 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact and Outlook of 3D Gaussian Splatting
Oct 30, 2025Since its introduction, 3D Gaussian Splatting (3DGS) has rapidly transformed the landscape of 3D scene representations, inspiring an extensive body of associated research. Follow-up work includes analyses and contributions that enhance the efficiency, scalability, and real-world applicability of 3DGS. In this summary, we present an overview of several key directions that have emerged in the wake of 3DGS. We highlight advances enabling resource-efficient training and rendering, the evolution toward dynamic (or four-dimensional, 4DGS) representations, and deeper exploration of the mathematical foundations underlying its appearance modeling and rendering process. Furthermore, we examine efforts to bring 3DGS to mobile and virtual reality platforms, its extension to massive-scale environments, and recent progress toward near-instant radiance field reconstruction via feed-forward or distributed computation. Collectively, these developments illustrate how 3DGS has evolved from a breakthrough representation into a versatile and foundational tool for 3D vision and graphics.
On-the-fly Reconstruction for Large-Scale Novel View Synthesis from Unposed Images
Jun 05, 2025
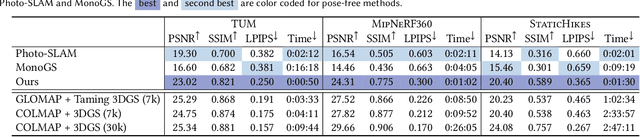


Radiance field methods such as 3D Gaussian Splatting (3DGS) allow easy reconstruction from photos, enabling free-viewpoint navigation. Nonetheless, pose estimation using Structure from Motion and 3DGS optimization can still each take between minutes and hours of computation after capture is complete. SLAM methods combined with 3DGS are fast but struggle with wide camera baselines and large scenes. We present an on-the-fly method to produce camera poses and a trained 3DGS immediately after capture. Our method can handle dense and wide-baseline captures of ordered photo sequences and large-scale scenes. To do this, we first introduce fast initial pose estimation, exploiting learned features and a GPU-friendly mini bundle adjustment. We then introduce direct sampling of Gaussian primitive positions and shapes, incrementally spawning primitives where required, significantly accelerating training. These two efficient steps allow fast and robust joint optimization of poses and Gaussian primitives. Our incremental approach handles large-scale scenes by introducing scalable radiance field construction, progressively clustering 3DGS primitives, storing them in anchors, and offloading them from the GPU. Clustered primitives are progressively merged, keeping the required scale of 3DGS at any viewpoint. We evaluate our solution on a variety of datasets and show that our solution can provide on-the-fly processing of all the capture scenarios and scene sizes we target while remaining competitive with other methods that only handle specific capture styles or scene sizes in speed, image quality, or both.
VRSplat: Fast and Robust Gaussian Splatting for Virtual Reality
May 15, 2025



3D Gaussian Splatting (3DGS) has rapidly become a leading technique for novel-view synthesis, providing exceptional performance through efficient software-based GPU rasterization. Its versatility enables real-time applications, including on mobile and lower-powered devices. However, 3DGS faces key challenges in virtual reality (VR): (1) temporal artifacts, such as popping during head movements, (2) projection-based distortions that result in disturbing and view-inconsistent floaters, and (3) reduced framerates when rendering large numbers of Gaussians, falling below the critical threshold for VR. Compared to desktop environments, these issues are drastically amplified by large field-of-view, constant head movements, and high resolution of head-mounted displays (HMDs). In this work, we introduce VRSplat: we combine and extend several recent advancements in 3DGS to address challenges of VR holistically. We show how the ideas of Mini-Splatting, StopThePop, and Optimal Projection can complement each other, by modifying the individual techniques and core 3DGS rasterizer. Additionally, we propose an efficient foveated rasterizer that handles focus and peripheral areas in a single GPU launch, avoiding redundant computations and improving GPU utilization. Our method also incorporates a fine-tuning step that optimizes Gaussian parameters based on StopThePop depth evaluations and Optimal Projection. We validate our method through a controlled user study with 25 participants, showing a strong preference for VRSplat over other configurations of Mini-Splatting. VRSplat is the first, systematically evaluated 3DGS approach capable of supporting modern VR applications, achieving 72+ FPS while eliminating popping and stereo-disrupting floaters.
* I3D'25 (PACMCGIT); Project Page: https://cekavis.site/VRSplat/
Does 3D Gaussian Splatting Need Accurate Volumetric Rendering?
Feb 26, 2025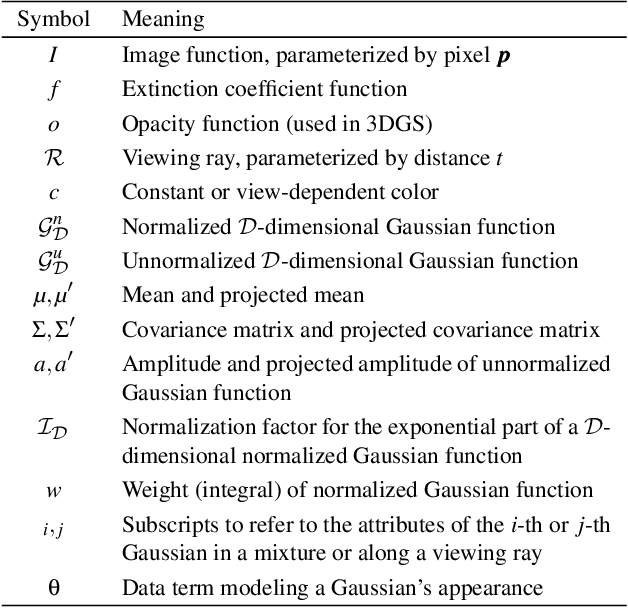
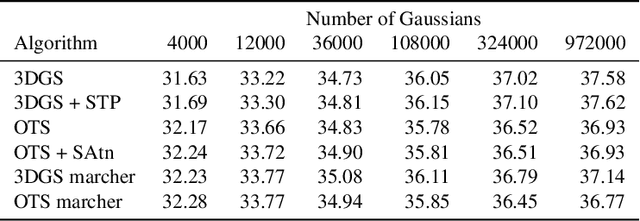
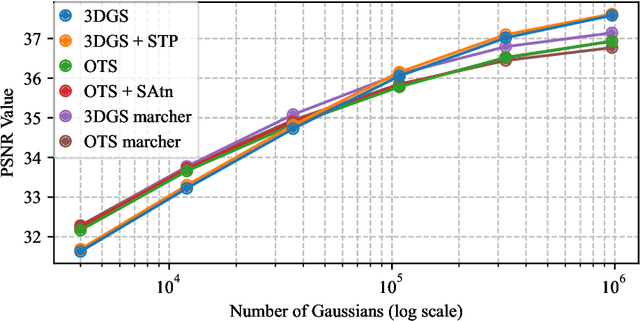
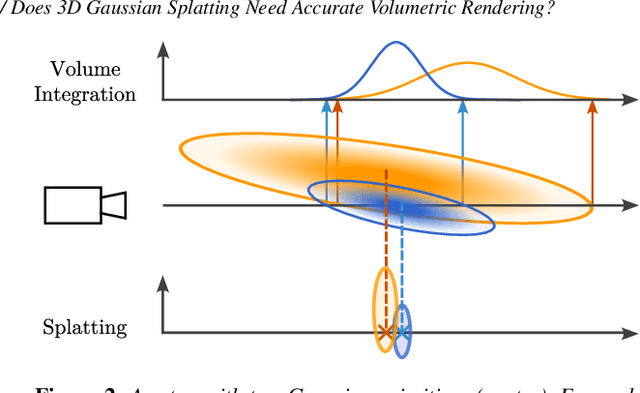
Since its introduction, 3D Gaussian Splatting (3DGS) has become an important reference method for learning 3D representations of a captured scene, allowing real-time novel-view synthesis with high visual quality and fast training times. Neural Radiance Fields (NeRFs), which preceded 3DGS, are based on a principled ray-marching approach for volumetric rendering. In contrast, while sharing a similar image formation model with NeRF, 3DGS uses a hybrid rendering solution that builds on the strengths of volume rendering and primitive rasterization. A crucial benefit of 3DGS is its performance, achieved through a set of approximations, in many cases with respect to volumetric rendering theory. A naturally arising question is whether replacing these approximations with more principled volumetric rendering solutions can improve the quality of 3DGS. In this paper, we present an in-depth analysis of the various approximations and assumptions used by the original 3DGS solution. We demonstrate that, while more accurate volumetric rendering can help for low numbers of primitives, the power of efficient optimization and the large number of Gaussians allows 3DGS to outperform volumetric rendering despite its approximations.
Reducing the Memory Footprint of 3D Gaussian Splatting
Jun 24, 20243D Gaussian splatting provides excellent visual quality for novel view synthesis, with fast training and real-time rendering; unfortunately, the memory requirements of this method for storing and transmission are unreasonably high. We first analyze the reasons for this, identifying three main areas where storage can be reduced: the number of 3D Gaussian primitives used to represent a scene, the number of coefficients for the spherical harmonics used to represent directional radiance, and the precision required to store Gaussian primitive attributes. We present a solution to each of these issues. First, we propose an efficient, resolution-aware primitive pruning approach, reducing the primitive count by half. Second, we introduce an adaptive adjustment method to choose the number of coefficients used to represent directional radiance for each Gaussian primitive, and finally a codebook-based quantization method, together with a half-float representation for further memory reduction. Taken together, these three components result in a 27 reduction in overall size on disk on the standard datasets we tested, along with a 1.7 speedup in rendering speed. We demonstrate our method on standard datasets and show how our solution results in significantly reduced download times when using the method on a mobile device.
* Project website: https://repo-sam.inria.fr/fungraph/reduced_3dgs/
Taming 3DGS: High-Quality Radiance Fields with Limited Resources
Jun 21, 2024
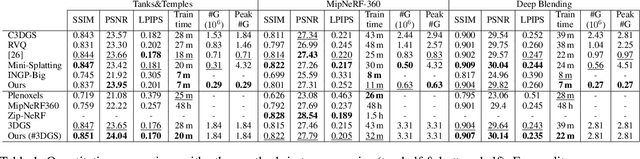
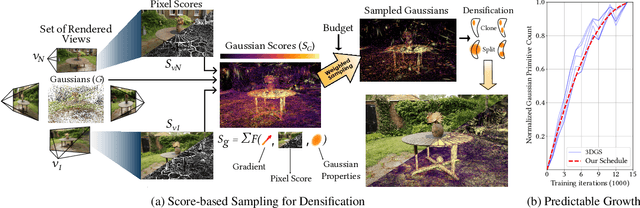
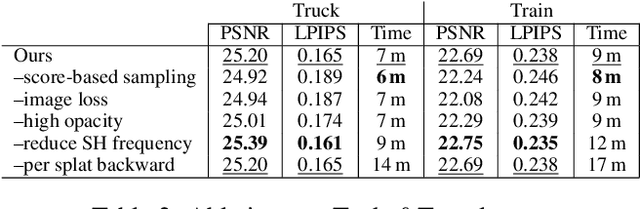
3D Gaussian Splatting (3DGS) has transformed novel-view synthesis with its fast, interpretable, and high-fidelity rendering. However, its resource requirements limit its usability. Especially on constrained devices, training performance degrades quickly and often cannot complete due to excessive memory consumption of the model. The method converges with an indefinite number of Gaussians -- many of them redundant -- making rendering unnecessarily slow and preventing its usage in downstream tasks that expect fixed-size inputs. To address these issues, we tackle the challenges of training and rendering 3DGS models on a budget. We use a guided, purely constructive densification process that steers densification toward Gaussians that raise the reconstruction quality. Model size continuously increases in a controlled manner towards an exact budget, using score-based densification of Gaussians with training-time priors that measure their contribution. We further address training speed obstacles: following a careful analysis of 3DGS' original pipeline, we derive faster, numerically equivalent solutions for gradient computation and attribute updates, including an alternative parallelization for efficient backpropagation. We also propose quality-preserving approximations where suitable to reduce training time even further. Taken together, these enhancements yield a robust, scalable solution with reduced training times, lower compute and memory requirements, and high quality. Our evaluation shows that in a budgeted setting, we obtain competitive quality metrics with 3DGS while achieving a 4--5x reduction in both model size and training time. With more generous budgets, our measured quality surpasses theirs. These advances open the door for novel-view synthesis in constrained environments, e.g., mobile devices.
A Hierarchical 3D Gaussian Representation for Real-Time Rendering of Very Large Datasets
Jun 17, 2024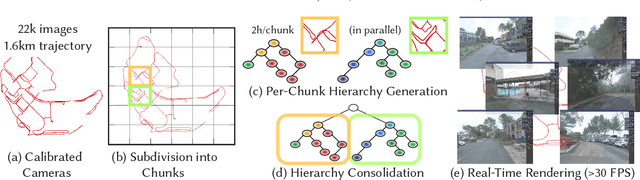
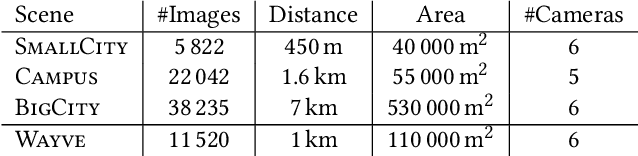
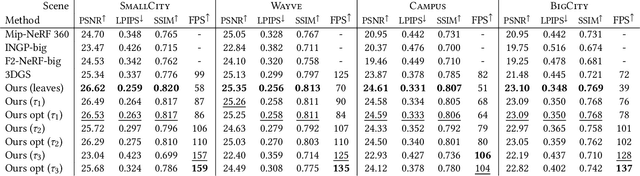
Novel view synthesis has seen major advances in recent years, with 3D Gaussian splatting offering an excellent level of visual quality, fast training and real-time rendering. However, the resources needed for training and rendering inevitably limit the size of the captured scenes that can be represented with good visual quality. We introduce a hierarchy of 3D Gaussians that preserves visual quality for very large scenes, while offering an efficient Level-of-Detail (LOD) solution for efficient rendering of distant content with effective level selection and smooth transitions between levels.We introduce a divide-and-conquer approach that allows us to train very large scenes in independent chunks. We consolidate the chunks into a hierarchy that can be optimized to further improve visual quality of Gaussians merged into intermediate nodes. Very large captures typically have sparse coverage of the scene, presenting many challenges to the original 3D Gaussian splatting training method; we adapt and regularize training to account for these issues. We present a complete solution, that enables real-time rendering of very large scenes and can adapt to available resources thanks to our LOD method. We show results for captured scenes with up to tens of thousands of images with a simple and affordable rig, covering trajectories of up to several kilometers and lasting up to one hour. Project Page: https://repo-sam.inria.fr/fungraph/hierarchical-3d-gaussians/
* Project Page: https://repo-sam.inria.fr/fungraph/hierarchical-3d-gaussians/
Cinematic Gaussians: Real-Time HDR Radiance Fields with Depth of Field
Jun 11, 2024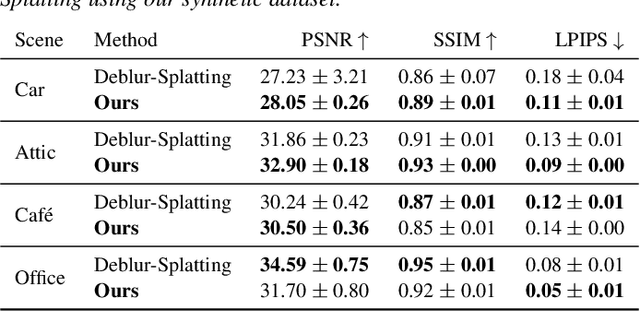

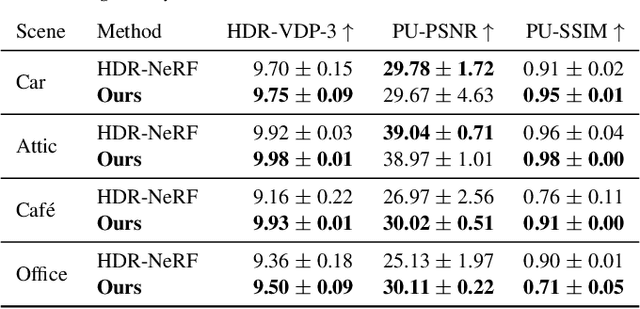

Radiance field methods represent the state of the art in reconstructing complex scenes from multi-view photos. However, these reconstructions often suffer from one or both of the following limitations: First, they typically represent scenes in low dynamic range (LDR), which restricts their use to evenly lit environments and hinders immersive viewing experiences. Secondly, their reliance on a pinhole camera model, assuming all scene elements are in focus in the input images, presents practical challenges and complicates refocusing during novel-view synthesis. Addressing these limitations, we present a lightweight method based on 3D Gaussian Splatting that utilizes multi-view LDR images of a scene with varying exposure times, apertures, and focus distances as input to reconstruct a high-dynamic-range (HDR) radiance field. By incorporating analytical convolutions of Gaussians based on a thin-lens camera model as well as a tonemapping module, our reconstructions enable the rendering of HDR content with flexible refocusing capabilities. We demonstrate that our combined treatment of HDR and depth of field facilitates real-time cinematic rendering, outperforming the state of the art.
StopThePop: Sorted Gaussian Splatting for View-Consistent Real-time Rendering
Feb 01, 2024


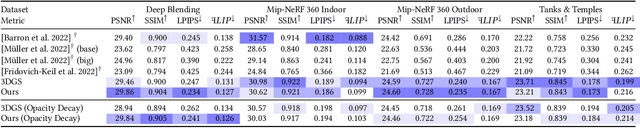
Gaussian Splatting has emerged as a prominent model for constructing 3D representations from images across diverse domains. However, the efficiency of the 3D Gaussian Splatting rendering pipeline relies on several simplifications. Notably, reducing Gaussian to 2D splats with a single view-space depth introduces popping and blending artifacts during view rotation. Addressing this issue requires accurate per-pixel depth computation, yet a full per-pixel sort proves excessively costly compared to a global sort operation. In this paper, we present a novel hierarchical rasterization approach that systematically resorts and culls splats with minimal processing overhead. Our software rasterizer effectively eliminates popping artifacts and view inconsistencies, as demonstrated through both quantitative and qualitative measurements. Simultaneously, our method mitigates the potential for cheating view-dependent effects with popping, ensuring a more authentic representation. Despite the elimination of cheating, our approach achieves comparable quantitative results for test images, while increasing the consistency for novel view synthesis in motion. Due to its design, our hierarchical approach is only 4% slower on average than the original Gaussian Splatting. Notably, enforcing consistency enables a reduction in the number of Gaussians by approximately half with nearly identical quality and view-consistency. Consequently, rendering performance is nearly doubled, making our approach 1.6x faster than the original Gaussian Splatting, with a 50% reduction in memory requirements.
Training and Predicting Visual Error for Real-Time Applications
Oct 13, 2023Visual error metrics play a fundamental role in the quantification of perceived image similarity. Most recently, use cases for them in real-time applications have emerged, such as content-adaptive shading and shading reuse to increase performance and improve efficiency. A wide range of different metrics has been established, with the most sophisticated being capable of capturing the perceptual characteristics of the human visual system. However, their complexity, computational expense, and reliance on reference images to compare against prevent their generalized use in real-time, restricting such applications to using only the simplest available metrics. In this work, we explore the abilities of convolutional neural networks to predict a variety of visual metrics without requiring either reference or rendered images. Specifically, we train and deploy a neural network to estimate the visual error resulting from reusing shading or using reduced shading rates. The resulting models account for 70%-90% of the variance while achieving up to an order of magnitude faster computation times. Our solution combines image-space information that is readily available in most state-of-the-art deferred shading pipelines with reprojection from previous frames to enable an adequate estimate of visual errors, even in previously unseen regions. We describe a suitable convolutional network architecture and considerations for data preparation for training. We demonstrate the capability of our network to predict complex error metrics at interactive rates in a real-time application that implements content-adaptive shading in a deferred pipeline. Depending on the portion of unseen image regions, our approach can achieve up to $2\times$ performance compared to state-of-the-art methods.
* Published at Proceedings of the ACM in Computer Graphics and Interactive Techniques. 14 Pages, 16 Figures, 3 Tables. For paper website and higher quality figures, see https://jaliborc.github.io/rt-percept/