 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometrically-Motivated Primary-Ambient Decomposition With Center-Channel Extraction
Jun 05, 2022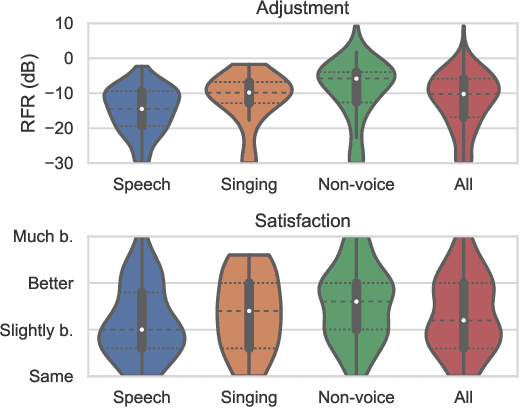
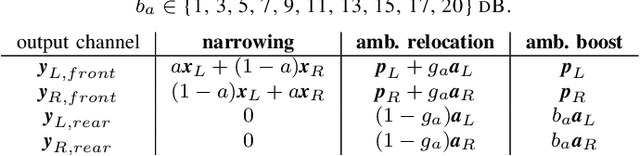
A geometrically-motivated method for primary-ambient decomposition is proposed and evaluated in an up-mixing application. The method consists of two steps, accommodating a particularly intuitive explanation. The first step consists of signal-adaptive rotations applied on the input stereo scene, which translate the primary sound sources into the center of the rotated scene. The second step applies a center-channel extraction method, based on a simple signal model and optimal in the mean-squared-error sense. The performance is evaluated by using the estimated ambient component to enable surround sound starting from real-world stereo signals. The participants in the reported listening test are asked to adjust the audio scene envelopment and find the audio settings that pleases them the most. The possibility for up-mixing enabled by the proposed method is used extensively, and the user satisfaction is significantly increased compared to the original stereo mix.
Sampling Frequency Independent Dialogue Separation
Jun 05, 2022

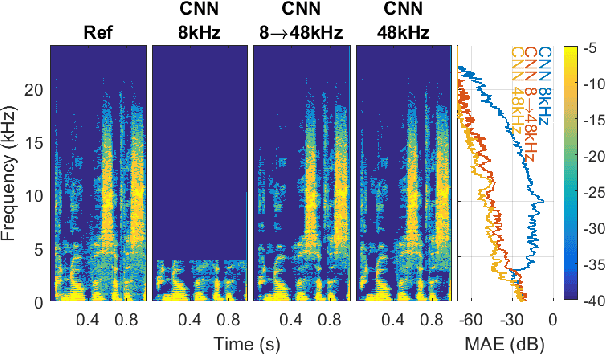
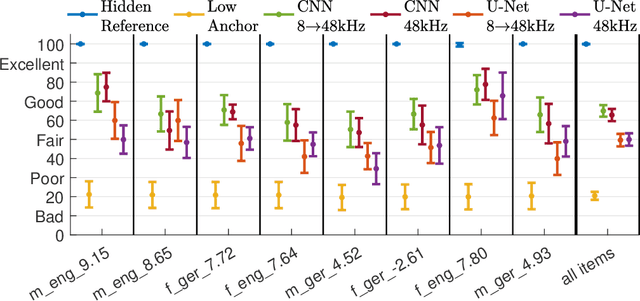
In some DNNs for audio source separation, the relevant model parameters are independent of the sampling frequency of the audio used for training. Considering the application of dialogue separation, this is shown for two DNN architectures: a U-Net and a fully-convolutional model. The models are trained with audio sampled at 8 kHz. The learned parameters are transferred to models for processing audio at 48 kHz. The separated audio sources are compared with the ones produced by the same model architectures trained with 48 kHz versions of the same training data. A listening test and computational measures show that there is no significant perceptual difference between the models trained with 8 kHz or with 48 kHz. This transferability of the learned parameters allows for a faster and computationally less costly training. It also enables using training datasets available at a lower sampling frequency than the one needed by the application at hand, or using data collections with multiple sampling frequencies.
Dialog+ in Broadcasting: First Field Tests Using Deep-Learning-Based Dialogue Enhancement
Dec 17, 2021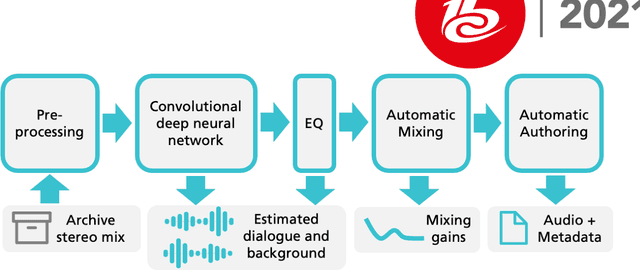
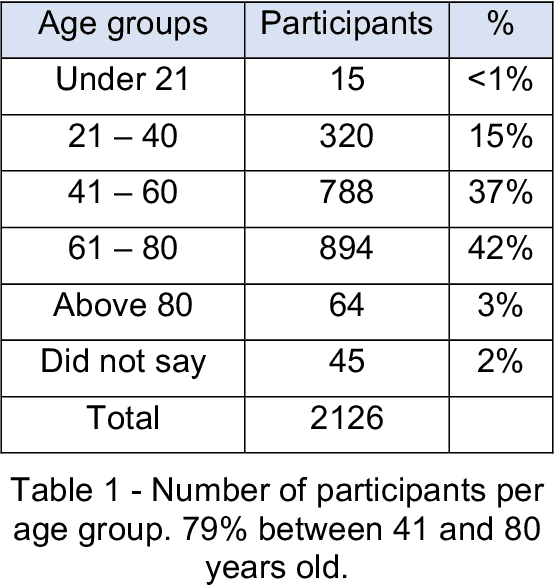

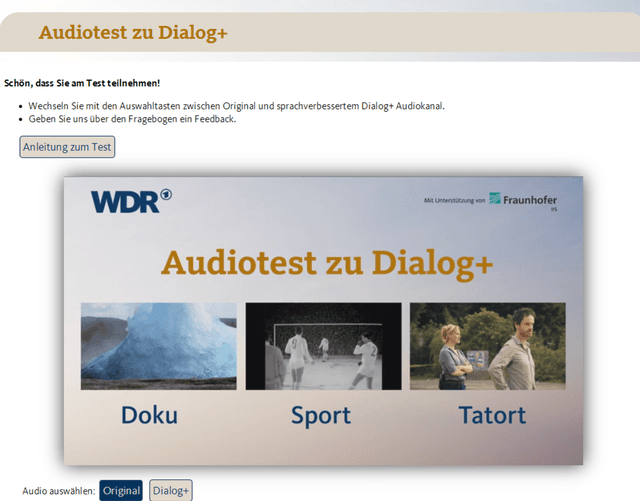
Difficulties in following speech due to loud background sounds are common in broadcasting. Object-based audio, e.g., MPEG-H Audio solves this problem by providing a user-adjustable speech level. While object-based audio is gaining momentum, transitioning to it requires time and effort. Also, lots of content exists, produced and archived outside the object-based workflows. To address this, Fraunhofer IIS has developed a deep-learning solution called Dialog+, capable of enabling speech level personalization also for content with only the final audio tracks available. This paper reports on public field tests evaluating Dialog+, conducted together with Westdeutscher Rundfunk (WDR) and Bayerischer Rundfunk (BR), starting from September 2020. To our knowledge, these are the first large-scale tests of this kind. As part of one of these, a survey with more than 2,000 participants showed that 90% of the people above 60 years old have problems in understanding speech in TV "often" or "very often". Overall, 83% of the participants liked the possibility to switch to Dialog+, including those who do not normally struggle with speech intelligibility. Dialog+ introduces a clear benefit for the audience, filling the gap between object-based broadcasting and traditionally produced material.
Controlling the Perceived Sound Quality for Dialogue Enhancement with Deep Learning
Jul 22, 2021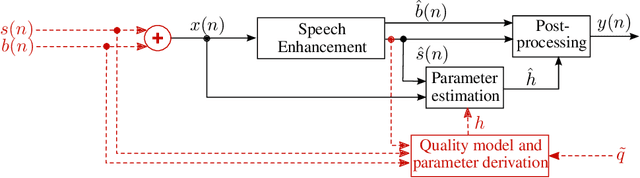

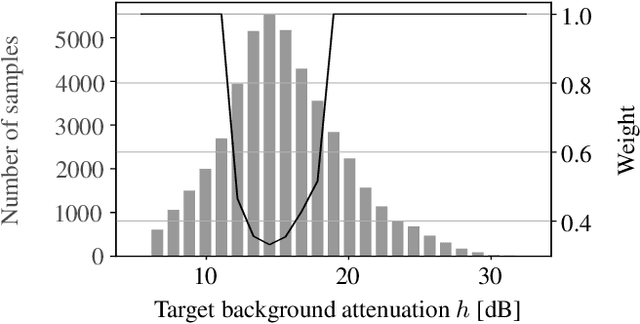
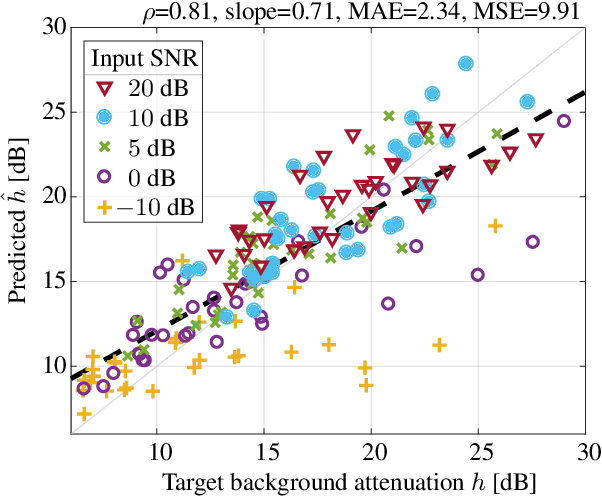
Speech enhancement attenuates interfering sounds in speech signals but may introduce artifacts that perceivably deteriorate the output signal. We propose a method for controlling the trade-off between the attenuation of the interfering background signal and the loss of sound quality. A deep neural network estimates the attenuation of the separated background signal such that the sound quality, quantified using the Artifact-related Perceptual Score, meets an adjustable target. Subjective evaluations indicate that consistent sound quality is obtained across various input signals. Our experiments show that the proposed method is able to control the trade-off with an accuracy that is adequate for real-world dialogue enhancement applications.
* Accepted paper at ICASSP 2020
Controlling the Remixing of Separated Dialogue with a Non-Intrusive Quality Estimate
Jul 21, 2021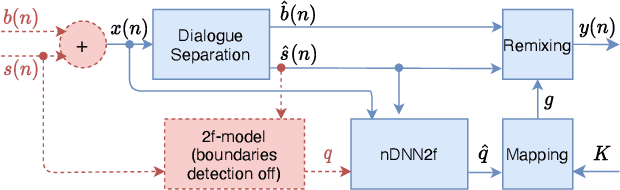

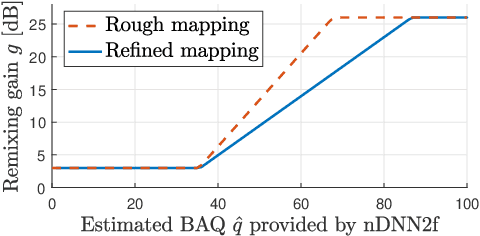
Remixing separated audio sources trades off interferer attenuation against the amount of audible deteriorations. This paper proposes a non-intrusive audio quality estimation method for controlling this trade-off in a signal-adaptive manner. The recently proposed 2f-model is adopted as the underlying quality measure, since it has been shown to correlate strongly with basic audio quality in source separation. An alternative operation mode of the measure is proposed, more appropriate when considering material with long inactive periods of the target source. The 2f-model requires the reference target source as an input, but this is not available in many applications. Deep neural networks (DNNs) are trained to estimate the 2f-model intrusively using the reference target (iDNN2f), non-intrusively using the input mix as reference (nDNN2f), and reference-free using only the separated output signal (rDNN2f). It is shown that iDNN2f achieves very strong correlation with the original measure on the test data (Pearson r=0.99), while performance decreases for nDNN2f (r>=0.91) and rDNN2f (r>=0.82). The non-intrusive estimate nDNN2f is mapped to select item-dependent remixing gains with the aim of maximizing the interferer attenuation under a constraint on the minimum quality of the remixed output (e.g., audible but not annoying deteriorations). A listening test shows that this is successfully achieved even with very different selected gains (up to 23 dB difference).
A Hands-on Comparison of DNNs for Dialog Separation Using Transfer Learning from Music Source Separation
Jun 22, 2021
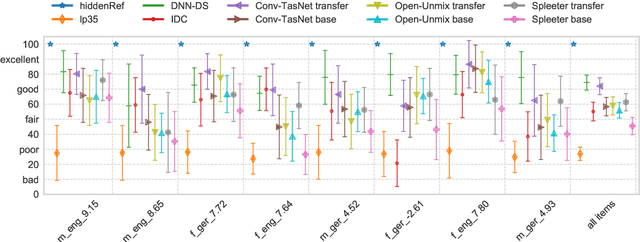
This paper describes a hands-on comparison on using state-of-the-art music source separation deep neural networks (DNNs) before and after task-specific fine-tuning for separating speech content from non-speech content in broadcast audio (i.e., dialog separation). The music separation models are selected as they share the number of channels (2) and sampling rate (44.1 kHz or higher) with the considered broadcast content, and vocals separation in music is considered as a parallel for dialog separation in the target application domain. These similarities are assumed to enable transfer learning between the tasks. Three models pre-trained on music (Open-Unmix, Spleeter, and Conv-TasNet) are considered in the experiments, and fine-tuned with real broadcast data. The performance of the models is evaluated before and after fine-tuning with computational evaluation metrics (SI-SIRi, SI-SDRi, 2f-model), as well as with a listening test simulating an application where the non-speech signal is partially attenuated, e.g., for better speech intelligibility. The evaluations include two reference systems specifically developed for dialog separation. The results indicate that pre-trained music source separation models can be used for dialog separation to some degree, and that they benefit from the fine-tuning, reaching a performance close to task-specific solutions.