 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyak Meets Parameter-free Clipped Gradient Descent
Paper and Code

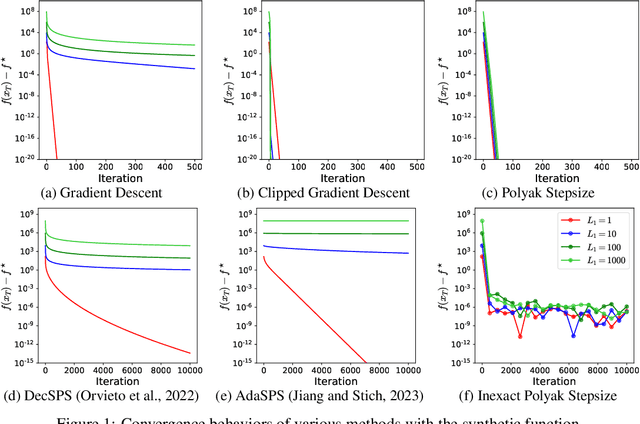
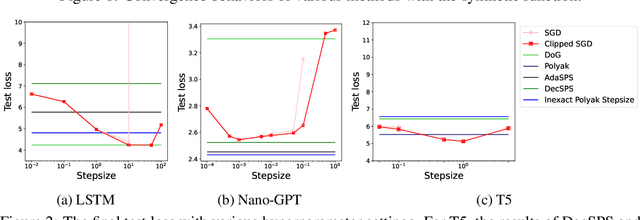
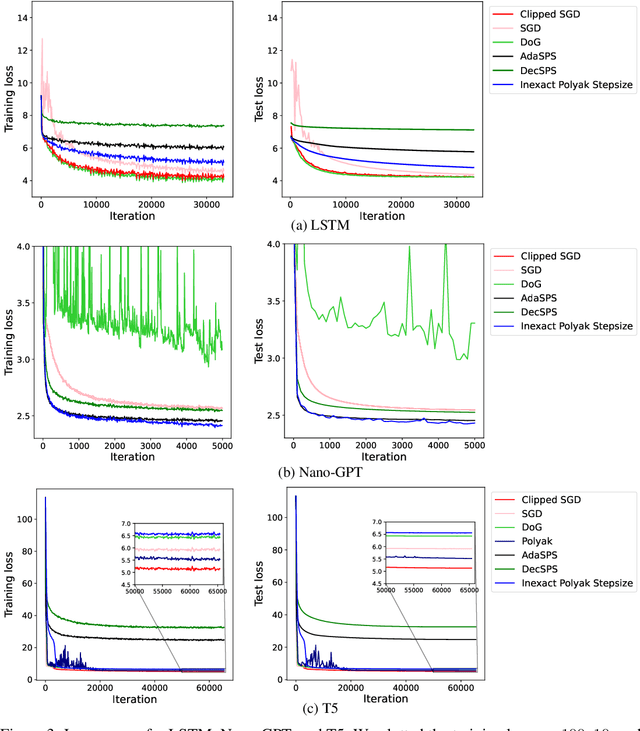
Gradient descent and its variants are de facto standard algorithms for training machine learning models. As gradient descent is sensitive to its hyperparameters, we need to tune the hyperparameters carefully using a grid search, but it is time-consuming, especially when multiple hyperparameters exist. Recently, parameter-free methods that adjust the hyperparameters on the fly have been studied. However, the existing work only studied parameter-free methods for the stepsize, and parameter-free methods for other hyperparameters have not been explored. For instance, the gradient clipping threshold is also a crucial hyperparameter in addition to the stepsize to prevent gradient explosion issues, but none of the existing studies investigated the parameter-free methods for clipped gradient descent. In this work, we study the parameter-free methods for clipped gradient descent. Specifically, we propose Inexact Polyak Stepsize, which converges to the optimal solution without any hyperparameters tuning, and its convergence rate is asymptotically independent of L under L-smooth and $(L_0, L_1)$-smooth assumptions of the loss function as that of clipped gradient descent with well-tuned hyperparameters. We numerically validated our convergence results using a synthetic function and demonstrated the effectiveness of our proposed methods using LSTM, Nano-GPT, and T5.