 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing the Internals of Neural Radiance Fields
Paper and Code



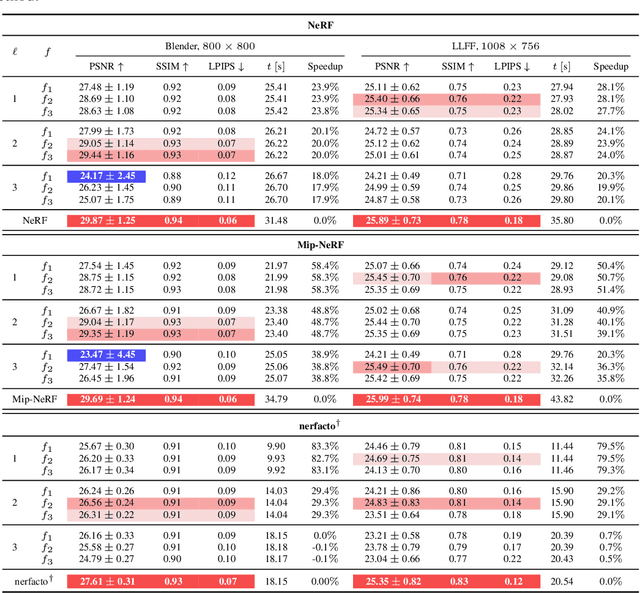
Modern Neural Radiance Fields (NeRFs) learn a mapping from position to volumetric density via proposal network samplers. In contrast to the coarse-to-fine sampling approach with two NeRFs, this offers significant potential for speedups using lower network capacity as the task of mapping spatial coordinates to volumetric density involves no view-dependent effects and is thus much easier to learn. Given that most of the network capacity is utilized to estimate radiance, NeRFs could store valuable density information in their parameters or their deep features. To this end, we take one step back and analyze large, trained ReLU-MLPs used in coarse-to-fine sampling. We find that trained NeRFs, Mip-NeRFs and proposal network samplers map samples with high density to local minima along a ray in activation feature space. We show how these large MLPs can be accelerated by transforming the intermediate activations to a weight estimate, without any modifications to the parameters post-optimization. With our approach, we can reduce the computational requirements of trained NeRFs by up to 50% with only a slight hit in rendering quality and no changes to the training protocol or architecture. We evaluate our approach on a variety of architectures and datasets, showing that our proposition holds in various settings.