 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe CRINGE Loss: Learning what language not to model
Nov 10, 2022Standard language model training employs gold human documents or human-human interaction data, and treats all training data as positive examples. Growing evidence shows that even with very large amounts of positive training data, issues remain that can be alleviated with relatively small amounts of negative data -- examples of what the model should not do. In this work, we propose a novel procedure to train with such data called the CRINGE loss (ContRastive Iterative Negative GEneration). We show the effectiveness of this approach across three different experiments on the tasks of safe generation, contradiction avoidance, and open-domain dialogue. Our models outperform multiple strong baselines and are conceptually simple, easy to train and implement.
Language Models that Seek for Knowledge: Modular Search & Generation for Dialogue and Prompt Completion
Mar 29, 2022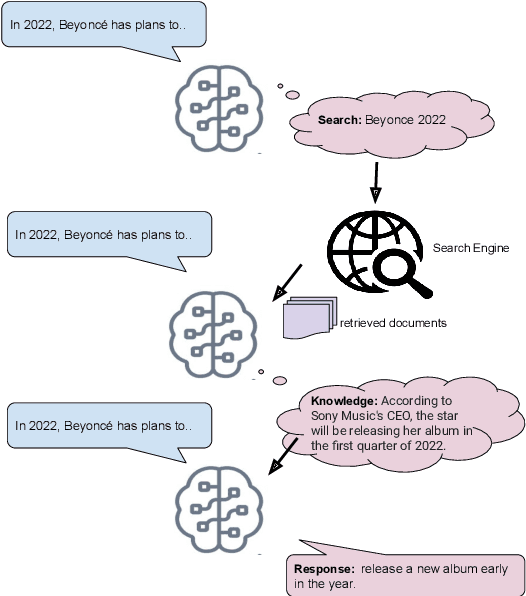

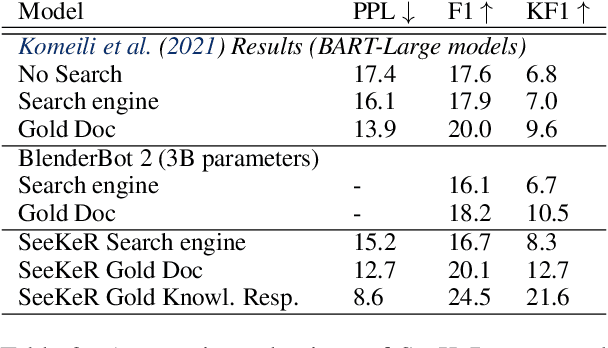

Language models (LMs) have recently been shown to generate more factual responses by employing modularity (Zhou et al., 2021) in combination with retrieval (Adolphs et al., 2021). We extend the recent approach of Adolphs et al. (2021) to include internet search as a module. Our SeeKeR (Search engine->Knowledge->Response) method thus applies a single LM to three modular tasks in succession: search, generating knowledge, and generating a final response. We show that, when using SeeKeR as a dialogue model, it outperforms the state-of-the-art model BlenderBot 2 (Chen et al., 2021) on open-domain knowledge-grounded conversations for the same number of parameters, in terms of consistency, knowledge and per-turn engagingness. SeeKeR applied to topical prompt completions as a standard language model outperforms GPT2 (Radford et al., 2019) and GPT3 (Brown et al., 2020) in terms of factuality and topicality, despite GPT3 being a vastly larger model. Our code and models are made publicly available.
Calibration of Machine Reading Systems at Scale
Mar 20, 2022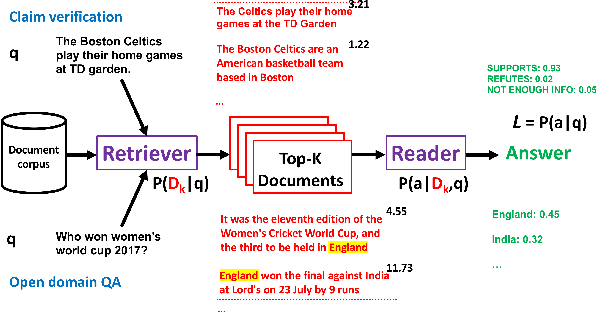
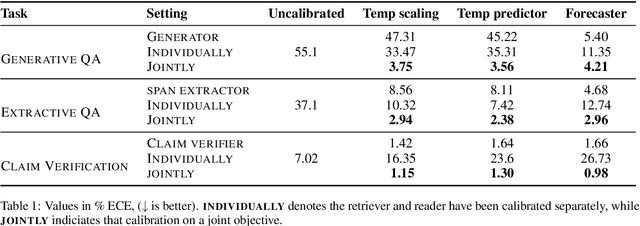

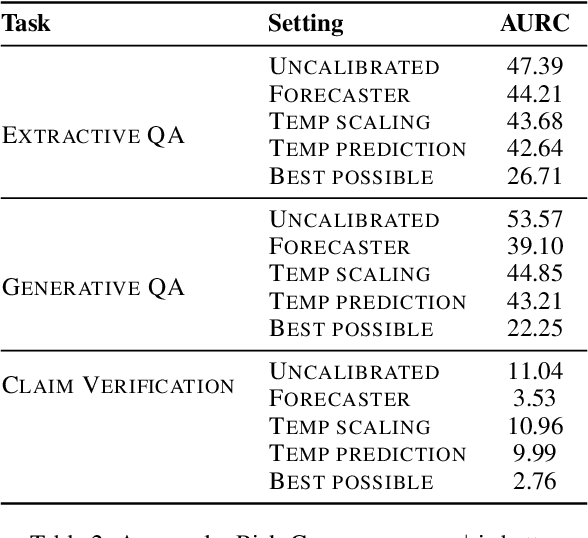
In typical machine learning systems, an estimate of the probability of the prediction is used to assess the system's confidence in the prediction. This confidence measure is usually uncalibrated; i.e.\ the system's confidence in the prediction does not match the true probability of the predicted output. In this paper, we present an investigation into calibrating open setting machine reading systems such as open-domain question answering and claim verification systems. We show that calibrating such complex systems which contain discrete retrieval and deep reading components is challenging and current calibration techniques fail to scale to these settings. We propose simple extensions to existing calibration approaches that allows us to adapt them to these settings. Our experimental results reveal that the approach works well, and can be useful to selectively predict answers when question answering systems are posed with unanswerable or out-of-the-training distribution questions.
Reason first, then respond: Modular Generation for Knowledge-infused Dialogue
Nov 09, 2021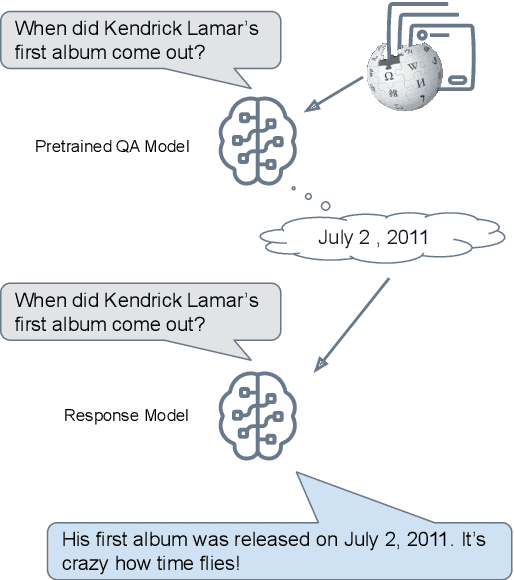
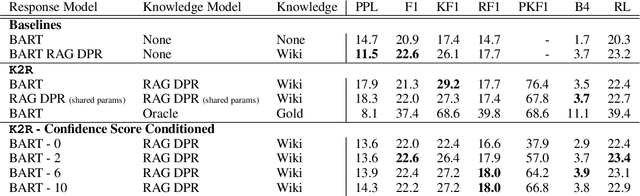

Large language models can produce fluent dialogue but often hallucinate factual inaccuracies. While retrieval-augmented models help alleviate this issue, they still face a difficult challenge of both reasoning to provide correct knowledge and generating conversation simultaneously. In this work, we propose a modular model, Knowledge to Response (K2R), for incorporating knowledge into conversational agents, which breaks down this problem into two easier steps. K2R first generates a knowledge sequence, given a dialogue context, as an intermediate step. After this "reasoning step", the model then attends to its own generated knowledge sequence, as well as the dialogue context, to produce a final response. In detailed experiments, we find that such a model hallucinates less in knowledge-grounded dialogue tasks, and has advantages in terms of interpretability and modularity. In particular, it can be used to fuse QA and dialogue systems together to enable dialogue agents to give knowledgeable answers, or QA models to give conversational responses in a zero-shot setting.
Boosting Search Engines with Interactive Agents
Sep 01, 2021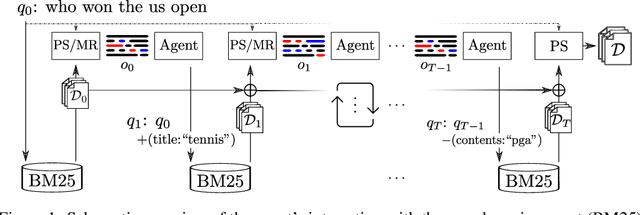
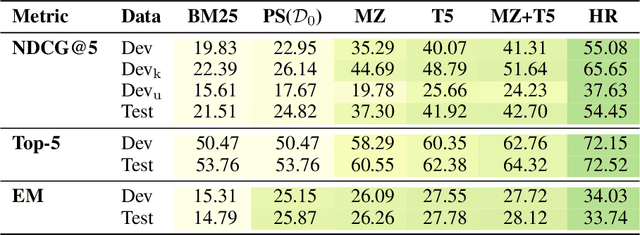
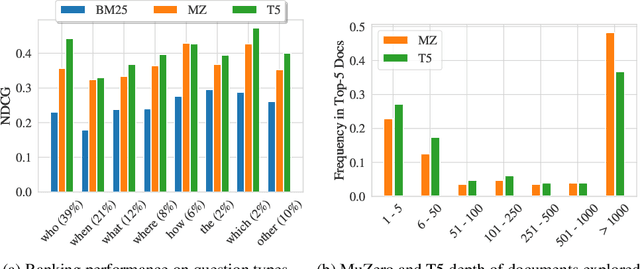

Can machines learn to use a search engine as an interactive tool for finding information? That would have far reaching consequences for making the world's knowledge more accessible. This paper presents first steps in designing agents that learn meta-strategies for contextual query refinements. Our approach uses machine reading to guide the selection of refinement terms from aggregated search results. Agents are then empowered with simple but effective search operators to exert fine-grained and transparent control over queries and search results. We develop a novel way of generating synthetic search sessions, which leverages the power of transformer-based generative language models through (self-)supervised learning. We also present a reinforcement learning agent with dynamically constrained actions that can learn interactive search strategies completely from scratch. In both cases, we obtain significant improvements over one-shot search with a strong information retrieval baseline. Finally, we provide an in-depth analysis of the learned search policies.
How to Query Language Models?
Aug 04, 2021
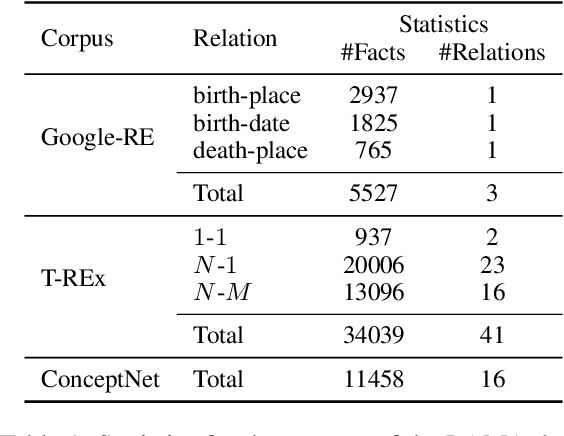

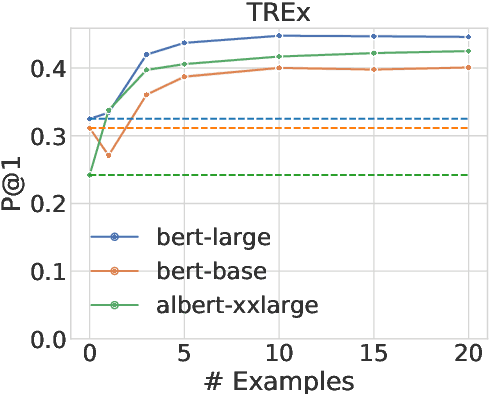
Large pre-trained language models (LMs) are capable of not only recovering linguistic but also factual and commonsense knowledge. To access the knowledge stored in mask-based LMs, we can use cloze-style questions and let the model fill in the blank. The flexibility advantage over structured knowledge bases comes with the drawback of finding the right query for a certain information need. Inspired by human behavior to disambiguate a question, we propose to query LMs by example. To clarify the ambivalent question "Who does Neuer play for?", a successful strategy is to demonstrate the relation using another subject, e.g., "Ronaldo plays for Portugal. Who does Neuer play for?". We apply this approach of querying by example to the LAMA probe and obtain substantial improvements of up to 37.8% for BERT-large on the T-REx data when providing only 10 demonstrations--even outperforming a baseline that queries the model with up to 40 paraphrases of the question. The examples are provided through the model's context and thus require neither fine-tuning nor an additional forward pass. This suggests that LMs contain more factual and commonsense knowledge than previously assumed--if we query the model in the right way.
LeDeepChef: Deep Reinforcement Learning Agent for Families of Text-Based Games
Sep 04, 2019

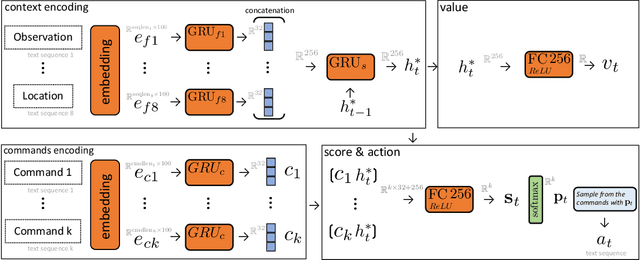
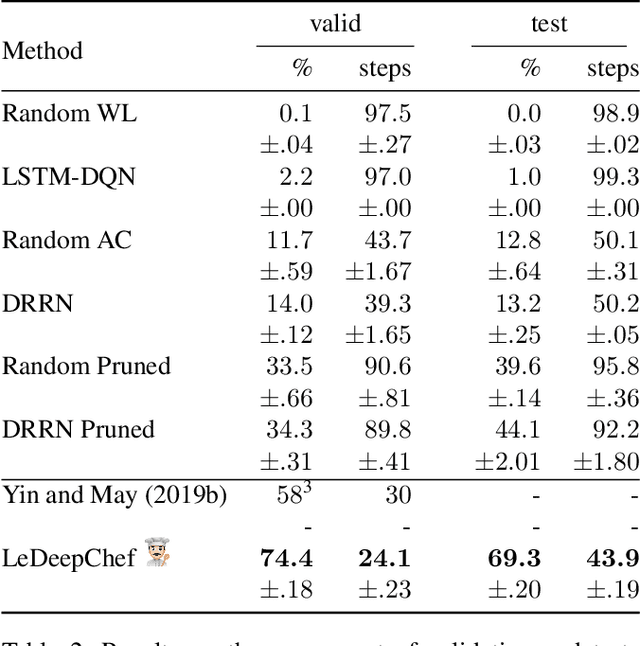
While Reinforcement Learning (RL) approaches lead to significant achievements in a variety of areas in recent history, natural language tasks remained mostly unaffected, due to the compositional and combinatorial nature that makes them notoriously hard to optimize. With the emerging field of Text-Based Games (TBGs), researchers try to bridge this gap. Inspired by the success of RL algorithms on Atari games, the idea is to develop new methods in a restricted game world and then gradually move to more complex environments. Previous work in the area of TBGs has mainly focused on solving individual games. We, however, consider the task of designing an agent that not just succeeds in a single game, but performs well across a whole family of games, sharing the same theme. In this work, we present our deep RL agent--LeDeepChef--that shows generalization capabilities to never-before-seen games of the same family with different environments and task descriptions. The agent participated in Microsoft Research's "First TextWorld Problems: A Language and Reinforcement Learning Challenge" and outperformed all but one competitor on the final test set. The games from the challenge all share the same theme, namely cooking in a modern house environment, but differ significantly in the arrangement of the rooms, the presented objects, and the specific goal (recipe to cook). To build an agent that achieves high scores across a whole family of games, we use an actor-critic framework and prune the action-space by using ideas from hierarchical reinforcement learning and a specialized module trained on a recipe database.
Ellipsoidal Trust Region Methods and the Marginal Value of Hessian Information for Neural Network Training
May 22, 2019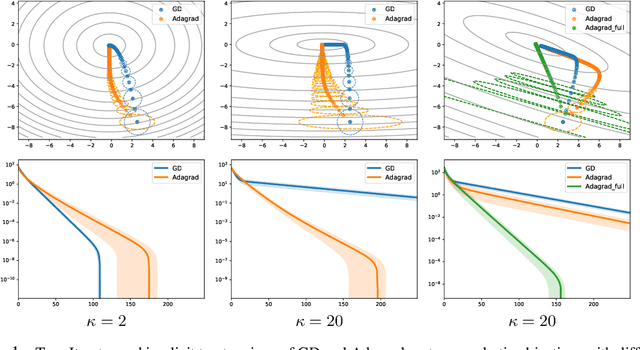

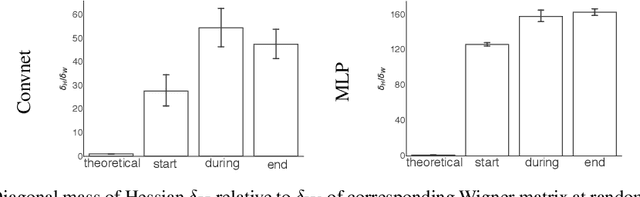
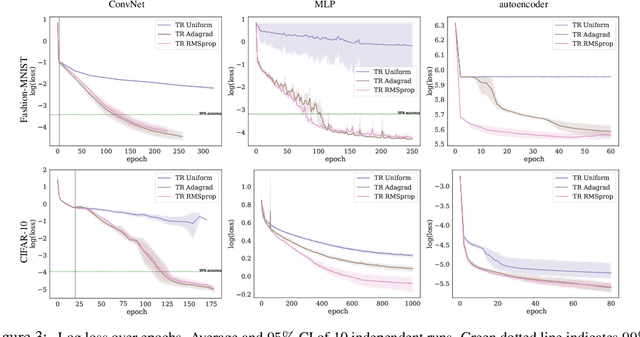
We investigate the use of ellipsoidal trust region constraints for second-order optimization of neural networks. This approach can be seen as a higher-order counterpart of adaptive gradient methods, which we here show to be interpretable as first-order trust region methods with ellipsoidal constraints. In particular, we show that the preconditioning matrix used in RMSProp and Adam satisfies the necessary conditions for convergence of (first- and) second-order trust region methods and report that this ellipsoidal constraint constantly outperforms its spherical counterpart in practice. We furthermore set out to clarify the long-standing question of the potential superiority of Newton methods in deep learning. In this regard, we run extensive benchmarks across different datasets and architectures to find that comparable performance to gradient descent algorithms can be achieved but using Hessian information does not give rise to better limit points and comes at the cost of increased hyperparameter tuning.
Local Saddle Point Optimization: A Curvature Exploitation Approach
Jun 26, 2018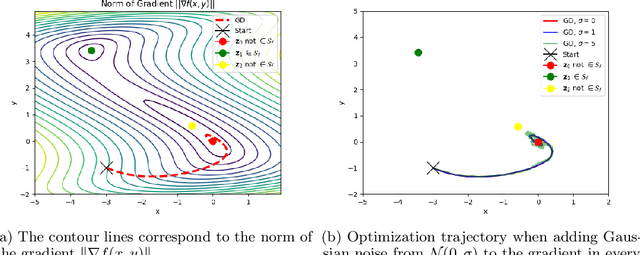

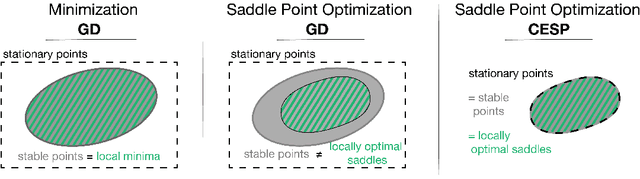
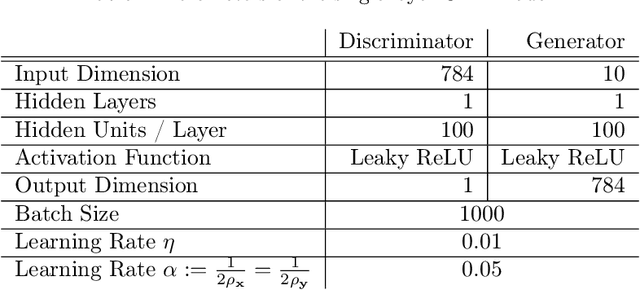
Gradient-based optimization methods are the most popular choice for finding local optima for classical minimization and saddle point problems. Here, we highlight a systemic issue of gradient dynamics that arise for saddle point problems, namely the presence of undesired stable stationary points that are no local optima. We propose a novel optimization approach that exploits curvature information in order to escape from these undesired stationary points. We prove that different optimization methods, including gradient method and adagrad, equipped with curvature exploitation can escape non-optimal stationary points. We also provide empirical results on common saddle point problems which confirm the advantage of using curvature exploitation.