 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJailbreaking Attacks vs. Content Safety Filters: How Far Are We in the LLM Safety Arms Race?
Dec 30, 2025As large language models (LLMs) are increasingly deployed, ensuring their safe use is paramount. Jailbreaking, adversarial prompts that bypass model alignment to trigger harmful outputs, present significant risks, with existing studies reporting high success rates in evading common LLMs. However, previous evaluations have focused solely on the models, neglecting the full deployment pipeline, which typically incorporates additional safety mechanisms like content moderation filters. To address this gap, we present the first systematic evaluation of jailbreak attacks targeting LLM safety alignment, assessing their success across the full inference pipeline, including both input and output filtering stages. Our findings yield two key insights: first, nearly all evaluated jailbreak techniques can be detected by at least one safety filter, suggesting that prior assessments may have overestimated the practical success of these attacks; second, while safety filters are effective in detection, there remains room to better balance recall and precision to further optimize protection and user experience. We highlight critical gaps and call for further refinement of detection accuracy and usability in LLM safety systems.
Inside the Black Box: Detecting Data Leakage in Pre-trained Language Encoders
Aug 20, 2024



Despite being prevalent in the general field of Natural Language Processing (NLP), pre-trained language models inherently carry privacy and copyright concerns due to their nature of training on large-scale web-scraped data. In this paper, we pioneer a systematic exploration of such risks associated with pre-trained language encoders, specifically focusing on the membership leakage of pre-training data exposed through downstream models adapted from pre-trained language encoders-an aspect largely overlooked in existing literature. Our study encompasses comprehensive experiments across four types of pre-trained encoder architectures, three representative downstream tasks, and five benchmark datasets. Intriguingly, our evaluations reveal, for the first time, the existence of membership leakage even when only the black-box output of the downstream model is exposed, highlighting a privacy risk far greater than previously assumed. Alongside, we present in-depth analysis and insights toward guiding future researchers and practitioners in addressing the privacy considerations in developing pre-trained language models.
PoLLMgraph: Unraveling Hallucinations in Large Language Models via State Transition Dynamics
Apr 06, 2024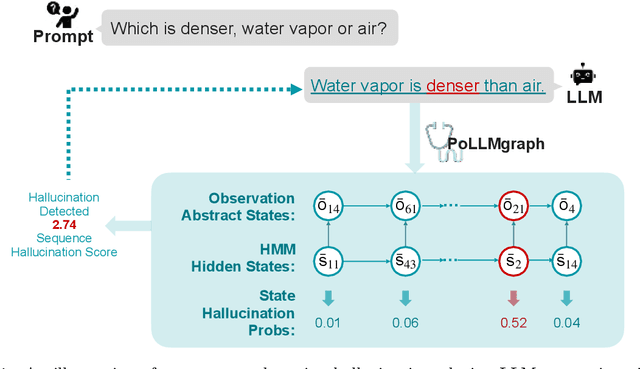
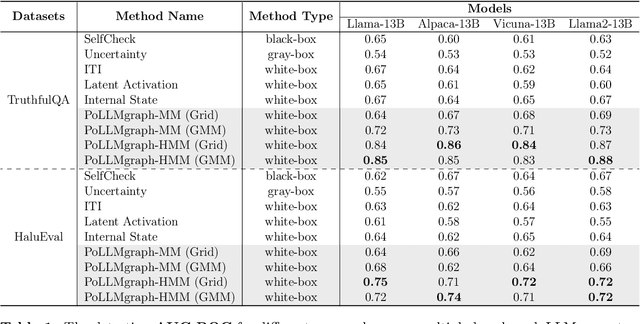

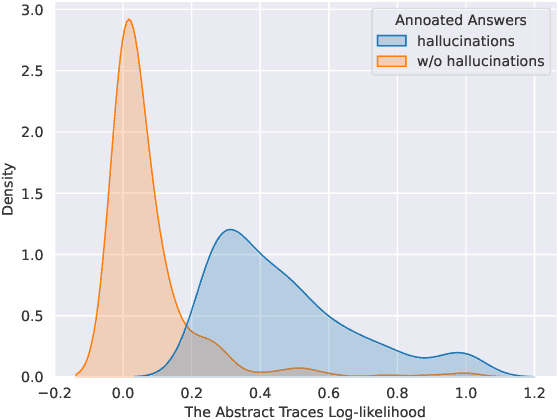
Despite tremendous advancements in large language models (LLMs) over recent years, a notably urgent challenge for their practical deployment is the phenomenon of hallucination, where the model fabricates facts and produces non-factual statements. In response, we propose PoLLMgraph, a Polygraph for LLMs, as an effective model-based white-box detection and forecasting approach. PoLLMgraph distinctly differs from the large body of existing research that concentrates on addressing such challenges through black-box evaluations. In particular, we demonstrate that hallucination can be effectively detected by analyzing the LLM's internal state transition dynamics during generation via tractable probabilistic models. Experimental results on various open-source LLMs confirm the efficacy of PoLLMgraph, outperforming state-of-the-art methods by a considerable margin, evidenced by over 20% improvement in AUC-ROC on common benchmarking datasets like TruthfulQA. Our work paves a new way for model-based white-box analysis of LLMs, motivating the research community to further explore, understand, and refine the intricate dynamics of LLM behaviors.
Towards Biologically Plausible and Private Gene Expression Data Generation
Feb 07, 2024
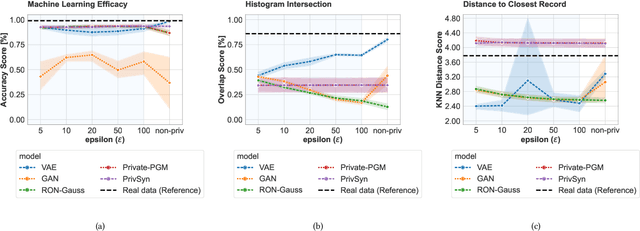

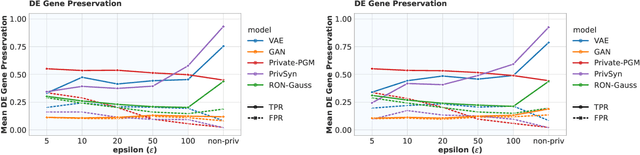
Generative models trained with Differential Privacy (DP) are becoming increasingly prominent in the creation of synthetic data for downstream applications. Existing literature, however, primarily focuses on basic benchmarking datasets and tends to report promising results only for elementary metrics and relatively simple data distributions. In this paper, we initiate a systematic analysis of how DP generative models perform in their natural application scenarios, specifically focusing on real-world gene expression data. We conduct a comprehensive analysis of five representative DP generation methods, examining them from various angles, such as downstream utility, statistical properties, and biological plausibility. Our extensive evaluation illuminates the unique characteristics of each DP generation method, offering critical insights into the strengths and weaknesses of each approach, and uncovering intriguing possibilities for future developments. Perhaps surprisingly, our analysis reveals that most methods are capable of achieving seemingly reasonable downstream utility, according to the standard evaluation metrics considered in existing literature. Nevertheless, we find that none of the DP methods are able to accurately capture the biological characteristics of the real dataset. This observation suggests a potential over-optimistic assessment of current methodologies in this field and underscores a pressing need for future enhancements in model design.
A Unified View of Differentially Private Deep Generative Modeling
Sep 27, 2023
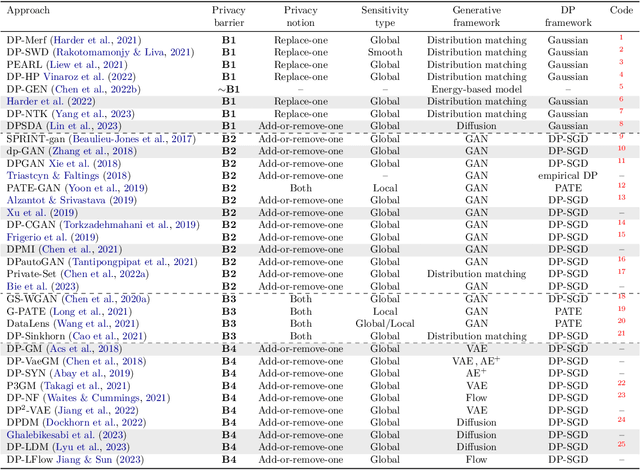
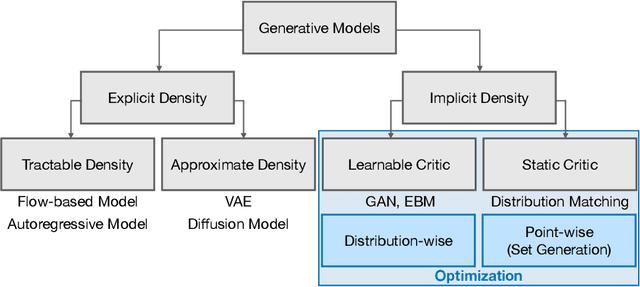
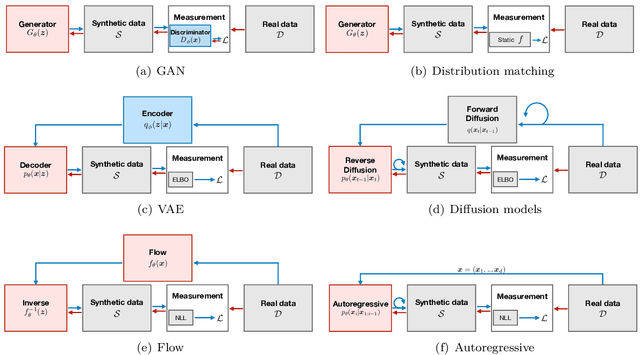
The availability of rich and vast data sources has greatly advanced machine learning applications in various domains. However, data with privacy concerns comes with stringent regulations that frequently prohibited data access and data sharing. Overcoming these obstacles in compliance with privacy considerations is key for technological progress in many real-world application scenarios that involve privacy sensitive data. Differentially private (DP) data publishing provides a compelling solution, where only a sanitized form of the data is publicly released, enabling privacy-preserving downstream analysis and reproducible research in sensitive domains. In recent years, various approaches have been proposed for achieving privacy-preserving high-dimensional data generation by private training on top of deep neural networks. In this paper, we present a novel unified view that systematizes these approaches. Our view provides a joint design space for systematically deriving methods that cater to different use cases. We then discuss the strengths, limitations, and inherent correlations between different approaches, aiming to shed light on crucial aspects and inspire future research. We conclude by presenting potential paths forward for the field of DP data generation, with the aim of steering the community toward making the next important steps in advancing privacy-preserving learning.
MargCTGAN: A "Marginally'' Better CTGAN for the Low Sample Regime
Jul 16, 2023The potential of realistic and useful synthetic data is significant. However, current evaluation methods for synthetic tabular data generation predominantly focus on downstream task usefulness, often neglecting the importance of statistical properties. This oversight becomes particularly prominent in low sample scenarios, accompanied by a swift deterioration of these statistical measures. In this paper, we address this issue by conducting an evaluation of three state-of-the-art synthetic tabular data generators based on their marginal distribution, column-pair correlation, joint distribution and downstream task utility performance across high to low sample regimes. The popular CTGAN model shows strong utility, but underperforms in low sample settings in terms of utility. To overcome this limitation, we propose MargCTGAN that adds feature matching of de-correlated marginals, which results in a consistent improvement in downstream utility as well as statistical properties of the synthetic data.
Data Forensics in Diffusion Models: A Systematic Analysis of Membership Privacy
Feb 15, 2023In recent years, diffusion models have achieved tremendous success in the field of image generation, becoming the stateof-the-art technology for AI-based image processing applications. Despite the numerous benefits brought by recent advances in diffusion models, there are also concerns about their potential misuse, specifically in terms of privacy breaches and intellectual property infringement. In particular, some of their unique characteristics open up new attack surfaces when considering the real-world deployment of such models. With a thorough investigation of the attack vectors, we develop a systematic analysis of membership inference attacks on diffusion models and propose novel attack methods tailored to each attack scenario specifically relevant to diffusion models. Our approach exploits easily obtainable quantities and is highly effective, achieving near-perfect attack performance (>0.9 AUCROC) in realistic scenarios. Our extensive experiments demonstrate the effectiveness of our method, highlighting the importance of considering privacy and intellectual property risks when using diffusion models in image generation tasks.
Fed-GLOSS-DP: Federated, Global Learning using Synthetic Sets with Record Level Differential Privacy
Feb 02, 2023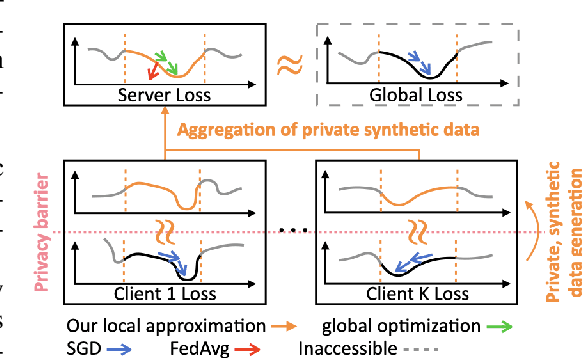

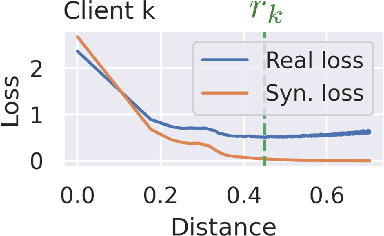

This work proposes Fed-GLOSS-DP, a novel approach to privacy-preserving learning that uses synthetic data to train federated models. In our approach, the server recovers an approximation of the global loss landscape in a local neighborhood based on synthetic samples received from the clients. In contrast to previous, point-wise, gradient-based, linear approximation (such as FedAvg), our formulation enables a type of global optimization that is particularly beneficial in non-IID federated settings. We also present how it rigorously complements record-level differential privacy. Extensive results show that our novel formulation gives rise to considerable improvements in terms of convergence speed and communication costs. We argue that our new approach to federated learning can provide a potential path toward reconciling privacy and accountability by sending differentially private, synthetic data instead of gradient updates. The source code will be released upon publication.
Private Set Generation with Discriminative Information
Nov 07, 2022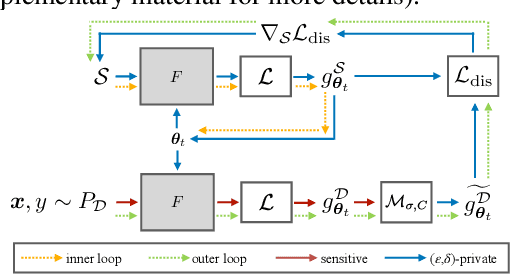
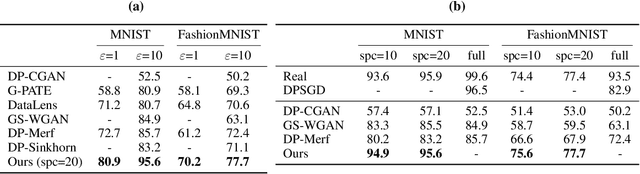
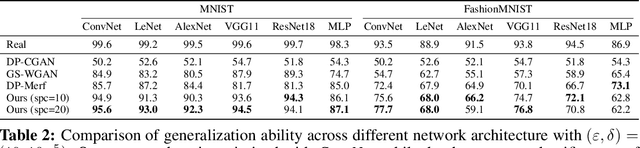
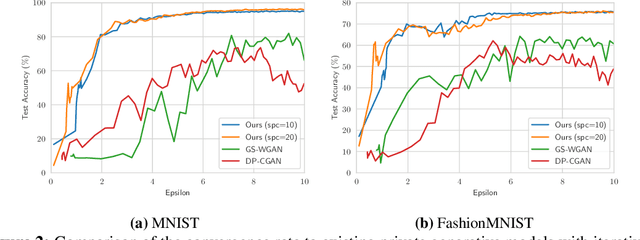
Differentially private data generation techniques have become a promising solution to the data privacy challenge -- it enables sharing of data while complying with rigorous privacy guarantees, which is essential for scientific progress in sensitive domains. Unfortunately, restricted by the inherent complexity of modeling high-dimensional distributions, existing private generative models are struggling with the utility of synthetic samples. In contrast to existing works that aim at fitting the complete data distribution, we directly optimize for a small set of samples that are representative of the distribution under the supervision of discriminative information from downstream tasks, which is generally an easier task and more suitable for private training. Our work provides an alternative view for differentially private generation of high-dimensional data and introduces a simple yet effective method that greatly improves the sample utility of state-of-the-art approaches.
* NeurIPS 2022, 19 pages
RelaxLoss: Defending Membership Inference Attacks without Losing Utility
Jul 12, 2022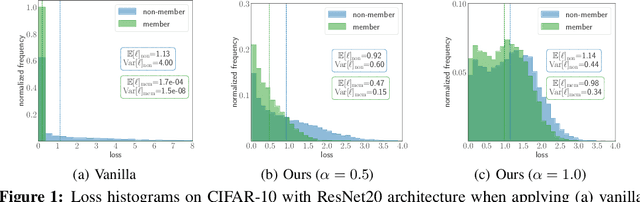

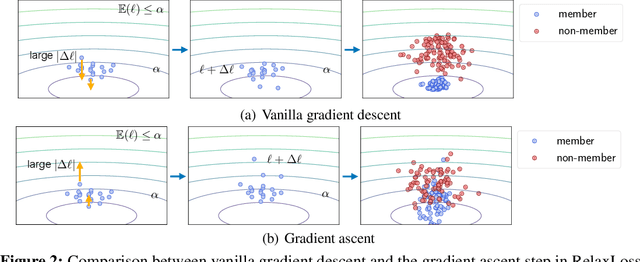
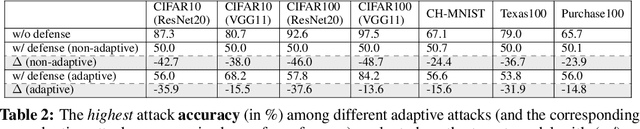
As a long-term threat to the privacy of training data, membership inference attacks (MIAs) emerge ubiquitously in machine learning models. Existing works evidence strong connection between the distinguishability of the training and testing loss distributions and the model's vulnerability to MIAs. Motivated by existing results, we propose a novel training framework based on a relaxed loss with a more achievable learning target, which leads to narrowed generalization gap and reduced privacy leakage. RelaxLoss is applicable to any classification model with added benefits of easy implementation and negligible overhead. Through extensive evaluations on five datasets with diverse modalities (images, medical data, transaction records), our approach consistently outperforms state-of-the-art defense mechanisms in terms of resilience against MIAs as well as model utility. Our defense is the first that can withstand a wide range of attacks while preserving (or even improving) the target model's utility. Source code is available at https://github.com/DingfanChen/RelaxLoss
* International Conference on Learning Representations (ICLR) 2022, 28 pages