 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSampling Frequency Independent Dialogue Separation
Paper and Code
Jun 05, 2022

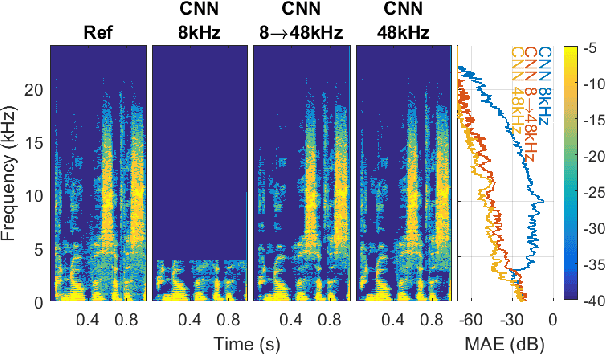
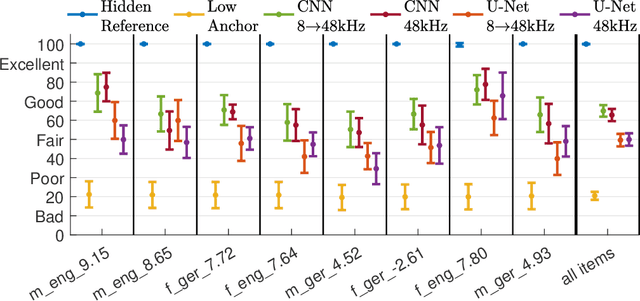
In some DNNs for audio source separation, the relevant model parameters are independent of the sampling frequency of the audio used for training. Considering the application of dialogue separation, this is shown for two DNN architectures: a U-Net and a fully-convolutional model. The models are trained with audio sampled at 8 kHz. The learned parameters are transferred to models for processing audio at 48 kHz. The separated audio sources are compared with the ones produced by the same model architectures trained with 48 kHz versions of the same training data. A listening test and computational measures show that there is no significant perceptual difference between the models trained with 8 kHz or with 48 kHz. This transferability of the learned parameters allows for a faster and computationally less costly training. It also enables using training datasets available at a lower sampling frequency than the one needed by the application at hand, or using data collections with multiple sampling frequencies.