 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFDLS: A Deep Learning Approach to Production Quality, Controllable, and Retargetable Facial Performances
Sep 26, 2023
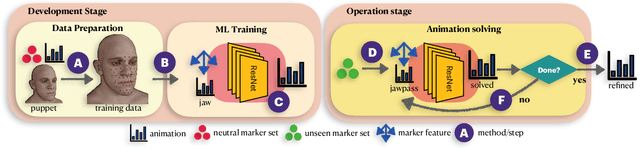
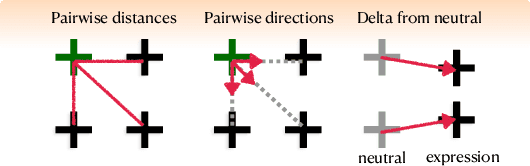
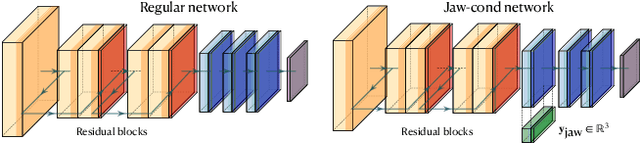
Visual effects commonly requires both the creation of realistic synthetic humans as well as retargeting actors' performances to humanoid characters such as aliens and monsters. Achieving the expressive performances demanded in entertainment requires manipulating complex models with hundreds of parameters. Full creative control requires the freedom to make edits at any stage of the production, which prohibits the use of a fully automatic ``black box'' solution with uninterpretable parameters. On the other hand, producing realistic animation with these sophisticated models is difficult and laborious. This paper describes FDLS (Facial Deep Learning Solver), which is Weta Digital's solution to these challenges. FDLS adopts a coarse-to-fine and human-in-the-loop strategy, allowing a solved performance to be verified and edited at several stages in the solving process. To train FDLS, we first transform the raw motion-captured data into robust graph features. Secondly, based on the observation that the artists typically finalize the jaw pass animation before proceeding to finer detail, we solve for the jaw motion first and predict fine expressions with region-based networks conditioned on the jaw position. Finally, artists can optionally invoke a non-linear finetuning process on top of the FDLS solution to follow the motion-captured virtual markers as closely as possible. FDLS supports editing if needed to improve the results of the deep learning solution and it can handle small daily changes in the actor's face shape. FDLS permits reliable and production-quality performance solving with minimal training and little or no manual effort in many cases, while also allowing the solve to be guided and edited in unusual and difficult cases. The system has been under development for several years and has been used in major movies.
Deep Reconstruction-Classification Networks for Unsupervised Domain Adaptation
Aug 01, 2016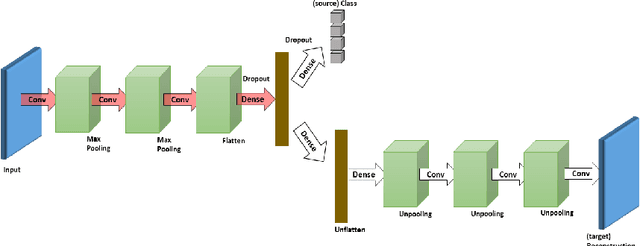
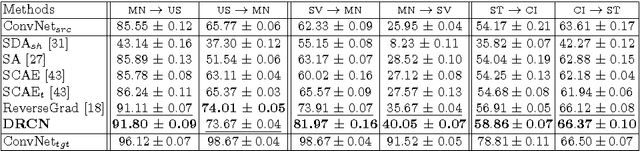


In this paper, we propose a novel unsupervised domain adaptation algorithm based on deep learning for visual object recognition. Specifically, we design a new model called Deep Reconstruction-Classification Network (DRCN), which jointly learns a shared encoding representation for two tasks: i) supervised classification of labeled source data, and ii) unsupervised reconstruction of unlabeled target data.In this way, the learnt representation not only preserves discriminability, but also encodes useful information from the target domain. Our new DRCN model can be optimized by using backpropagation similarly as the standard neural networks. We evaluate the performance of DRCN on a series of cross-domain object recognition tasks, where DRCN provides a considerable improvement (up to ~8% in accuracy) over the prior state-of-the-art algorithms. Interestingly, we also observe that the reconstruction pipeline of DRCN transforms images from the source domain into images whose appearance resembles the target dataset. This suggests that DRCN's performance is due to constructing a single composite representation that encodes information about both the structure of target images and the classification of source images. Finally, we provide a formal analysis to justify the algorithm's objective in domain adaptation context.
Scatter Component Analysis: A Unified Framework for Domain Adaptation and Domain Generalization
Jul 26, 2016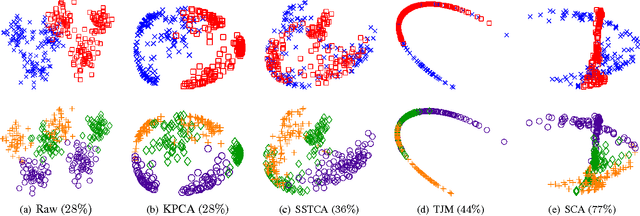

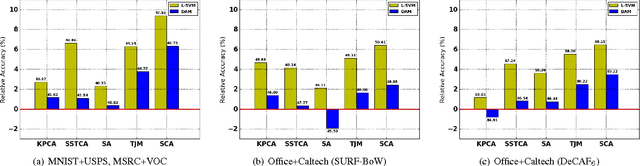
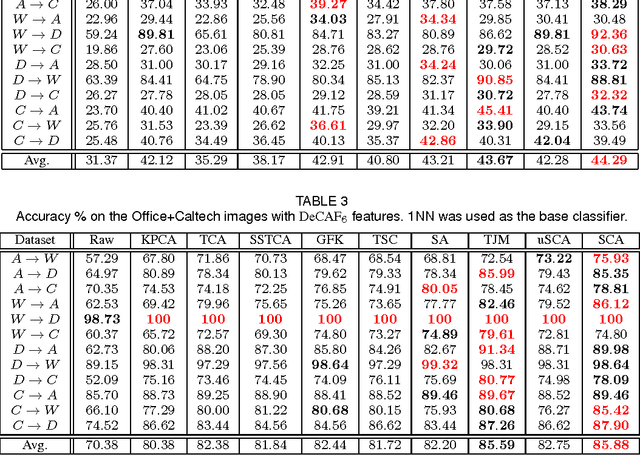
This paper addresses classification tasks on a particular target domain in which labeled training data are only available from source domains different from (but related to) the target. Two closely related frameworks, domain adaptation and domain generalization, are concerned with such tasks, where the only difference between those frameworks is the availability of the unlabeled target data: domain adaptation can leverage unlabeled target information, while domain generalization cannot. We propose Scatter Component Analyis (SCA), a fast representation learning algorithm that can be applied to both domain adaptation and domain generalization. SCA is based on a simple geometrical measure, i.e., scatter, which operates on reproducing kernel Hilbert space. SCA finds a representation that trades between maximizing the separability of classes, minimizing the mismatch between domains, and maximizing the separability of data; each of which is quantified through scatter. The optimization problem of SCA can be reduced to a generalized eigenvalue problem, which results in a fast and exact solution. Comprehensive experiments on benchmark cross-domain object recognition datasets verify that SCA performs much faster than several state-of-the-art algorithms and also provides state-of-the-art classification accuracy in both domain adaptation and domain generalization. We also show that scatter can be used to establish a theoretical generalization bound in the case of domain adaptation.
Strongly-Typed Recurrent Neural Networks
May 24, 2016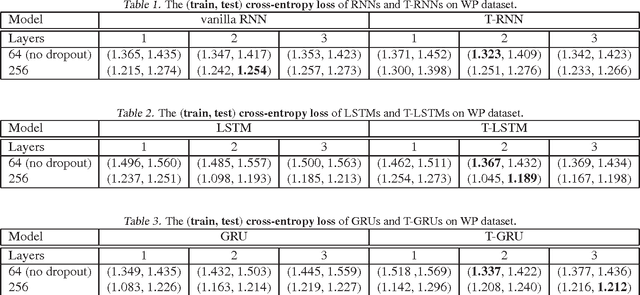
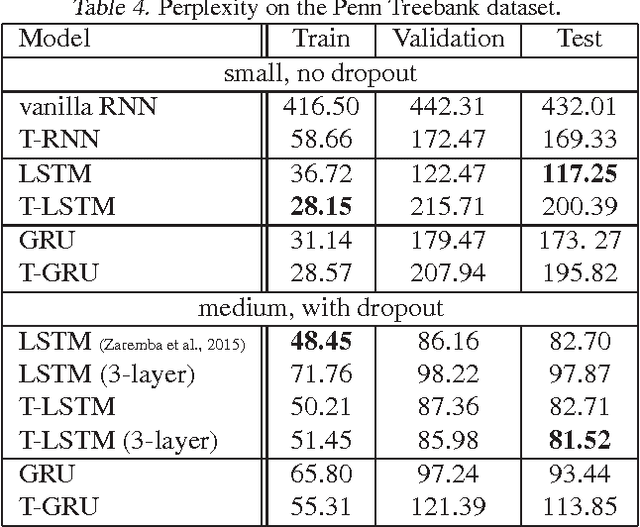
Recurrent neural networks are increasing popular models for sequential learning. Unfortunately, although the most effective RNN architectures are perhaps excessively complicated, extensive searches have not found simpler alternatives. This paper imports ideas from physics and functional programming into RNN design to provide guiding principles. From physics, we introduce type constraints, analogous to the constraints that forbids adding meters to seconds. From functional programming, we require that strongly-typed architectures factorize into stateless learnware and state-dependent firmware, reducing the impact of side-effects. The features learned by strongly-typed nets have a simple semantic interpretation via dynamic average-pooling on one-dimensional convolutions. We also show that strongly-typed gradients are better behaved than in classical architectures, and characterize the representational power of strongly-typed nets. Finally, experiments show that, despite being more constrained, strongly-typed architectures achieve lower training and comparable generalization error to classical architectures.
Compatible Value Gradients for Reinforcement Learning of Continuous Deep Policies
Sep 10, 2015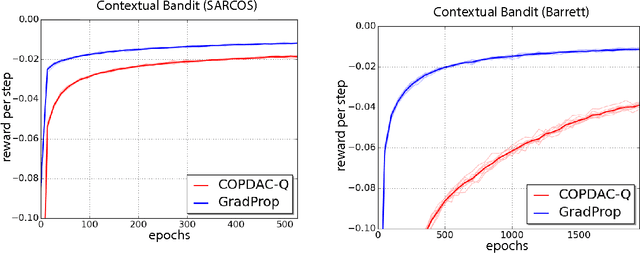
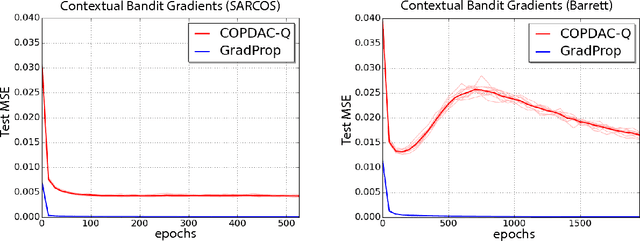
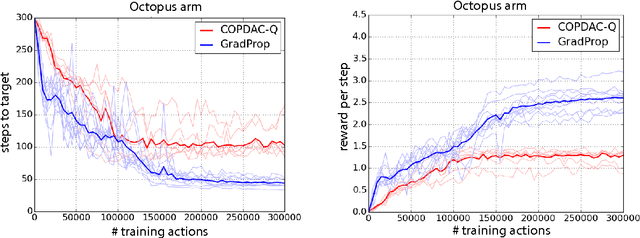
This paper proposes GProp, a deep reinforcement learning algorithm for continuous policies with compatible function approximation. The algorithm is based on two innovations. Firstly, we present a temporal-difference based method for learning the gradient of the value-function. Secondly, we present the deviator-actor-critic (DAC) model, which comprises three neural networks that estimate the value function, its gradient, and determine the actor's policy respectively. We evaluate GProp on two challenging tasks: a contextual bandit problem constructed from nonparametric regression datasets that is designed to probe the ability of reinforcement learning algorithms to accurately estimate gradients; and the octopus arm, a challenging reinforcement learning benchmark. GProp is competitive with fully supervised methods on the bandit task and achieves the best performance to date on the octopus arm.
Domain Generalization for Object Recognition with Multi-task Autoencoders
Aug 31, 2015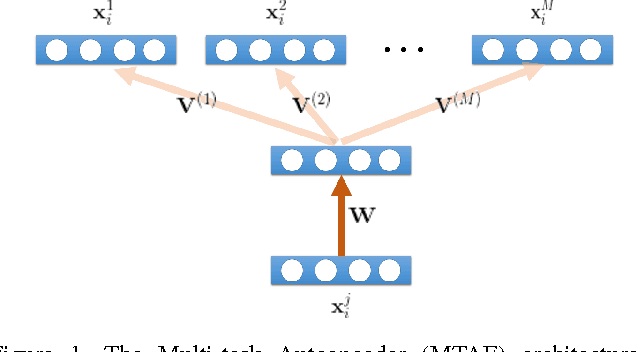
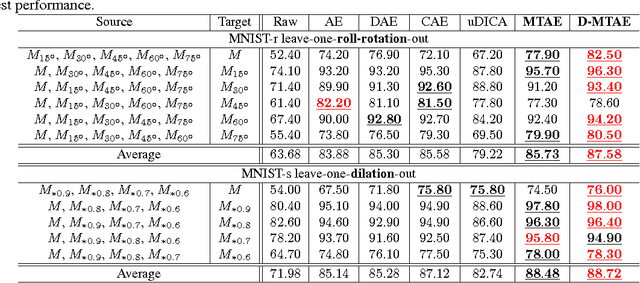

The problem of domain generalization is to take knowledge acquired from a number of related domains where training data is available, and to then successfully apply it to previously unseen domains. We propose a new feature learning algorithm, Multi-Task Autoencoder (MTAE), that provides good generalization performance for cross-domain object recognition. Our algorithm extends the standard denoising autoencoder framework by substituting artificially induced corruption with naturally occurring inter-domain variability in the appearance of objects. Instead of reconstructing images from noisy versions, MTAE learns to transform the original image into analogs in multiple related domains. It thereby learns features that are robust to variations across domains. The learnt features are then used as inputs to a classifier. We evaluated the performance of the algorithm on benchmark image recognition datasets, where the task is to learn features from multiple datasets and to then predict the image label from unseen datasets. We found that (denoising) MTAE outperforms alternative autoencoder-based models as well as the current state-of-the-art algorithms for domain generalization.
Domain Adaptive Neural Networks for Object Recognition
Sep 21, 2014
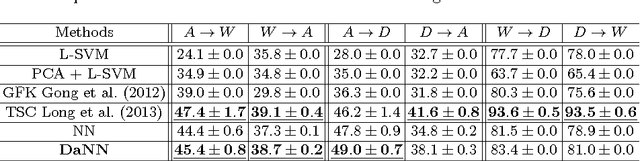


We propose a simple neural network model to deal with the domain adaptation problem in object recognition. Our model incorporates the Maximum Mean Discrepancy (MMD) measure as a regularization in the supervised learning to reduce the distribution mismatch between the source and target domains in the latent space. From experiments, we demonstrate that the MMD regularization is an effective tool to provide good domain adaptation models on both SURF features and raw image pixels of a particular image data set. We also show that our proposed model, preceded by the denoising auto-encoder pretraining, achieves better performance than recent benchmark models on the same data sets. This work represents the first study of MMD measure in the context of neural networks.