimation
Jan 30, 2026GRPO is a standard approach to endowing pretrained LLMs with reasoning capabilities. It estimates the advantage of an outcome from a group of $K$ outcomes, and promotes those with positive advantages inside a trust region. Since GRPO discriminates between good and bad outcomes softly, it benefits from additional refinements such as asymmetric clipping and zero-variance data filtering. While effective, these refinements require significant empirical insight and can be challenging to identify. We instead propose an explicit contrastive learning approach. Instead of estimating advantages, we bifurcate $K$ outcomes into positive and negative sets, then maximize the likelihood of positive outcomes. Our approach can be viewed as an online instantiation of (multi-label) noise contrastive estimation for LLM reasoning. We validate our method by demonstrating competitive performance on a suite of challenging math benchmarks against strong baselines such as DAPO and online DPO.
Essential-Web v1.0: 24T tokens of organized web data
Jun 17, 2025
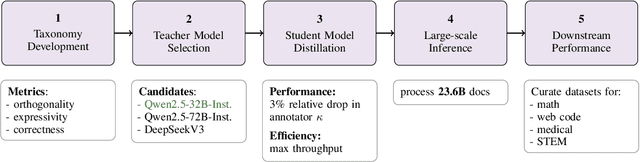

Data plays the most prominent role in how language models acquire skills and knowledge. The lack of massive, well-organized pre-training datasets results in costly and inaccessible data pipelines. We present Essential-Web v1.0, a 24-trillion-token dataset in which every document is annotated with a twelve-category taxonomy covering topic, format, content complexity, and quality. Taxonomy labels are produced by EAI-Distill-0.5b, a fine-tuned 0.5b-parameter model that achieves an annotator agreement within 3% of Qwen2.5-32B-Instruct. With nothing more than SQL-style filters, we obtain competitive web-curated datasets in math (-8.0% relative to SOTA), web code (+14.3%), STEM (+24.5%) and medical (+8.6%). Essential-Web v1.0 is available on HuggingFace: https://huggingface.co/datasets/EssentialAI/essential-web-v1.0
Practical Efficiency of Muon for Pretraining
May 04, 2025We demonstrate that Muon, the simplest instantiation of a second-order optimizer, explicitly expands the Pareto frontier over AdamW on the compute-time tradeoff. We find that Muon is more effective than AdamW in retaining data efficiency at large batch sizes, far beyond the so-called critical batch size, while remaining computationally efficient, thus enabling more economical training. We study the combination of Muon and the maximal update parameterization (muP) for efficient hyperparameter transfer and present a simple telescoping algorithm that accounts for all sources of error in muP while introducing only a modest overhead in resources. We validate our findings through extensive experiments with model sizes up to four billion parameters and ablations on the data distribution and architecture.
Rethinking Reflection in Pre-Training
Apr 05, 2025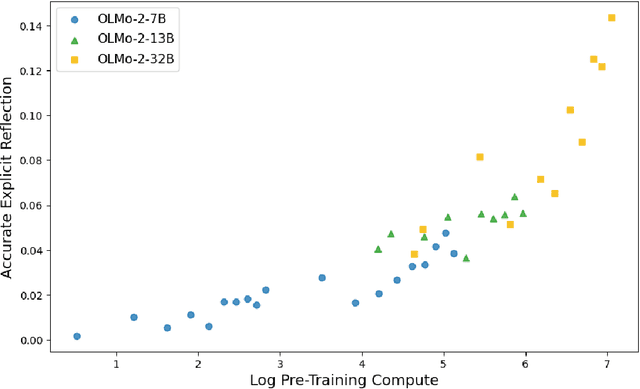
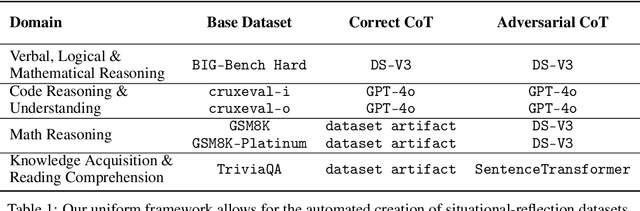
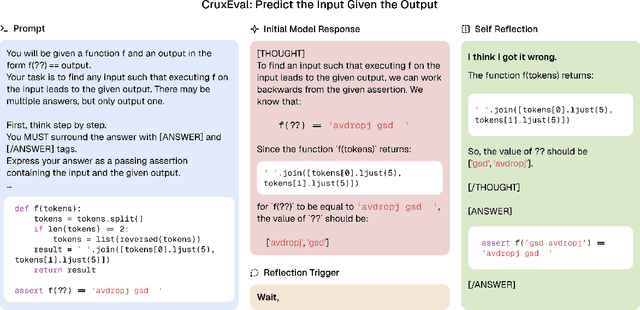
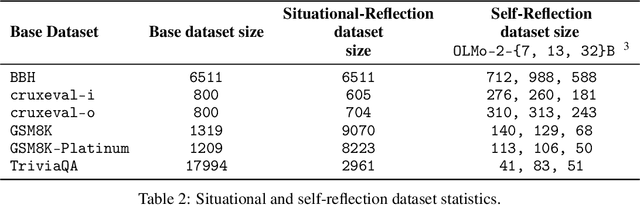
A language model's ability to reflect on its own reasoning provides a key advantage for solving complex problems. While most recent research has focused on how this ability develops during reinforcement learning, we show that it actually begins to emerge much earlier - during the model's pre-training. To study this, we introduce deliberate errors into chains-of-thought and test whether the model can still arrive at the correct answer by recognizing and correcting these mistakes. By tracking performance across different stages of pre-training, we observe that this self-correcting ability appears early and improves steadily over time. For instance, an OLMo2-7B model pre-trained on 4 trillion tokens displays self-correction on our six self-reflection tasks.
The Impact of Visual Information in Chinese Characters: Evaluating Large Models' Ability to Recognize and Utilize Radicals
Oct 11, 2024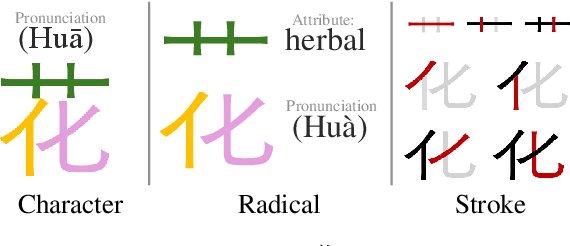
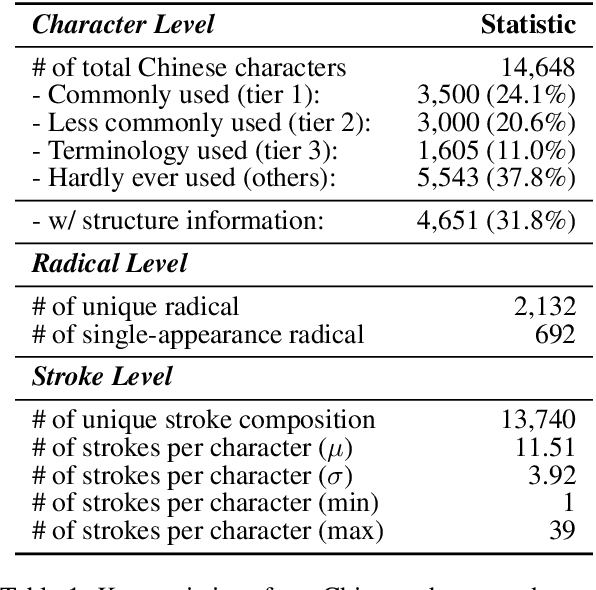

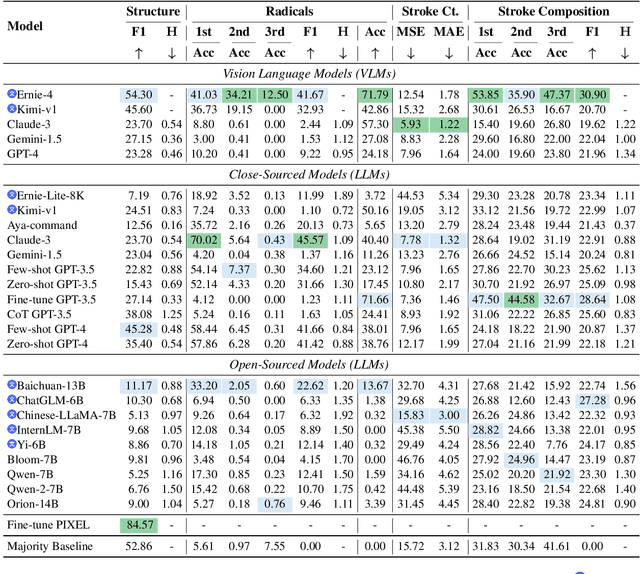
The glyphic writing system of Chinese incorporates information-rich visual features in each character, such as radicals that provide hints about meaning or pronunciation. However, there has been no investigation into whether contemporary Large Language Models (LLMs) and Vision-Language Models (VLMs) can harness these sub-character features in Chinese through prompting. In this study, we establish a benchmark to evaluate LLMs' and VLMs' understanding of visual elements in Chinese characters, including radicals, composition structures, strokes, and stroke counts. Our results reveal that models surprisingly exhibit some, but still limited, knowledge of the visual information, regardless of whether images of characters are provided. To incite models' ability to use radicals, we further experiment with incorporating radicals into the prompts for Chinese language understanding tasks. We observe consistent improvement in Part-Of-Speech tagging when providing additional information about radicals, suggesting the potential to enhance CLP by integrating sub-character information.
Model Editing by Pure Fine-Tuning
Feb 16, 2024Fine-tuning is dismissed as not effective for model editing due to its poor performance compared to more specialized methods. However, fine-tuning is simple, agnostic to the architectural details of the model being edited, and able to leverage ongoing advances in standard training methods (e.g., PEFT), making it an appealing choice for a model editor. In this work, we show that pure fine-tuning can be a viable approach to model editing. We propose a slight modification of naive fine-tuning with two key ingredients. First, we optimize the conditional likelihood rather than the full likelihood. Second, we augment the data with random paraphrases and facts to encourage generalization and locality. Our experiments on ZsRE and CounterFact show that this simple modification allows fine-tuning to often match or outperform specialized editors in the edit score.
Seq2seq is All You Need for Coreference Resolution
Oct 20, 2023

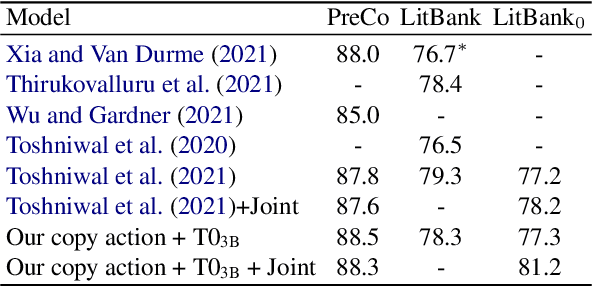
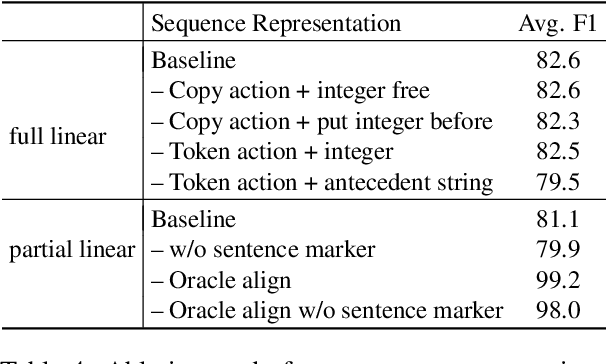
Existing works on coreference resolution suggest that task-specific models are necessary to achieve state-of-the-art performance. In this work, we present compelling evidence that such models are not necessary. We finetune a pretrained seq2seq transformer to map an input document to a tagged sequence encoding the coreference annotation. Despite the extreme simplicity, our model outperforms or closely matches the best coreference systems in the literature on an array of datasets. We also propose an especially simple seq2seq approach that generates only tagged spans rather than the spans interleaved with the original text. Our analysis shows that the model size, the amount of supervision, and the choice of sequence representations are key factors in performance.
Improving Multitask Retrieval by Promoting Task Specialization
Jul 01, 2023In multitask retrieval, a single retriever is trained to retrieve relevant contexts for multiple tasks. Despite its practical appeal, naive multitask retrieval lags behind task-specific retrieval in which a separate retriever is trained for each task. We show that it is possible to train a multitask retriever that outperforms task-specific retrievers by promoting task specialization. The main ingredients are: (1) a better choice of pretrained model (one that is explicitly optimized for multitasking) along with compatible prompting, and (2) a novel adaptive learning method that encourages each parameter to specialize in a particular task. The resulting multitask retriever is highly performant on the KILT benchmark. Upon analysis, we find that the model indeed learns parameters that are more task-specialized compared to naive multitasking without prompting or adaptive learning.
EntQA: Entity Linking as Question Answering
Oct 05, 2021
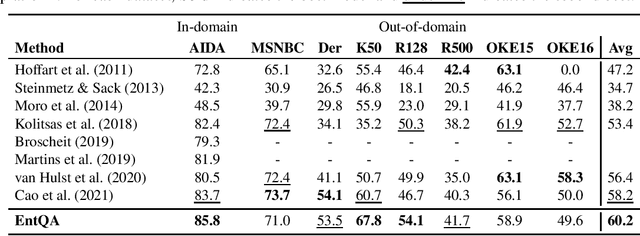


A conventional approach to entity linking is to first find mentions in a given document and then infer their underlying entities in the knowledge base. A well-known limitation of this approach is that it requires finding mentions without knowing their entities, which is unnatural and difficult. We present a new model that does not suffer from this limitation called EntQA, which stands for Entity linking as Question Answering. EntQA first proposes candidate entities with a fast retrieval module, and then scrutinizes the document to find mentions of each candidate with a powerful reader module. Our approach combines progress in entity linking with that in open-domain question answering and capitalizes on pretrained models for dense entity retrieval and reading comprehension. Unlike in previous works, we do not rely on a mention-candidates dictionary or large-scale weak supervision. EntQA achieves strong results on the GERBIL benchmarking platform.
Understanding Hard Negatives in Noise Contrastive Estimation
Apr 13, 2021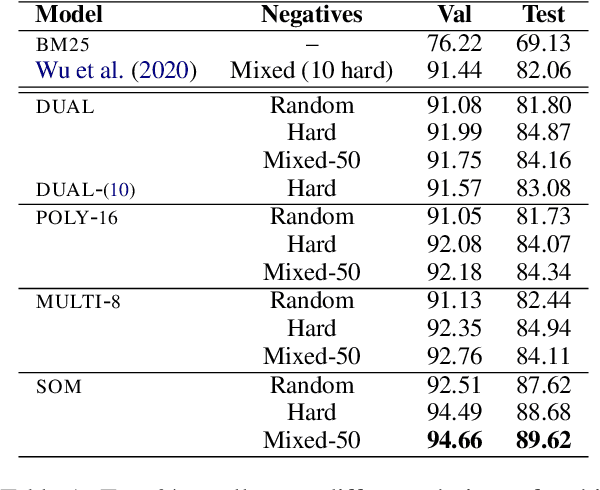
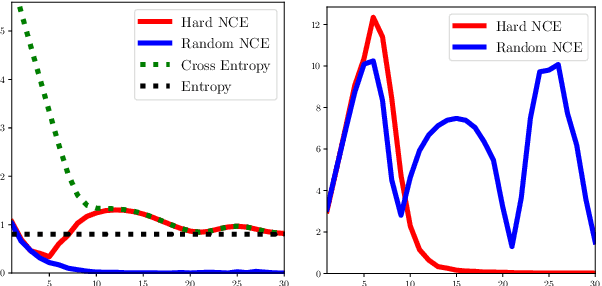
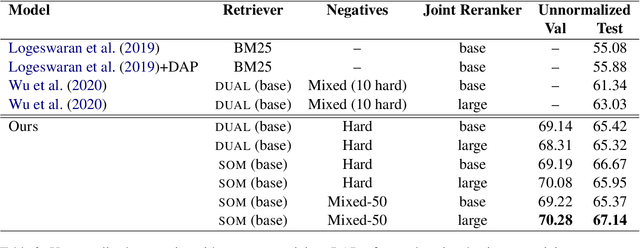

The choice of negative examples is important in noise contrastive estimation. Recent works find that hard negatives -- highest-scoring incorrect examples under the model -- are effective in practice, but they are used without a formal justification. We develop analytical tools to understand the role of hard negatives. Specifically, we view the contrastive loss as a biased estimator of the gradient of the cross-entropy loss, and show both theoretically and empirically that setting the negative distribution to be the model distribution results in bias reduction. We also derive a general form of the score function that unifies various architectures used in text retrieval. By combining hard negatives with appropriate score functions, we obtain strong results on the challenging task of zero-shot entity linking.