 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReason first, then respond: Modular Generation for Knowledge-infused Dialogue
Paper and Code
Nov 09, 2021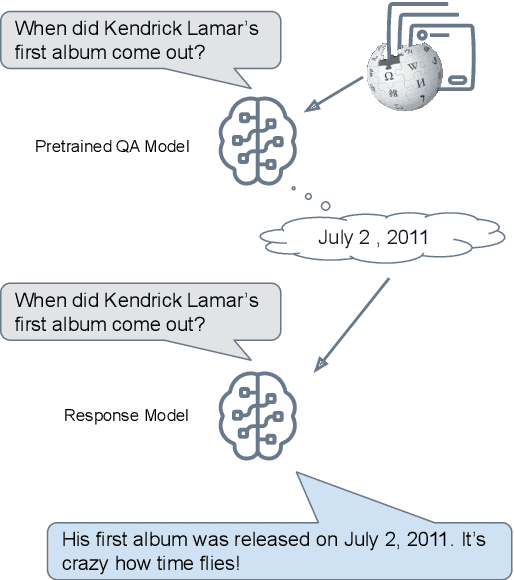
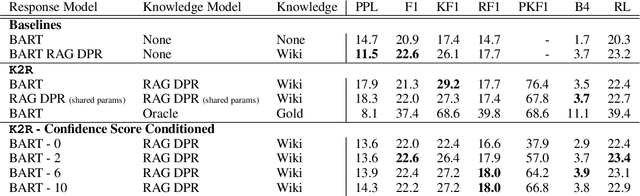

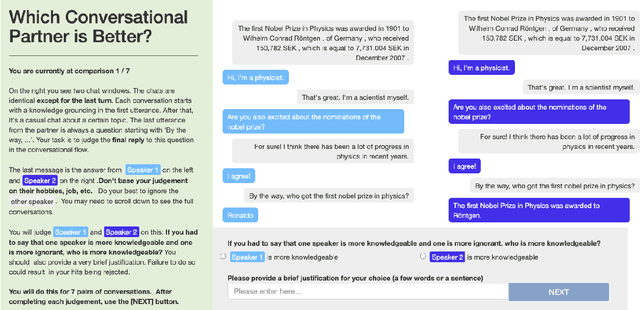
Large language models can produce fluent dialogue but often hallucinate factual inaccuracies. While retrieval-augmented models help alleviate this issue, they still face a difficult challenge of both reasoning to provide correct knowledge and generating conversation simultaneously. In this work, we propose a modular model, Knowledge to Response (K2R), for incorporating knowledge into conversational agents, which breaks down this problem into two easier steps. K2R first generates a knowledge sequence, given a dialogue context, as an intermediate step. After this "reasoning step", the model then attends to its own generated knowledge sequence, as well as the dialogue context, to produce a final response. In detailed experiments, we find that such a model hallucinates less in knowledge-grounded dialogue tasks, and has advantages in terms of interpretability and modularity. In particular, it can be used to fuse QA and dialogue systems together to enable dialogue agents to give knowledgeable answers, or QA models to give conversational responses in a zero-shot setting.