 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjective Measures of Perceptual Audio Quality Reviewed: An Evaluation of Their Application Domain Dependence
Oct 21, 2021
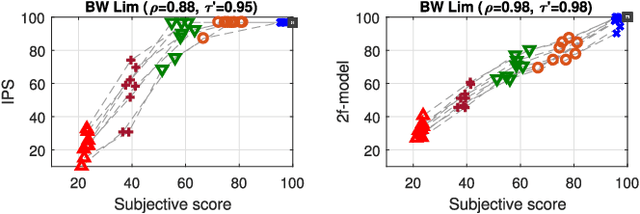
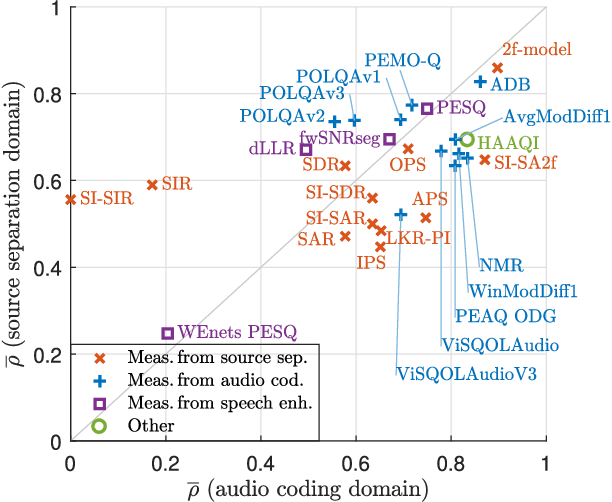

Over the past few decades, computational methods have been developed to estimate perceptual audio quality. These methods, also referred to as objective quality measures, are usually developed and intended for a specific application domain. Because of their convenience, they are often used outside their original intended domain, even if it is unclear whether they provide reliable quality estimates in this case. This work studies the correlation of well-known state-of-the-art objective measures with human perceptual scores in two different domains: audio coding and source separation. The following objective measures are considered: fwSNRseg, dLLR, PESQ, PEAQ, POLQA, PEMO-Q, ViSQOLAudio, (SI-)BSSEval, PEASS, LKR-PI, 2f-model, and HAAQI. Additionally, a novel measure (SI-SA2f) is presented, based on the 2f-model and a BSSEval-based signal decomposition. We use perceptual scores from 7 listening tests about audio coding and 7 listening tests about source separation as ground-truth data for the correlation analysis. The results show that one method (2f-model) performs significantly better than the others on both domains and indicate that the dataset for training the method and a robust underlying auditory model are crucial factors towards a universal, domain-independent objective measure.
Controlling the Remixing of Separated Dialogue with a Non-Intrusive Quality Estimate
Jul 21, 2021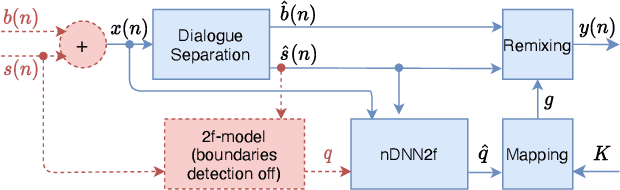
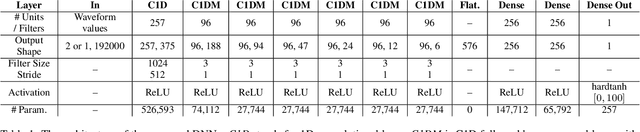

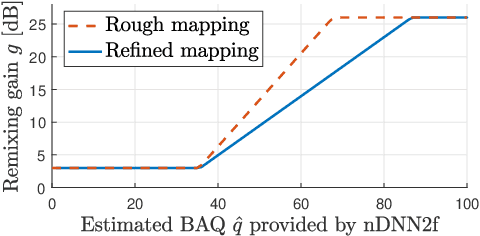
Remixing separated audio sources trades off interferer attenuation against the amount of audible deteriorations. This paper proposes a non-intrusive audio quality estimation method for controlling this trade-off in a signal-adaptive manner. The recently proposed 2f-model is adopted as the underlying quality measure, since it has been shown to correlate strongly with basic audio quality in source separation. An alternative operation mode of the measure is proposed, more appropriate when considering material with long inactive periods of the target source. The 2f-model requires the reference target source as an input, but this is not available in many applications. Deep neural networks (DNNs) are trained to estimate the 2f-model intrusively using the reference target (iDNN2f), non-intrusively using the input mix as reference (nDNN2f), and reference-free using only the separated output signal (rDNN2f). It is shown that iDNN2f achieves very strong correlation with the original measure on the test data (Pearson r=0.99), while performance decreases for nDNN2f (r>=0.91) and rDNN2f (r>=0.82). The non-intrusive estimate nDNN2f is mapped to select item-dependent remixing gains with the aim of maximizing the interferer attenuation under a constraint on the minimum quality of the remixed output (e.g., audible but not annoying deteriorations). A listening test shows that this is successfully achieved even with very different selected gains (up to 23 dB difference).