 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence-Based Mesh Extraction from 3D Gaussians
Mar 25, 2026Recently, 3D Gaussian Splatting (3DGS) greatly accelerated mesh extraction from posed images due to its explicit representation and fast software rasterization. While the addition of geometric losses and other priors has improved the accuracy of extracted surfaces, mesh extraction remains difficult in scenes with abundant view-dependent effects. To resolve the resulting ambiguities, prior works rely on multi-view techniques, iterative mesh extraction, or large pre-trained models, sacrificing the inherent efficiency of 3DGS. In this work, we present a simple and efficient alternative by introducing a self-supervised confidence framework to 3DGS: within this framework, learnable confidence values dynamically balance photometric and geometric supervision. Extending our confidence-driven formulation, we introduce losses which penalize per-primitive color and normal variance and demonstrate their benefits to surface extraction. Finally, we complement the above with an improved appearance model, by decoupling the individual terms of the D-SSIM loss. Our final approach delivers state-of-the-art results for unbounded meshes while remaining highly efficient.
LAENeRF: Local Appearance Editing for Neural Radiance Fields
Dec 15, 2023
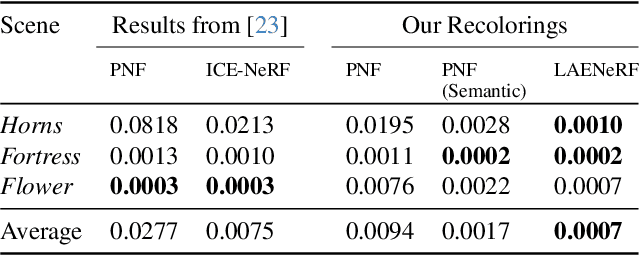

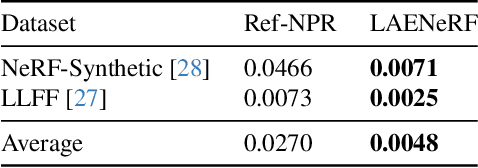
Due to the omnipresence of Neural Radiance Fields (NeRFs), the interest towards editable implicit 3D representations has surged over the last years. However, editing implicit or hybrid representations as used for NeRFs is difficult due to the entanglement of appearance and geometry encoded in the model parameters. Despite these challenges, recent research has shown first promising steps towards photorealistic and non-photorealistic appearance edits. The main open issues of related work include limited interactivity, a lack of support for local edits and large memory requirements, rendering them less useful in practice. We address these limitations with LAENeRF, a unified framework for photorealistic and non-photorealistic appearance editing of NeRFs. To tackle local editing, we leverage a voxel grid as starting point for region selection. We learn a mapping from expected ray terminations to final output color, which can optionally be supervised by a style loss, resulting in a framework which can perform photorealistic and non-photorealistic appearance editing of selected regions. Relying on a single point per ray for our mapping, we limit memory requirements and enable fast optimization. To guarantee interactivity, we compose the output color using a set of learned, modifiable base colors, composed with additive layer mixing. Compared to concurrent work, LAENeRF enables recoloring and stylization while keeping processing time low. Furthermore, we demonstrate that our approach surpasses baseline methods both quantitatively and qualitatively.
Analyzing the Internals of Neural Radiance Fields
Jun 01, 2023


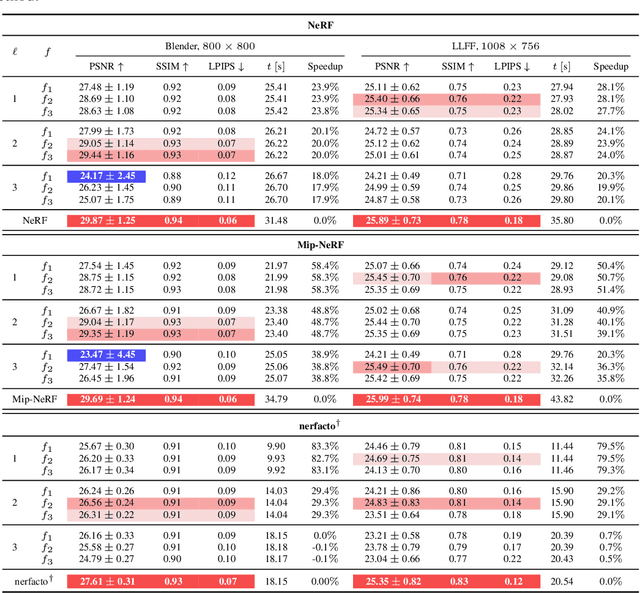
Modern Neural Radiance Fields (NeRFs) learn a mapping from position to volumetric density via proposal network samplers. In contrast to the coarse-to-fine sampling approach with two NeRFs, this offers significant potential for speedups using lower network capacity as the task of mapping spatial coordinates to volumetric density involves no view-dependent effects and is thus much easier to learn. Given that most of the network capacity is utilized to estimate radiance, NeRFs could store valuable density information in their parameters or their deep features. To this end, we take one step back and analyze large, trained ReLU-MLPs used in coarse-to-fine sampling. We find that trained NeRFs, Mip-NeRFs and proposal network samplers map samples with high density to local minima along a ray in activation feature space. We show how these large MLPs can be accelerated by transforming the intermediate activations to a weight estimate, without any modifications to the parameters post-optimization. With our approach, we can reduce the computational requirements of trained NeRFs by up to 50% with only a slight hit in rendering quality and no changes to the training protocol or architecture. We evaluate our approach on a variety of architectures and datasets, showing that our proposition holds in various settings.
AdaNeRF: Adaptive Sampling for Real-time Rendering of Neural Radiance Fields
Jul 28, 2022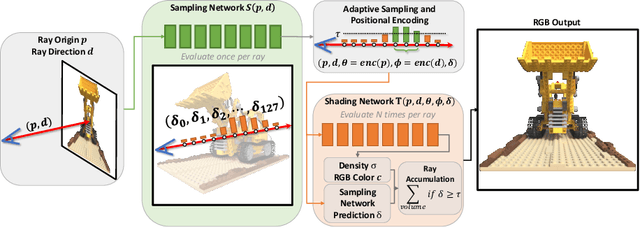
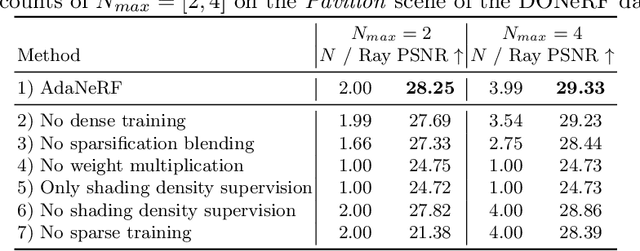
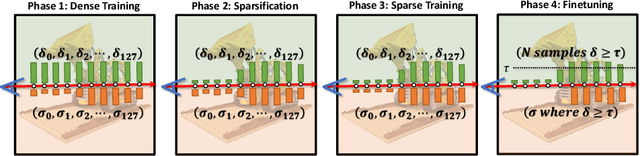
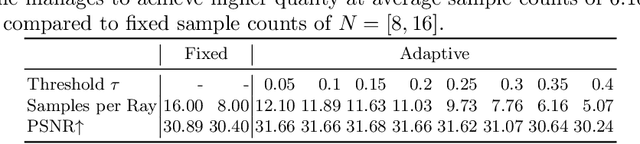
Novel view synthesis has recently been revolutionized by learning neural radiance fields directly from sparse observations. However, rendering images with this new paradigm is slow due to the fact that an accurate quadrature of the volume rendering equation requires a large number of samples for each ray. Previous work has mainly focused on speeding up the network evaluations that are associated with each sample point, e.g., via caching of radiance values into explicit spatial data structures, but this comes at the expense of model compactness. In this paper, we propose a novel dual-network architecture that takes an orthogonal direction by learning how to best reduce the number of required sample points. To this end, we split our network into a sampling and shading network that are jointly trained. Our training scheme employs fixed sample positions along each ray, and incrementally introduces sparsity throughout training to achieve high quality even at low sample counts. After fine-tuning with the target number of samples, the resulting compact neural representation can be rendered in real-time. Our experiments demonstrate that our approach outperforms concurrent compact neural representations in terms of quality and frame rate and performs on par with highly efficient hybrid representations. Code and supplementary material is available at https://thomasneff.github.io/adanerf.
DONeRF: Towards Real-Time Rendering of Neural Radiance Fields using Depth Oracle Networks
Mar 11, 2021
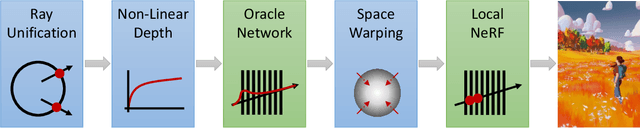
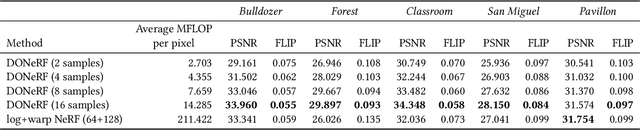
The recent research explosion around implicit neural representations, such as NeRF, shows that there is immense potential for implicitly storing high-quality scene and lighting information in neural networks. However, one major limitation preventing the use of NeRF in interactive and real-time rendering applications is the prohibitive computational cost of excessive network evaluations along each view ray, requiring dozens of petaFLOPS when aiming for real-time rendering on consumer hardware. In this work, we take a step towards bringing neural representations closer to practical rendering of synthetic content in interactive and real-time applications, such as games and virtual reality. We show that the number of samples required for each view ray can be significantly reduced when local samples are placed around surfaces in the scene. To this end, we propose a depth oracle network, which predicts ray sample locations for each view ray with a single network evaluation. We show that using a classification network around logarithmically discretized and spherically warped depth values is essential to encode surface locations rather than directly estimating depth. The combination of these techniques leads to DONeRF, a dual network design with a depth oracle network as a first step and a locally sampled shading network for ray accumulation. With our design, we reduce the inference costs by up to 48x compared to NeRF. Using an off-the-shelf inference API in combination with simple compute kernels, we are the first to render raymarching-based neural representations at interactive frame rates (15 frames per second at 800x800) on a single GPU. At the same time, since we focus on the important parts of the scene around surfaces, we achieve equal or better quality compared to NeRF to enable interactive high-quality rendering.