 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompatible Value Gradients for Reinforcement Learning of Continuous Deep Policies
Paper and Code
Sep 10, 2015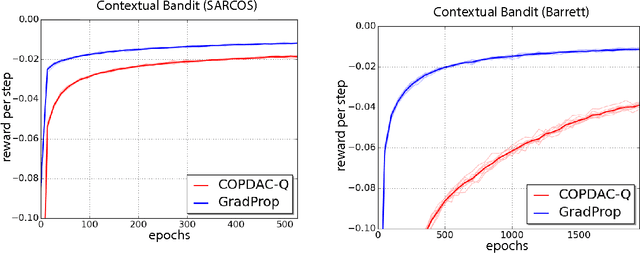
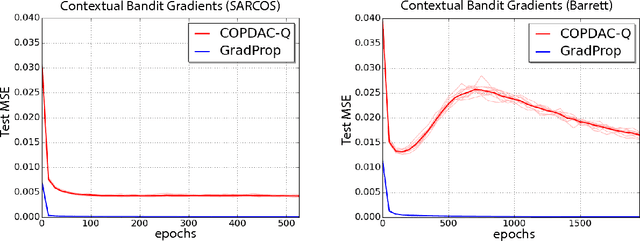
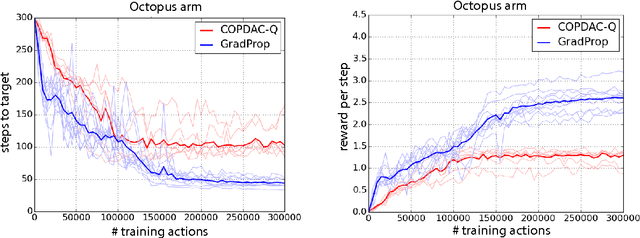
This paper proposes GProp, a deep reinforcement learning algorithm for continuous policies with compatible function approximation. The algorithm is based on two innovations. Firstly, we present a temporal-difference based method for learning the gradient of the value-function. Secondly, we present the deviator-actor-critic (DAC) model, which comprises three neural networks that estimate the value function, its gradient, and determine the actor's policy respectively. We evaluate GProp on two challenging tasks: a contextual bandit problem constructed from nonparametric regression datasets that is designed to probe the ability of reinforcement learning algorithms to accurately estimate gradients; and the octopus arm, a challenging reinforcement learning benchmark. GProp is competitive with fully supervised methods on the bandit task and achieves the best performance to date on the octopus arm.