 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of Visual Information in Chinese Characters: Evaluating Large Models' Ability to Recognize and Utilize Radicals
Paper and Code
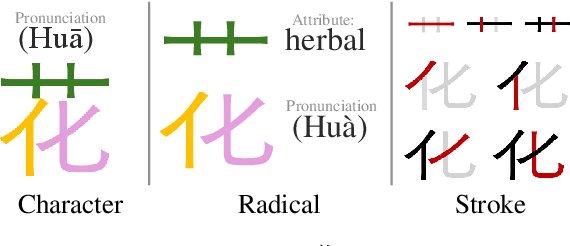
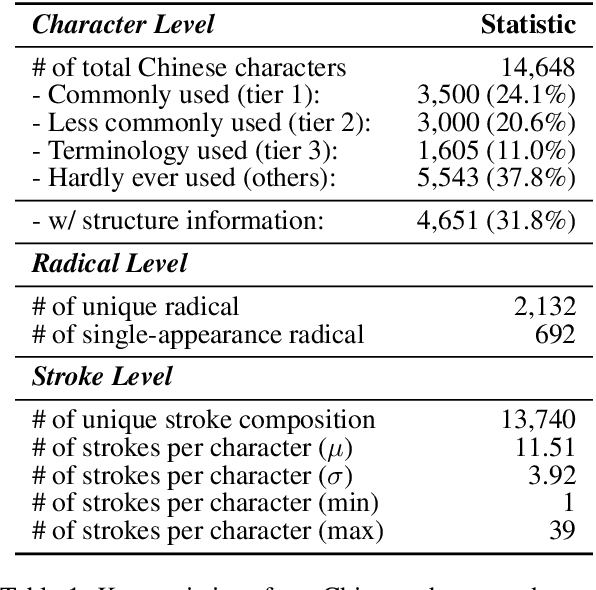

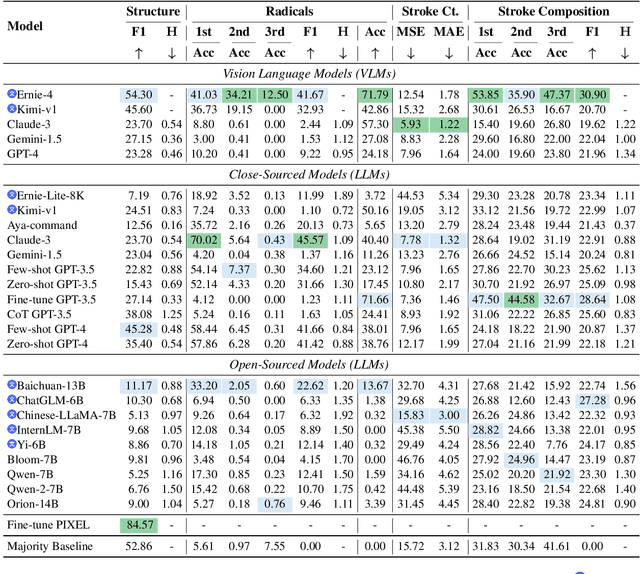
The glyphic writing system of Chinese incorporates information-rich visual features in each character, such as radicals that provide hints about meaning or pronunciation. However, there has been no investigation into whether contemporary Large Language Models (LLMs) and Vision-Language Models (VLMs) can harness these sub-character features in Chinese through prompting. In this study, we establish a benchmark to evaluate LLMs' and VLMs' understanding of visual elements in Chinese characters, including radicals, composition structures, strokes, and stroke counts. Our results reveal that models surprisingly exhibit some, but still limited, knowledge of the visual information, regardless of whether images of characters are provided. To incite models' ability to use radicals, we further experiment with incorporating radicals into the prompts for Chinese language understanding tasks. We observe consistent improvement in Part-Of-Speech tagging when providing additional information about radicals, suggesting the potential to enhance CLP by integrating sub-character information.