 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence-Based Mesh Extraction from 3D Gaussians
Mar 25, 2026Recently, 3D Gaussian Splatting (3DGS) greatly accelerated mesh extraction from posed images due to its explicit representation and fast software rasterization. While the addition of geometric losses and other priors has improved the accuracy of extracted surfaces, mesh extraction remains difficult in scenes with abundant view-dependent effects. To resolve the resulting ambiguities, prior works rely on multi-view techniques, iterative mesh extraction, or large pre-trained models, sacrificing the inherent efficiency of 3DGS. In this work, we present a simple and efficient alternative by introducing a self-supervised confidence framework to 3DGS: within this framework, learnable confidence values dynamically balance photometric and geometric supervision. Extending our confidence-driven formulation, we introduce losses which penalize per-primitive color and normal variance and demonstrate their benefits to surface extraction. Finally, we complement the above with an improved appearance model, by decoupling the individual terms of the D-SSIM loss. Our final approach delivers state-of-the-art results for unbounded meshes while remaining highly efficient.
A LoD of Gaussians: Unified Training and Rendering for Ultra-Large Scale Reconstruction with External Memory
Jul 01, 2025


Gaussian Splatting has emerged as a high-performance technique for novel view synthesis, enabling real-time rendering and high-quality reconstruction of small scenes. However, scaling to larger environments has so far relied on partitioning the scene into chunks -- a strategy that introduces artifacts at chunk boundaries, complicates training across varying scales, and is poorly suited to unstructured scenarios such as city-scale flyovers combined with street-level views. Moreover, rendering remains fundamentally limited by GPU memory, as all visible chunks must reside in VRAM simultaneously. We introduce A LoD of Gaussians, a framework for training and rendering ultra-large-scale Gaussian scenes on a single consumer-grade GPU -- without partitioning. Our method stores the full scene out-of-core (e.g., in CPU memory) and trains a Level-of-Detail (LoD) representation directly, dynamically streaming only the relevant Gaussians. A hybrid data structure combining Gaussian hierarchies with Sequential Point Trees enables efficient, view-dependent LoD selection, while a lightweight caching and view scheduling system exploits temporal coherence to support real-time streaming and rendering. Together, these innovations enable seamless multi-scale reconstruction and interactive visualization of complex scenes -- from broad aerial views to fine-grained ground-level details.
SOF: Sorted Opacity Fields for Fast Unbounded Surface Reconstruction
Jun 23, 2025
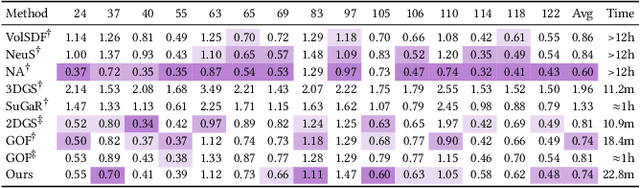
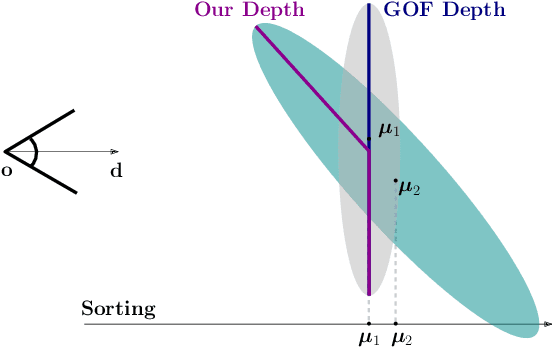
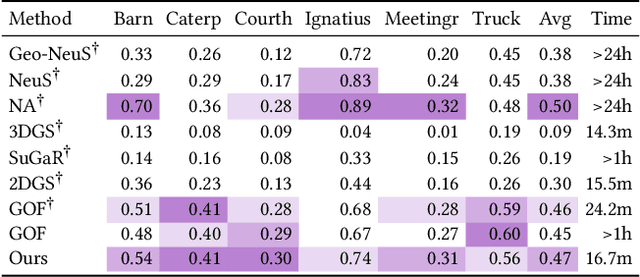
Recent advances in 3D Gaussian representations have significantly improved the quality and efficiency of image-based scene reconstruction. Their explicit nature facilitates real-time rendering and fast optimization, yet extracting accurate surfaces - particularly in large-scale, unbounded environments - remains a difficult task. Many existing methods rely on approximate depth estimates and global sorting heuristics, which can introduce artifacts and limit the fidelity of the reconstructed mesh. In this paper, we present Sorted Opacity Fields (SOF), a method designed to recover detailed surfaces from 3D Gaussians with both speed and precision. Our approach improves upon prior work by introducing hierarchical resorting and a robust formulation of Gaussian depth, which better aligns with the level-set. To enhance mesh quality, we incorporate a level-set regularizer operating on the opacity field and introduce losses that encourage geometrically-consistent primitive shapes. In addition, we develop a parallelized Marching Tetrahedra algorithm tailored to our opacity formulation, reducing meshing time by up to an order of magnitude. As demonstrated by our quantitative evaluation, SOF achieves higher reconstruction accuracy while cutting total processing time by more than a factor of three. These results mark a step forward in turning efficient Gaussian-based rendering into equally efficient geometry extraction.
VRSplat: Fast and Robust Gaussian Splatting for Virtual Reality
May 15, 2025



3D Gaussian Splatting (3DGS) has rapidly become a leading technique for novel-view synthesis, providing exceptional performance through efficient software-based GPU rasterization. Its versatility enables real-time applications, including on mobile and lower-powered devices. However, 3DGS faces key challenges in virtual reality (VR): (1) temporal artifacts, such as popping during head movements, (2) projection-based distortions that result in disturbing and view-inconsistent floaters, and (3) reduced framerates when rendering large numbers of Gaussians, falling below the critical threshold for VR. Compared to desktop environments, these issues are drastically amplified by large field-of-view, constant head movements, and high resolution of head-mounted displays (HMDs). In this work, we introduce VRSplat: we combine and extend several recent advancements in 3DGS to address challenges of VR holistically. We show how the ideas of Mini-Splatting, StopThePop, and Optimal Projection can complement each other, by modifying the individual techniques and core 3DGS rasterizer. Additionally, we propose an efficient foveated rasterizer that handles focus and peripheral areas in a single GPU launch, avoiding redundant computations and improving GPU utilization. Our method also incorporates a fine-tuning step that optimizes Gaussian parameters based on StopThePop depth evaluations and Optimal Projection. We validate our method through a controlled user study with 25 participants, showing a strong preference for VRSplat over other configurations of Mini-Splatting. VRSplat is the first, systematically evaluated 3DGS approach capable of supporting modern VR applications, achieving 72+ FPS while eliminating popping and stereo-disrupting floaters.
* I3D'25 (PACMCGIT); Project Page: https://cekavis.site/VRSplat/
AAA-Gaussians: Anti-Aliased and Artifact-Free 3D Gaussian Rendering
Apr 17, 2025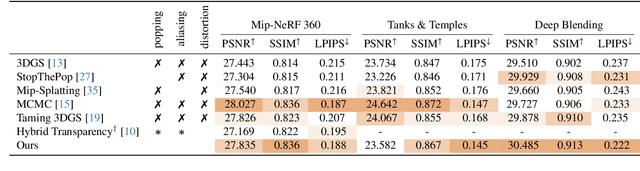


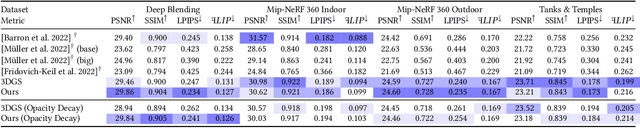
Although 3D Gaussian Splatting (3DGS) has revolutionized 3D reconstruction, it still faces challenges such as aliasing, projection artifacts, and view inconsistencies, primarily due to the simplification of treating splats as 2D entities. We argue that incorporating full 3D evaluation of Gaussians throughout the 3DGS pipeline can effectively address these issues while preserving rasterization efficiency. Specifically, we introduce an adaptive 3D smoothing filter to mitigate aliasing and present a stable view-space bounding method that eliminates popping artifacts when Gaussians extend beyond the view frustum. Furthermore, we promote tile-based culling to 3D with screen-space planes, accelerating rendering and reducing sorting costs for hierarchical rasterization. Our method achieves state-of-the-art quality on in-distribution evaluation sets and significantly outperforms other approaches for out-of-distribution views. Our qualitative evaluations further demonstrate the effective removal of aliasing, distortions, and popping artifacts, ensuring real-time, artifact-free rendering.
StopThePop: Sorted Gaussian Splatting for View-Consistent Real-time Rendering
Feb 01, 2024


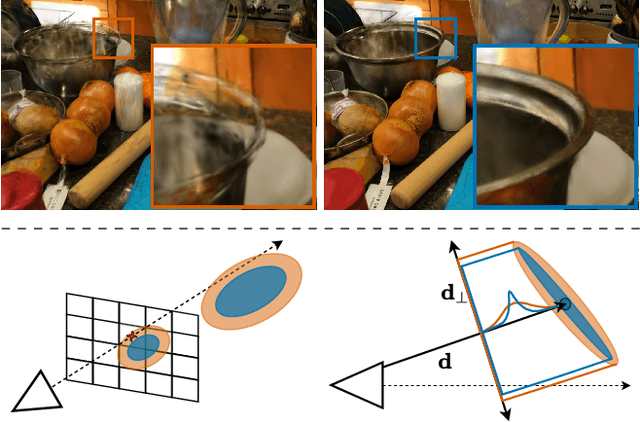
Gaussian Splatting has emerged as a prominent model for constructing 3D representations from images across diverse domains. However, the efficiency of the 3D Gaussian Splatting rendering pipeline relies on several simplifications. Notably, reducing Gaussian to 2D splats with a single view-space depth introduces popping and blending artifacts during view rotation. Addressing this issue requires accurate per-pixel depth computation, yet a full per-pixel sort proves excessively costly compared to a global sort operation. In this paper, we present a novel hierarchical rasterization approach that systematically resorts and culls splats with minimal processing overhead. Our software rasterizer effectively eliminates popping artifacts and view inconsistencies, as demonstrated through both quantitative and qualitative measurements. Simultaneously, our method mitigates the potential for cheating view-dependent effects with popping, ensuring a more authentic representation. Despite the elimination of cheating, our approach achieves comparable quantitative results for test images, while increasing the consistency for novel view synthesis in motion. Due to its design, our hierarchical approach is only 4% slower on average than the original Gaussian Splatting. Notably, enforcing consistency enables a reduction in the number of Gaussians by approximately half with nearly identical quality and view-consistency. Consequently, rendering performance is nearly doubled, making our approach 1.6x faster than the original Gaussian Splatting, with a 50% reduction in memory requirements.
LAENeRF: Local Appearance Editing for Neural Radiance Fields
Dec 15, 2023
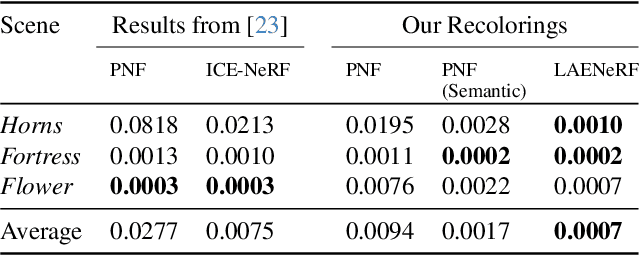

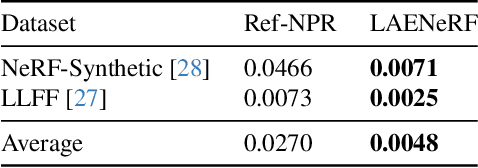
Due to the omnipresence of Neural Radiance Fields (NeRFs), the interest towards editable implicit 3D representations has surged over the last years. However, editing implicit or hybrid representations as used for NeRFs is difficult due to the entanglement of appearance and geometry encoded in the model parameters. Despite these challenges, recent research has shown first promising steps towards photorealistic and non-photorealistic appearance edits. The main open issues of related work include limited interactivity, a lack of support for local edits and large memory requirements, rendering them less useful in practice. We address these limitations with LAENeRF, a unified framework for photorealistic and non-photorealistic appearance editing of NeRFs. To tackle local editing, we leverage a voxel grid as starting point for region selection. We learn a mapping from expected ray terminations to final output color, which can optionally be supervised by a style loss, resulting in a framework which can perform photorealistic and non-photorealistic appearance editing of selected regions. Relying on a single point per ray for our mapping, we limit memory requirements and enable fast optimization. To guarantee interactivity, we compose the output color using a set of learned, modifiable base colors, composed with additive layer mixing. Compared to concurrent work, LAENeRF enables recoloring and stylization while keeping processing time low. Furthermore, we demonstrate that our approach surpasses baseline methods both quantitatively and qualitatively.
Analyzing the Internals of Neural Radiance Fields
Jun 01, 2023


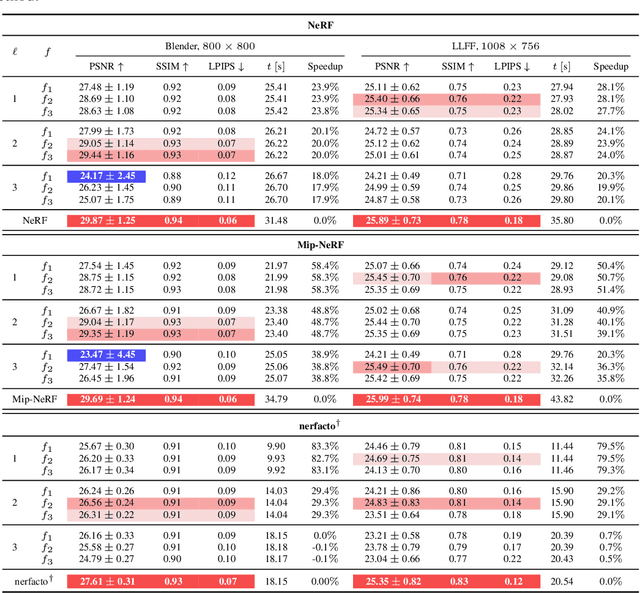
Modern Neural Radiance Fields (NeRFs) learn a mapping from position to volumetric density via proposal network samplers. In contrast to the coarse-to-fine sampling approach with two NeRFs, this offers significant potential for speedups using lower network capacity as the task of mapping spatial coordinates to volumetric density involves no view-dependent effects and is thus much easier to learn. Given that most of the network capacity is utilized to estimate radiance, NeRFs could store valuable density information in their parameters or their deep features. To this end, we take one step back and analyze large, trained ReLU-MLPs used in coarse-to-fine sampling. We find that trained NeRFs, Mip-NeRFs and proposal network samplers map samples with high density to local minima along a ray in activation feature space. We show how these large MLPs can be accelerated by transforming the intermediate activations to a weight estimate, without any modifications to the parameters post-optimization. With our approach, we can reduce the computational requirements of trained NeRFs by up to 50% with only a slight hit in rendering quality and no changes to the training protocol or architecture. We evaluate our approach on a variety of architectures and datasets, showing that our proposition holds in various settings.