 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaNeRF: Adaptive Sampling for Real-time Rendering of Neural Radiance Fields
Jul 28, 2022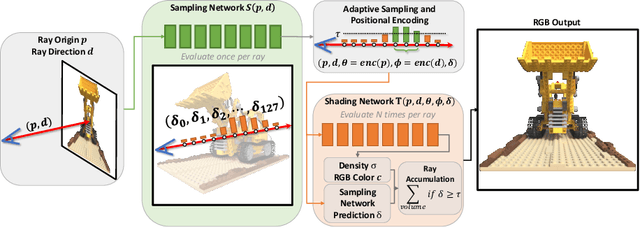
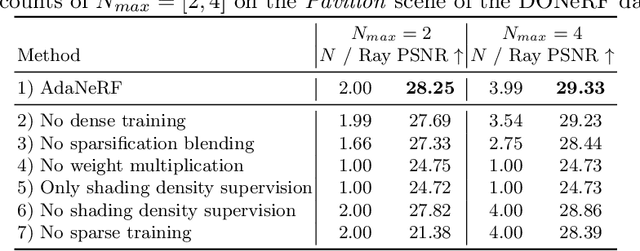
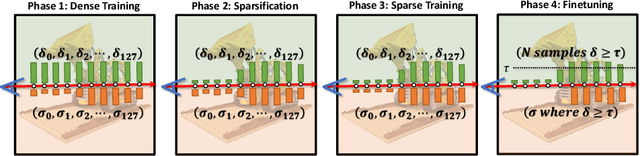
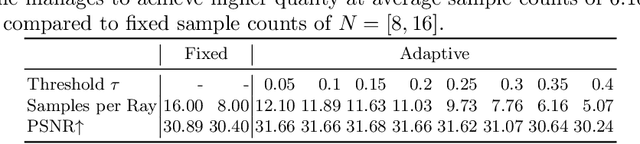
Novel view synthesis has recently been revolutionized by learning neural radiance fields directly from sparse observations. However, rendering images with this new paradigm is slow due to the fact that an accurate quadrature of the volume rendering equation requires a large number of samples for each ray. Previous work has mainly focused on speeding up the network evaluations that are associated with each sample point, e.g., via caching of radiance values into explicit spatial data structures, but this comes at the expense of model compactness. In this paper, we propose a novel dual-network architecture that takes an orthogonal direction by learning how to best reduce the number of required sample points. To this end, we split our network into a sampling and shading network that are jointly trained. Our training scheme employs fixed sample positions along each ray, and incrementally introduces sparsity throughout training to achieve high quality even at low sample counts. After fine-tuning with the target number of samples, the resulting compact neural representation can be rendered in real-time. Our experiments demonstrate that our approach outperforms concurrent compact neural representations in terms of quality and frame rate and performs on par with highly efficient hybrid representations. Code and supplementary material is available at https://thomasneff.github.io/adanerf.
DONeRF: Towards Real-Time Rendering of Neural Radiance Fields using Depth Oracle Networks
Mar 11, 2021
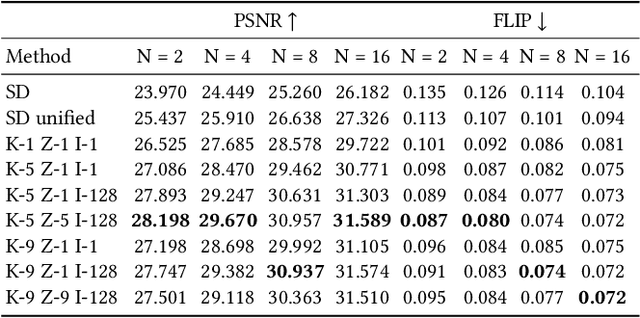
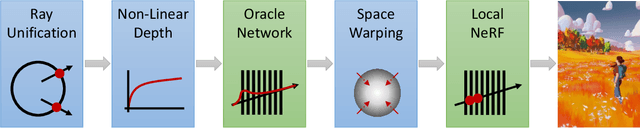
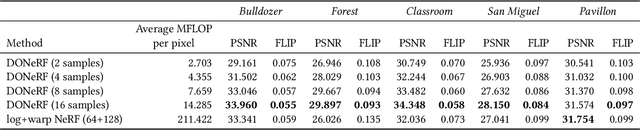
The recent research explosion around implicit neural representations, such as NeRF, shows that there is immense potential for implicitly storing high-quality scene and lighting information in neural networks. However, one major limitation preventing the use of NeRF in interactive and real-time rendering applications is the prohibitive computational cost of excessive network evaluations along each view ray, requiring dozens of petaFLOPS when aiming for real-time rendering on consumer hardware. In this work, we take a step towards bringing neural representations closer to practical rendering of synthetic content in interactive and real-time applications, such as games and virtual reality. We show that the number of samples required for each view ray can be significantly reduced when local samples are placed around surfaces in the scene. To this end, we propose a depth oracle network, which predicts ray sample locations for each view ray with a single network evaluation. We show that using a classification network around logarithmically discretized and spherically warped depth values is essential to encode surface locations rather than directly estimating depth. The combination of these techniques leads to DONeRF, a dual network design with a depth oracle network as a first step and a locally sampled shading network for ray accumulation. With our design, we reduce the inference costs by up to 48x compared to NeRF. Using an off-the-shelf inference API in combination with simple compute kernels, we are the first to render raymarching-based neural representations at interactive frame rates (15 frames per second at 800x800) on a single GPU. At the same time, since we focus on the important parts of the scene around surfaces, we achieve equal or better quality compared to NeRF to enable interactive high-quality rendering.
Instance Segmentation and Tracking with Cosine Embeddings and Recurrent Hourglass Networks
Jul 30, 2018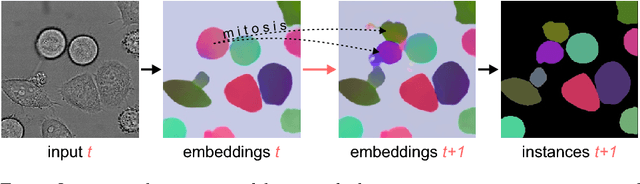
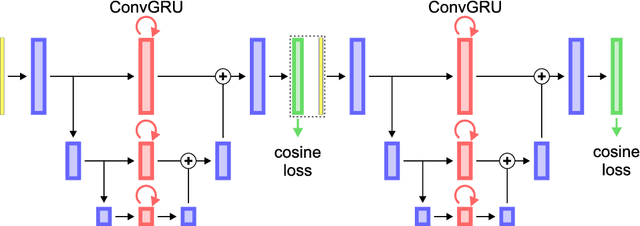
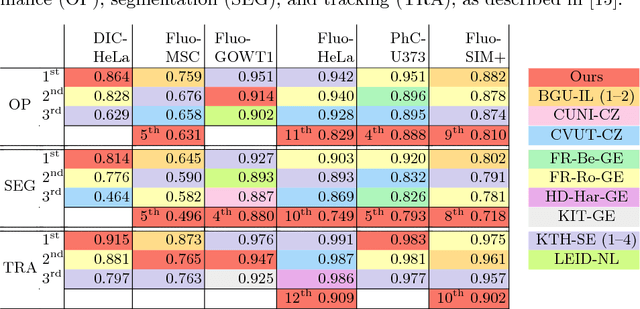

Different to semantic segmentation, instance segmentation assigns unique labels to each individual instance of the same class. In this work, we propose a novel recurrent fully convolutional network architecture for tracking such instance segmentations over time. The network architecture incorporates convolutional gated recurrent units (ConvGRU) into a stacked hourglass network to utilize temporal video information. Furthermore, we train the network with a novel embedding loss based on cosine similarities, such that the network predicts unique embeddings for every instance throughout videos. Afterwards, these embeddings are clustered among subsequent video frames to create the final tracked instance segmentations. We evaluate the recurrent hourglass network by segmenting left ventricles in MR videos of the heart, where it outperforms a network that does not incorporate video information. Furthermore, we show applicability of the cosine embedding loss for segmenting leaf instances on still images of plants. Finally, we evaluate the framework for instance segmentation and tracking on six datasets of the ISBI celltracking challenge, where it shows state-of-the-art performance.
Towards MRI-Based Autonomous Robotic US Acquisitions: A First Feasibility Study
Jul 28, 2016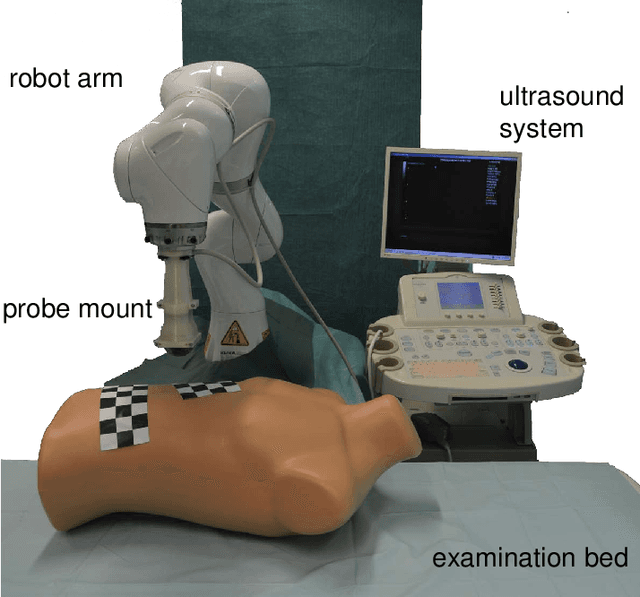
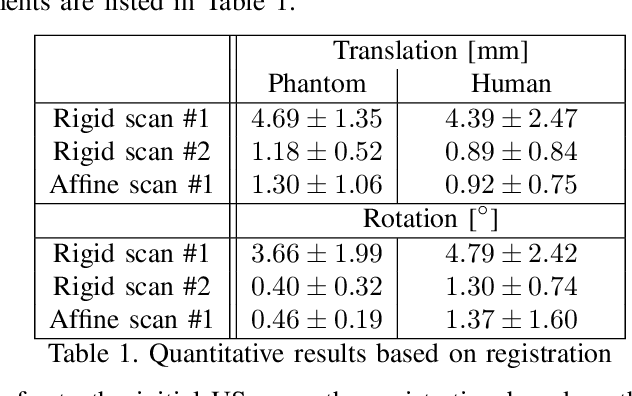
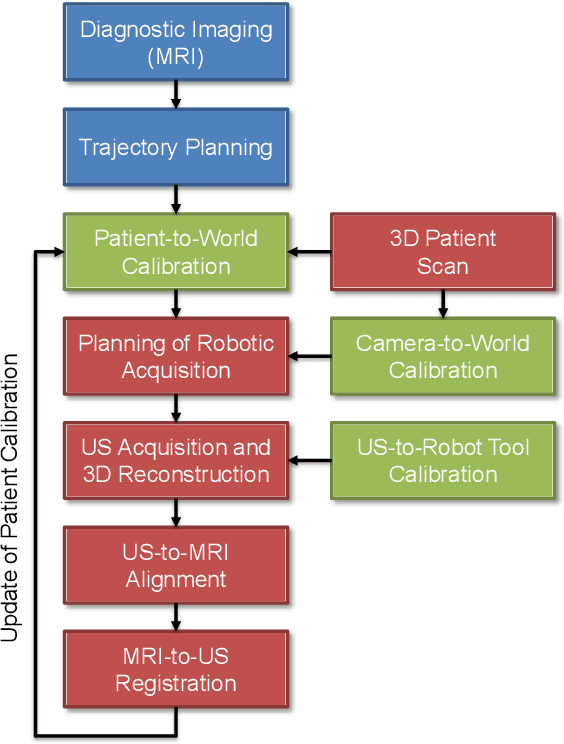
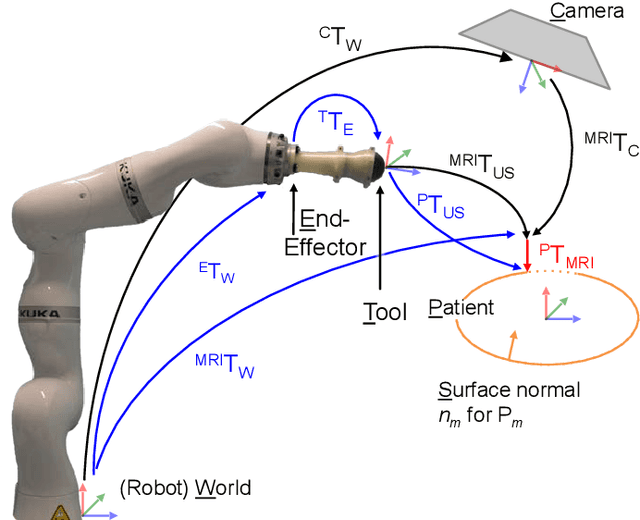
Robotic ultrasound has the potential to assist and guide physicians during interventions. In this work, we present a set of methods and a workflow to enable autonomous MRI-guided ultrasound acquisitions. Our approach uses a structured-light 3D scanner for patient-to-robot and image-to-patient calibration, which in turn is used to plan 3D ultrasound trajectories. These MRI-based trajectories are followed autonomously by the robot and are further refined online using automatic MRI/US registration. Despite the low spatial resolution of structured light scanners, the initial planned acquisition path can be followed with an accuracy of 2.46 +/- 0.96 mm. This leads to a good initialization of the MRI/US registration: the 3D-scan-based alignment for planning and acquisition shows an accuracy (distance between planned ultrasound and MRI) of 4.47 mm, and 0.97 mm after an online-update of the calibration based on a closed loop registration.