 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning for Day Forecasts from Sparse Observations
Jun 12, 2023



Deep neural networks offer an alternative paradigm for modeling weather conditions. The ability of neural models to make a prediction in less than a second once the data is available and to do so with very high temporal and spatial resolution, and the ability to learn directly from atmospheric observations, are just some of these models' unique advantages. Neural models trained using atmospheric observations, the highest fidelity and lowest latency data, have to date achieved good performance only up to twelve hours of lead time when compared with state-of-the-art probabilistic Numerical Weather Prediction models and only for the sole variable of precipitation. In this paper, we present MetNet-3 that extends significantly both the lead time range and the variables that an observation based neural model can predict well. MetNet-3 learns from both dense and sparse data sensors and makes predictions up to 24 hours ahead for precipitation, wind, temperature and dew point. MetNet-3 introduces a key densification technique that implicitly captures data assimilation and produces spatially dense forecasts in spite of the network training on extremely sparse targets. MetNet-3 has a high temporal and spatial resolution of, respectively, up to 2 minutes and 1 km as well as a low operational latency. We find that MetNet-3 is able to outperform the best single- and multi-member NWPs such as HRRR and ENS over the CONUS region for up to 24 hours ahead setting a new performance milestone for observation based neural models. MetNet-3 is operational and its forecasts are served in Google Search in conjunction with other models.
Skillful Twelve Hour Precipitation Forecasts using Large Context Neural Networks
Nov 14, 2021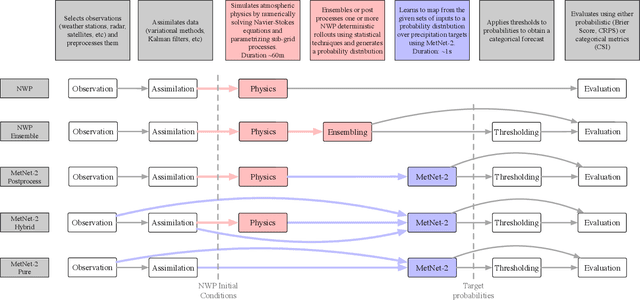
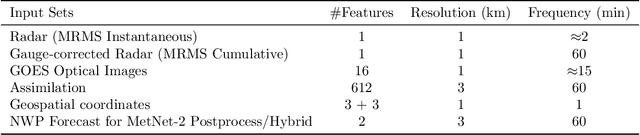
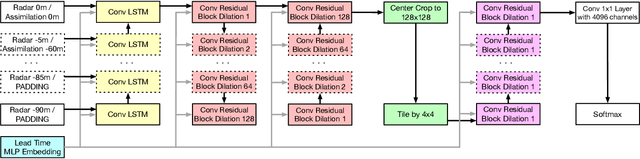

The problem of forecasting weather has been scientifically studied for centuries due to its high impact on human lives, transportation, food production and energy management, among others. Current operational forecasting models are based on physics and use supercomputers to simulate the atmosphere to make forecasts hours and days in advance. Better physics-based forecasts require improvements in the models themselves, which can be a substantial scientific challenge, as well as improvements in the underlying resolution, which can be computationally prohibitive. An emerging class of weather models based on neural networks represents a paradigm shift in weather forecasting: the models learn the required transformations from data instead of relying on hand-coded physics and are computationally efficient. For neural models, however, each additional hour of lead time poses a substantial challenge as it requires capturing ever larger spatial contexts and increases the uncertainty of the prediction. In this work, we present a neural network that is capable of large-scale precipitation forecasting up to twelve hours ahead and, starting from the same atmospheric state, the model achieves greater skill than the state-of-the-art physics-based models HRRR and HREF that currently operate in the Continental United States. Interpretability analyses reinforce the observation that the model learns to emulate advanced physics principles. These results represent a substantial step towards establishing a new paradigm of efficient forecasting with neural networks.
Boosting Search Engines with Interactive Agents
Sep 01, 2021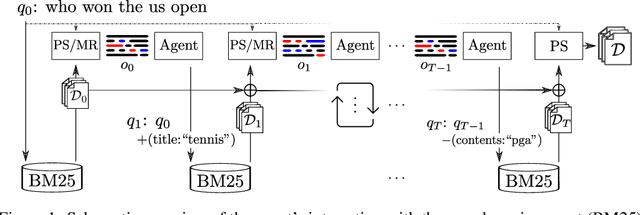
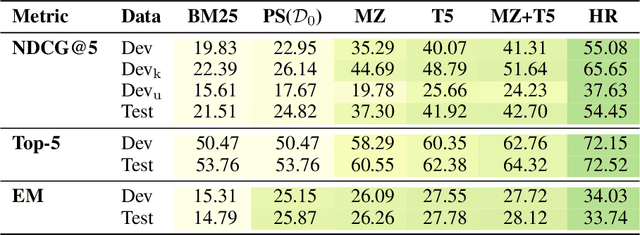
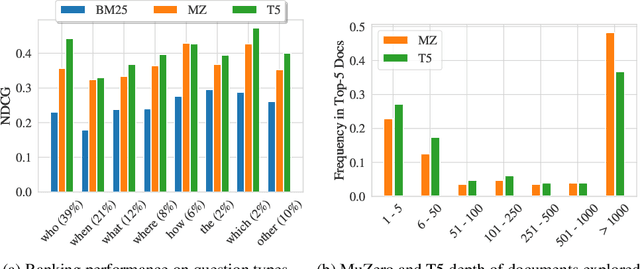

Can machines learn to use a search engine as an interactive tool for finding information? That would have far reaching consequences for making the world's knowledge more accessible. This paper presents first steps in designing agents that learn meta-strategies for contextual query refinements. Our approach uses machine reading to guide the selection of refinement terms from aggregated search results. Agents are then empowered with simple but effective search operators to exert fine-grained and transparent control over queries and search results. We develop a novel way of generating synthetic search sessions, which leverages the power of transformer-based generative language models through (self-)supervised learning. We also present a reinforcement learning agent with dynamically constrained actions that can learn interactive search strategies completely from scratch. In both cases, we obtain significant improvements over one-shot search with a strong information retrieval baseline. Finally, we provide an in-depth analysis of the learned search policies.
Agent-Centric Representations for Multi-Agent Reinforcement Learning
Apr 19, 2021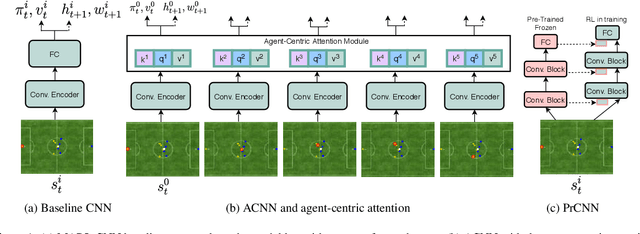

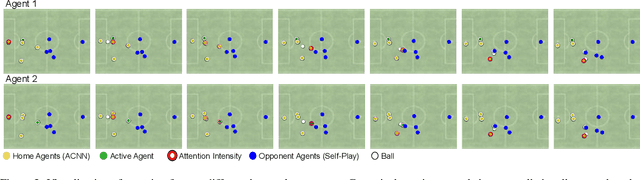

Object-centric representations have recently enabled significant progress in tackling relational reasoning tasks. By building a strong object-centric inductive bias into neural architectures, recent efforts have improved generalization and data efficiency of machine learning algorithms for these problems. One problem class involving relational reasoning that still remains under-explored is multi-agent reinforcement learning (MARL). Here we investigate whether object-centric representations are also beneficial in the fully cooperative MARL setting. Specifically, we study two ways of incorporating an agent-centric inductive bias into our RL algorithm: 1. Introducing an agent-centric attention module with explicit connections across agents 2. Adding an agent-centric unsupervised predictive objective (i.e. not using action labels), to be used as an auxiliary loss for MARL, or as the basis of a pre-training step. We evaluate these approaches on the Google Research Football environment as well as DeepMind Lab 2D. Empirically, agent-centric representation learning leads to the emergence of more complex cooperation strategies between agents as well as enhanced sample efficiency and generalization.
MetNet: A Neural Weather Model for Precipitation Forecasting
Mar 30, 2020Weather forecasting is a long standing scientific challenge with direct social and economic impact. The task is suitable for deep neural networks due to vast amounts of continuously collected data and a rich spatial and temporal structure that presents long range dependencies. We introduce MetNet, a neural network that forecasts precipitation up to 8 hours into the future at the high spatial resolution of 1 km$^2$ and at the temporal resolution of 2 minutes with a latency in the order of seconds. MetNet takes as input radar and satellite data and forecast lead time and produces a probabilistic precipitation map. The architecture uses axial self-attention to aggregate the global context from a large input patch corresponding to a million square kilometers. We evaluate the performance of MetNet at various precipitation thresholds and find that MetNet outperforms Numerical Weather Prediction at forecasts of up to 7 to 8 hours on the scale of the continental United States.
SEED RL: Scalable and Efficient Deep-RL with Accelerated Central Inference
Oct 15, 2019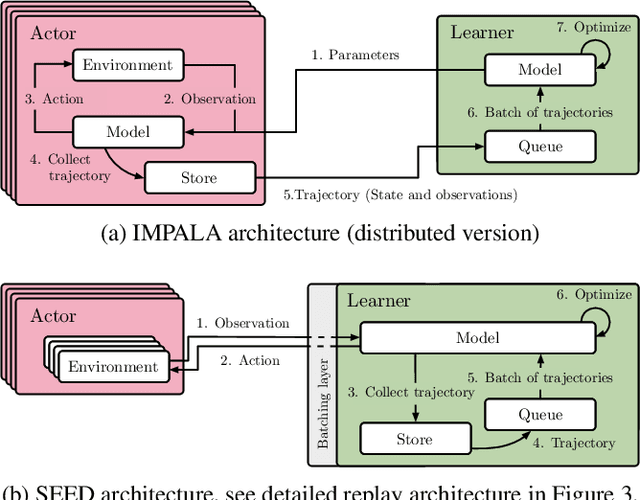
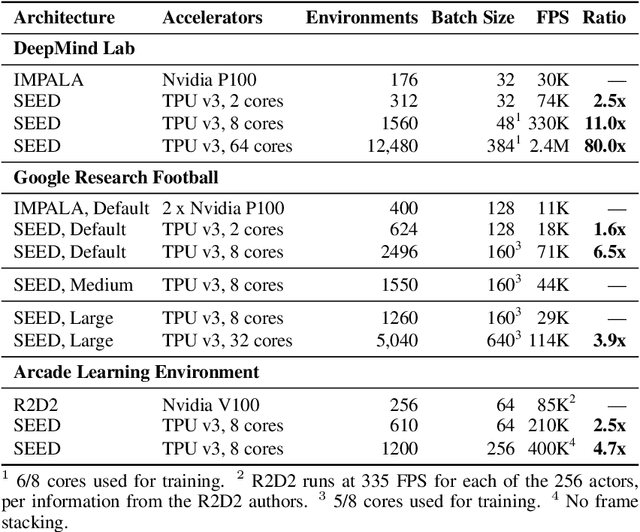
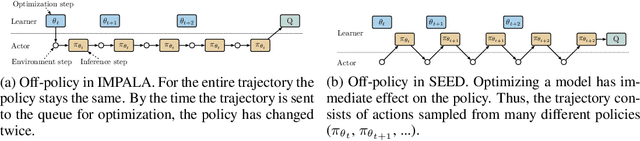
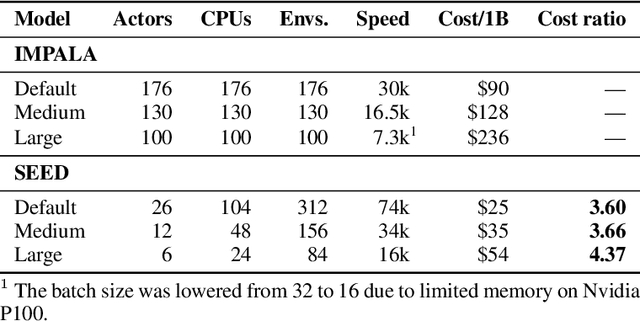
We present a modern scalable reinforcement learning agent called SEED (Scalable, Efficient Deep-RL). By effectively utilizing modern accelerators, we show that it is not only possible to train on millions of frames per second but also to lower the cost of experiments compared to current methods. We achieve this with a simple architecture that features centralized inference and an optimized communication layer. SEED adopts two state of the art distributed algorithms, IMPALA/V-trace (policy gradients) and R2D2 (Q-learning), and is evaluated on Atari-57, DeepMind Lab and Google Research Football. We improve the state of the art on Football and are able to reach state of the art on Atari-57 twice as fast in wall-time. For the scenarios we consider, a 40% to 80% cost reduction for running experiments is achieved. The implementation along with experiments is open-sourced so that results can be reproduced and novel ideas tried out.
Google Research Football: A Novel Reinforcement Learning Environment
Jul 25, 2019


Recent progress in the field of reinforcement learning has been accelerated by virtual learning environments such as video games, where novel algorithms and ideas can be quickly tested in a safe and reproducible manner. We introduce the Google Research Football Environment, a new reinforcement learning environment where agents are trained to play football in an advanced, physics-based 3D simulator. The resulting environment is challenging, easy to use and customize, and it is available under a permissive open-source license. In addition, it provides support for multiplayer and multi-agent experiments. We propose three full-game scenarios of varying difficulty with the Football Benchmarks and report baseline results for three commonly used reinforcement algorithms (IMPALA, PPO, and Ape-X DQN). We also provide a diverse set of simpler scenarios with the Football Academy and showcase several promising research directions.
Multi-task Deep Reinforcement Learning with PopArt
Sep 12, 2018
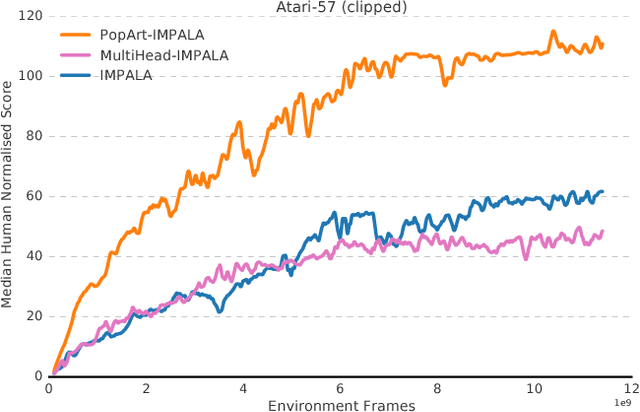

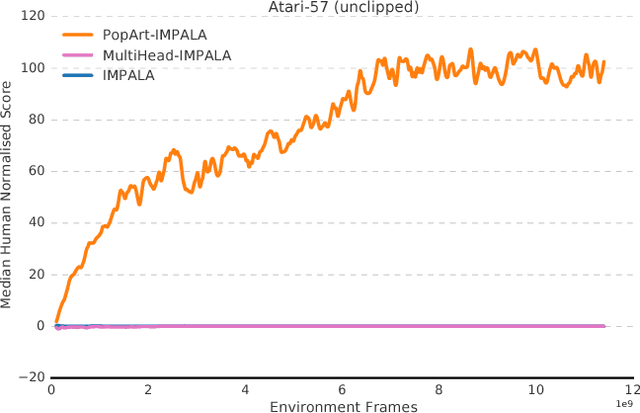
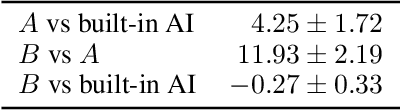
The reinforcement learning community has made great strides in designing algorithms capable of exceeding human performance on specific tasks. These algorithms are mostly trained one task at the time, each new task requiring to train a brand new agent instance. This means the learning algorithm is general, but each solution is not; each agent can only solve the one task it was trained on. In this work, we study the problem of learning to master not one but multiple sequential-decision tasks at once. A general issue in multi-task learning is that a balance must be found between the needs of multiple tasks competing for the limited resources of a single learning system. Many learning algorithms can get distracted by certain tasks in the set of tasks to solve. Such tasks appear more salient to the learning process, for instance because of the density or magnitude of the in-task rewards. This causes the algorithm to focus on those salient tasks at the expense of generality. We propose to automatically adapt the contribution of each task to the agent's updates, so that all tasks have a similar impact on the learning dynamics. This resulted in state of the art performance on learning to play all games in a set of 57 diverse Atari games. Excitingly, our method learned a single trained policy - with a single set of weights - that exceeds median human performance. To our knowledge, this was the first time a single agent surpassed human-level performance on this multi-task domain. The same approach also demonstrated state of the art performance on a set of 30 tasks in the 3D reinforcement learning platform DeepMind Lab.
IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures
Jun 28, 2018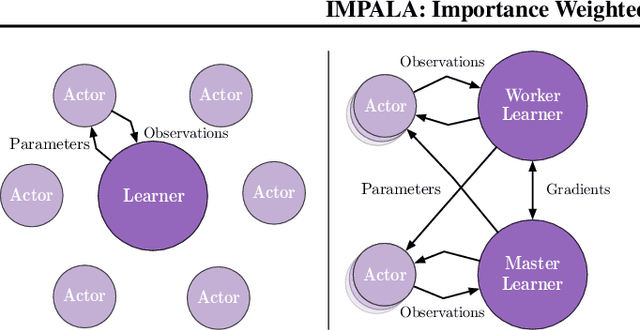
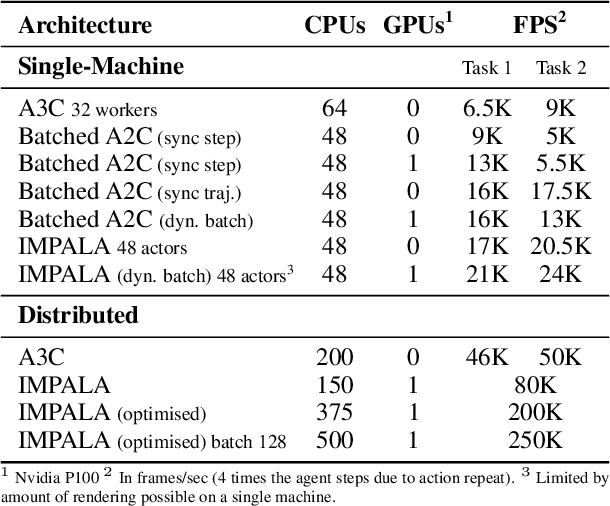
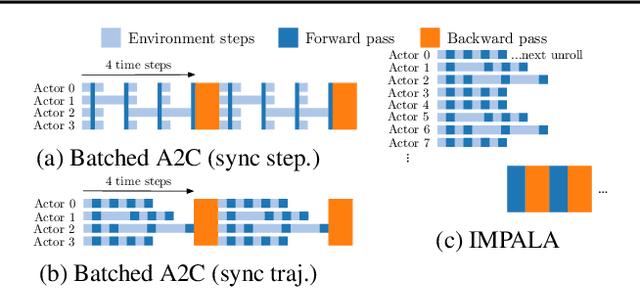
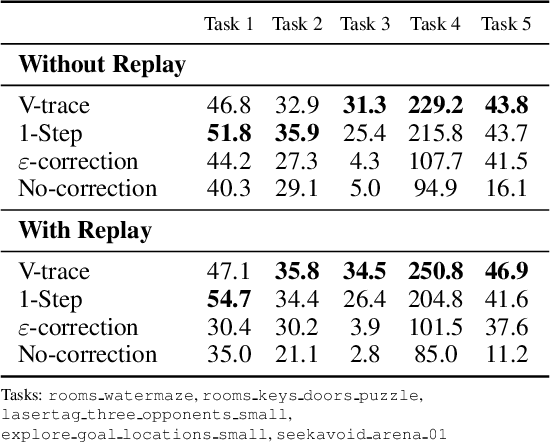
In this work we aim to solve a large collection of tasks using a single reinforcement learning agent with a single set of parameters. A key challenge is to handle the increased amount of data and extended training time. We have developed a new distributed agent IMPALA (Importance Weighted Actor-Learner Architecture) that not only uses resources more efficiently in single-machine training but also scales to thousands of machines without sacrificing data efficiency or resource utilisation. We achieve stable learning at high throughput by combining decoupled acting and learning with a novel off-policy correction method called V-trace. We demonstrate the effectiveness of IMPALA for multi-task reinforcement learning on DMLab-30 (a set of 30 tasks from the DeepMind Lab environment (Beattie et al., 2016)) and Atari-57 (all available Atari games in Arcade Learning Environment (Bellemare et al., 2013a)). Our results show that IMPALA is able to achieve better performance than previous agents with less data, and crucially exhibits positive transfer between tasks as a result of its multi-task approach.
Neural Machine Translation in Linear Time
Mar 15, 2017
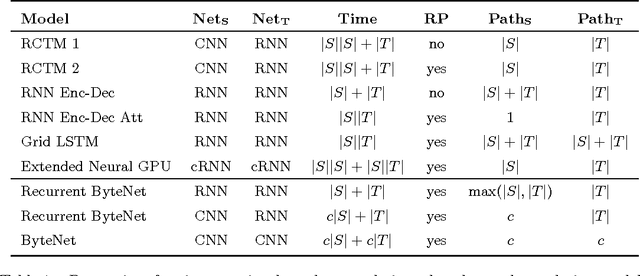


We present a novel neural network for processing sequences. The ByteNet is a one-dimensional convolutional neural network that is composed of two parts, one to encode the source sequence and the other to decode the target sequence. The two network parts are connected by stacking the decoder on top of the encoder and preserving the temporal resolution of the sequences. To address the differing lengths of the source and the target, we introduce an efficient mechanism by which the decoder is dynamically unfolded over the representation of the encoder. The ByteNet uses dilation in the convolutional layers to increase its receptive field. The resulting network has two core properties: it runs in time that is linear in the length of the sequences and it sidesteps the need for excessive memorization. The ByteNet decoder attains state-of-the-art performance on character-level language modelling and outperforms the previous best results obtained with recurrent networks. The ByteNet also achieves state-of-the-art performance on character-to-character machine translation on the English-to-German WMT translation task, surpassing comparable neural translation models that are based on recurrent networks with attentional pooling and run in quadratic time. We find that the latent alignment structure contained in the representations reflects the expected alignment between the tokens.