 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeePAQ: A Perceptual Audio Quality Metric Based On Foundational Models and Weakly Supervised Learning
Oct 14, 2025This paper presents the Deep learning-based Perceptual Audio Quality metric (DeePAQ) for evaluating general audio quality. Our approach leverages metric learning together with the music foundation model MERT, guided by surrogate labels, to construct an embedding space that captures distortion intensity in general audio. To the best of our knowledge, DeePAQ is the first in the general audio quality domain to leverage weakly supervised labels and metric learning for fine-tuning a music foundation model with Low-Rank Adaptation (LoRA), a direction not yet explored by other state-of-the-art methods. We benchmark the proposed model against state-of-the-art objective audio quality metrics across listening tests spanning audio coding and source separation. Results show that our method surpasses existing metrics in detecting coding artifacts and generalizes well to unseen distortions such as source separation, highlighting its robustness and versatility.
Perceptual Audio Coding: A 40-Year Historical Perspective
Apr 22, 2025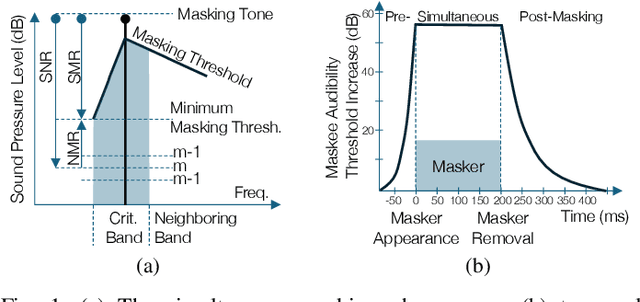



In the history of audio and acoustic signal processing, perceptual audio coding has certainly excelled as a bright success story by its ubiquitous deployment in virtually all digital media devices, such as computers, tablets, mobile phones, set-top-boxes, and digital radios. From a technology perspective, perceptual audio coding has undergone tremendous development from the first very basic perceptually driven coders (including the popular mp3 format) to today's full-blown integrated coding/rendering systems. This paper provides a historical overview of this research journey by pinpointing the pivotal development steps in the evolution of perceptual audio coding. Finally, it provides thoughts about future directions in this area.
Towards Improved Objective Perceptual Audio Quality Assessment -- Part 1: A Novel Data-Driven Cognitive Model
Nov 27, 2024Efficient audio quality assessment is vital for streamlining audio codec development. Objective assessment tools have been developed over time to algorithmically predict quality ratings from subjective assessments, the gold standard for quality judgment. Many of these tools use perceptual auditory models to extract audio features that are mapped to a basic audio quality score prediction using machine learning algorithms and subjective scores as training data. However, existing tools struggle with generalization in quality prediction, especially when faced with unknown signal and distortion types. This is particularly evident in the presence of signals coded using non-waveform-preserving parametric techniques. Addressing these challenges, this two-part work proposes extensions to the Perceptual Evaluation of Audio Quality (PEAQ - ITU-R BS.1387-1) recommendation. Part 1 focuses on increasing generalization, while Part 2 targets accurate spatial audio quality measurement in audio coding. To enhance prediction generalization, this paper (Part 1) introduces a novel machine learning approach that uses subjective data to model cognitive aspects of audio quality perception. The proposed method models the perceived severity of audible distortions by adaptively weighting different distortion metrics. The weights are determined using an interaction cost function that captures relationships between distortion salience and cognitive effects. Compared to other machine learning methods and established tools, the proposed architecture achieves higher prediction accuracy on large databases of previously unseen subjective quality scores. The perceptually-motivated model offers a more manageable alternative to general-purpose machine learning algorithms, allowing potential extensions and improvements to multi-dimensional quality measurement without complete retraining.
* Accepter for publication in in IEEE/ACM Transactions on Audio, Speech, and Language Processing
An Improved Metric of Informational Masking for Perceptual Audio Quality Measurement
Jul 13, 2023Perceptual audio quality measurement systems algorithmically analyze the output of audio processing systems to estimate possible perceived quality degradation using perceptual models of human audition. In this manner, they save the time and resources associated with the design and execution of listening tests (LTs). Models of disturbance audibility predicting peripheral auditory masking in quality measurement systems have considerably increased subjective quality prediction performance of signals processed by perceptual audio codecs. Additionally, cognitive effects have also been known to regulate perceived distortion severity by influencing their salience. However, the performance gains due to cognitive effect models in quality measurement systems were inconsistent so far, particularly for music signals. Firstly, this paper presents an improved model of informational masking (IM) -- an important cognitive effect in quality perception -- that considers disturbance information complexity around the masking threshold. Secondly, we incorporate the proposed IM metric into a quality measurement systems using a novel interaction analysis procedure between cognitive effects and distortion metrics. The procedure establishes interactions between cognitive effects and distortion metrics using LT data. The proposed IM metric is shown to outperform previously proposed IM metrics in a validation task against subjective quality scores from large and diverse LT databases. Particularly, the proposed system showed an increased quality prediction of music signals coded with bandwidth extension techniques, where other models frequently fail.
A Data-driven Cognitive Salience Model for Objective Perceptual Audio Quality Assessment
Dec 08, 2022Objective audio quality measurement systems often use perceptual models to predict the subjective quality scores of processed signals, as reported in listening tests. Most systems map different metrics of perceived degradation into a single quality score predicting subjective quality. This requires a quality mapping stage that is informed by real listening test data using statistical learning (i.e., a data-driven approach) with distortion metrics as input features. However, the amount of reliable training data is limited in practice, and usually not sufficient for a comprehensive training of large learning models. Models of cognitive effects in objective systems can, however, improve the learning model. Specifically, considering the salience of certain distortion types, they provide additional features to the mapping stage that improve the learning process, especially for limited amounts of training data. We propose a novel data-driven salience model that informs the quality mapping stage by explicitly estimating the cognitive/degradation metric interactions using a salience measure. Systems incorporating the novel salience model are shown to outperform equivalent systems that only use statistical learning to combine cognitive and degradation metrics, as well as other well-known measurement systems, for a representative validation dataset.
* Accepted version of the paper submitted to ICASSP 2020
Can we still use PEAQ? A Performance Analysis of the ITU Standard for the Objective Assessment of Perceived Audio Quality
Dec 02, 2022



The Perceptual Evaluation of Audio Quality (PEAQ) method as described in the International Telecommunication Union (ITU) recommendation ITU-R BS.1387 has been widely used for computationally estimating the quality of perceptually coded audio signals without the need for extensive subjective listening tests. However, many reports have highlighted clear limitations of the scheme after the end of its standardization, particularly involving signals coded with newer technologies such as bandwidth extension or parametric multi-channel coding. Until now, no other method for measuring the quality of both speech and audio signals has been standardized by the ITU. Therefore, a further investigation of the causes for these limitations would be beneficial to a possible update of said scheme. Our experimental results indicate that the performance of PEAQ's model of disturbance loudness is still as good as (and sometimes superior to) other state-of-the-art objective measures, albeit with varying performance depending on the type of degraded signal content (i.e. speech or music). This finding evidences the need for an improved cognitive model. In addition, results indicate that an updated mapping of Model Output Values (MOVs) to PEAQ's Distortion Index (DI) based on newer training data can greatly improve performance. Finally, some suggestions for the improvement of PEAQ are provided based on the reported results and comparison to other systems.
* Accepter manuscript for 2020 Twelfth International Conference on Quality of Multimedia Experience (QoMEX 2020)
Investigations on the Influence of Combined Inter-Aural Cue Distortions on Overall Audio Quality
Dec 02, 2022There is a considerable interest in developing algorithms that can predict audio quality of perceptually coded signals to avoid the cost of extensive listening tests during development time. While many established algorithms for predicting the perceived quality of signals with monaural (timbral) distortions are available (PEAQ, POLQA), predicting the quality degradation of stereo and multi-channel spatial signals is still considered a challenge. Audio quality degradation arising from spatial distortions is usually measured in terms of well known inter-aural cue distortion measures such as Inter-aural Level Difference Distortions (ILDD), Inter-aural Time Difference Distortions (ITDD) and Inter-aural Cross Correlation Distortions (IACCD). However, the extent to which their interaction influences the overall audio quality degradation in complex signals as expressed - for example - in a multiple stimuli test is not yet thoroughly studied. We propose a systematic approach that introduces controlled combinations of spatial distortions on a representative set of signals and evaluates their influence on overall perceived quality degradation by analyzing listening test scores over said signals. From this study we derive guidelines for designing meaningful distortion measures that consider inter-aural cue distortion interactions.
* A previous version of this paper (minus errata) was presented at Fortschritte der Akustik - DAGA 2019 (Rostock, Germany)
Objective Assessment of Spatial Audio Quality using Directional Loudness Maps
Dec 02, 2022This work introduces a feature extracted from stereophonic/binaural audio signals aiming to represent a measure of perceived quality degradation in processed spatial auditory scenes. The feature extraction technique is based on a simplified stereo signal model considering auditory events positioned towards a given direction in the stereo field using amplitude panning (AP) techniques. We decompose the stereo signal into a set of directional signals for given AP values in the Short-Time Fourier Transform domain and calculate their overall loudness to form a directional loudness representation or maps. Then, we compare directional loudness maps of a reference signal and a deteriorated version to derive a distortion measure aiming to describe the associated perceived degradation scores reported in listening tests. The measure is then tested on an extensive listening test database with stereo signals processed by state-of-the-art perceptual audio codecs using non waveform-preserving techniques such as bandwidth extension and joint stereo coding, known for presenting a challenge to existing quality predictors. Results suggest that the derived distortion measure can be incorporated as an extension to existing automated perceptual quality assessment algorithms for improving prediction on spatially coded audio signals.
* Accepted paper at ICASSP 2019
Objective Measures of Perceptual Audio Quality Reviewed: An Evaluation of Their Application Domain Dependence
Oct 21, 2021
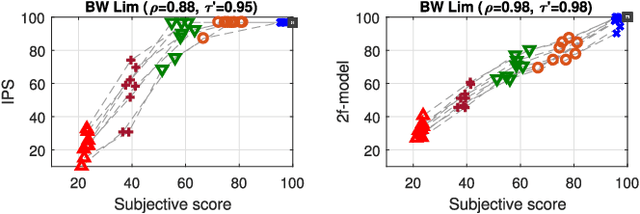
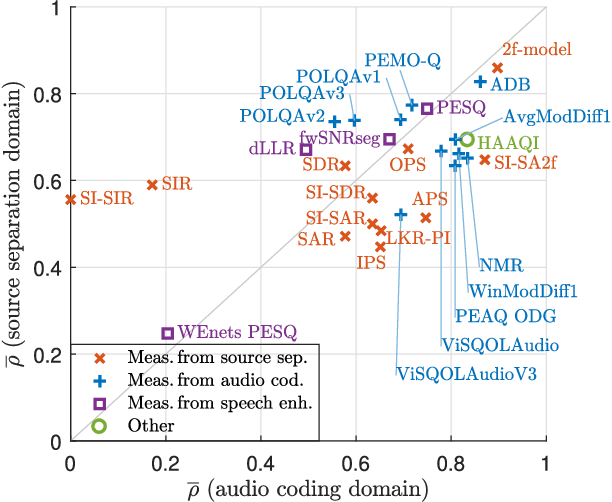

Over the past few decades, computational methods have been developed to estimate perceptual audio quality. These methods, also referred to as objective quality measures, are usually developed and intended for a specific application domain. Because of their convenience, they are often used outside their original intended domain, even if it is unclear whether they provide reliable quality estimates in this case. This work studies the correlation of well-known state-of-the-art objective measures with human perceptual scores in two different domains: audio coding and source separation. The following objective measures are considered: fwSNRseg, dLLR, PESQ, PEAQ, POLQA, PEMO-Q, ViSQOLAudio, (SI-)BSSEval, PEASS, LKR-PI, 2f-model, and HAAQI. Additionally, a novel measure (SI-SA2f) is presented, based on the 2f-model and a BSSEval-based signal decomposition. We use perceptual scores from 7 listening tests about audio coding and 7 listening tests about source separation as ground-truth data for the correlation analysis. The results show that one method (2f-model) performs significantly better than the others on both domains and indicate that the dataset for training the method and a robust underlying auditory model are crucial factors towards a universal, domain-independent objective measure.