 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Assisted Scientific Assessment: A Case Study on Climate Change
Feb 10, 2026The emerging paradigm of AI co-scientists focuses on tasks characterized by repeatable verification, where agents explore search spaces in 'guess and check' loops. This paradigm does not extend to problems where repeated evaluation is impossible and ground truth is established by the consensus synthesis of theory and existing evidence. We evaluate a Gemini-based AI environment designed to support collaborative scientific assessment, integrated into a standard scientific workflow. In collaboration with a diverse group of 13 scientists working in the field of climate science, we tested the system on a complex topic: the stability of the Atlantic Meridional Overturning Circulation (AMOC). Our results show that AI can accelerate the scientific workflow. The group produced a comprehensive synthesis of 79 papers through 104 revision cycles in just over 46 person-hours. AI contribution was significant: most AI-generated content was retained in the report. AI also helped maintain logical consistency and presentation quality. However, expert additions were crucial to ensure its acceptability: less than half of the report was produced by AI. Furthermore, substantial oversight was required to expand and elevate the content to rigorous scientific standards.
Assessing Large Language Models on Climate Information
Oct 04, 2023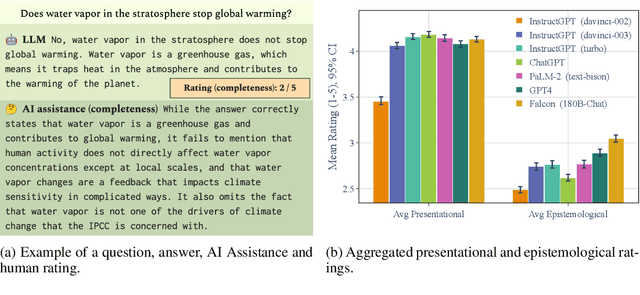
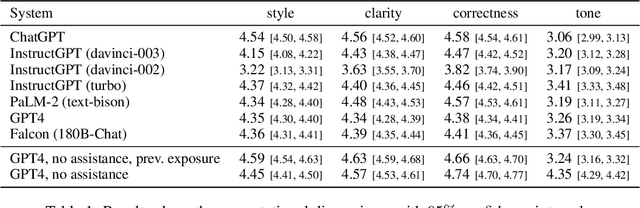
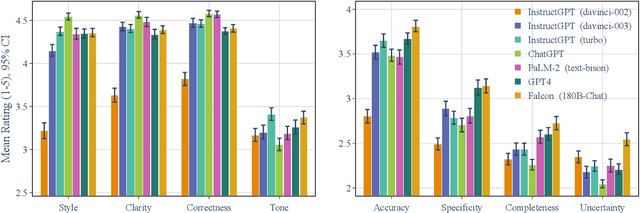
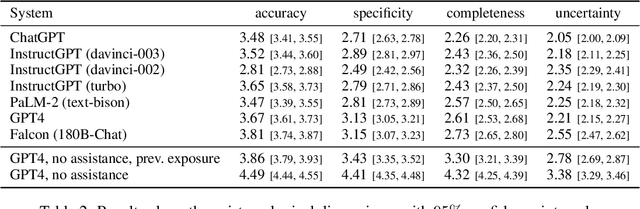
Understanding how climate change affects us and learning about available solutions are key steps toward empowering individuals and communities to mitigate and adapt to it. As Large Language Models (LLMs) rise in popularity, it is necessary to assess their capability in this domain. In this study, we present a comprehensive evaluation framework, grounded in science communication principles, to analyze LLM responses to climate change topics. Our framework emphasizes both the presentational and epistemological adequacy of answers, offering a fine-grained analysis of LLM generations. Spanning 8 dimensions, our framework discerns up to 30 distinct issues in model outputs. The task is a real-world example of a growing number of challenging problems where AI can complement and lift human performance. We introduce a novel and practical protocol for scalable oversight that uses AI Assistance and relies on raters with relevant educational backgrounds. We evaluate several recent LLMs and conduct a comprehensive analysis of the results, shedding light on both the potential and the limitations of LLMs in the realm of climate communication.
Probing in Context: Toward Building Robust Classifiers via Probing Large Language Models
May 23, 2023Large language models are able to learn new tasks in context, where they are provided with instructions and a few annotated examples. However, the effectiveness of in-context learning is dependent to the provided context, and the performance on a downstream task can vary a lot depending on the instruction. Importantly, such dependency on the context can happen in unpredictable ways, e.g., a seemingly more informative instruction might lead to a worse performance. In this paper, we propose an alternative approach, which we term in-context probing. Similar to in-context learning, we contextualize the representation of the input with an instruction, but instead of decoding the output prediction, we probe the contextualized representation to predict the label. Through a series of experiments on a diverse set of classification tasks, we show that in-context probing is significantly more robust to changes in instructions. We further show that probing can be particularly helpful to build classifiers on top of smaller models, and with only a hundred training examples.
Zero-Shot Retrieval with Search Agents and Hybrid Environments
Sep 30, 2022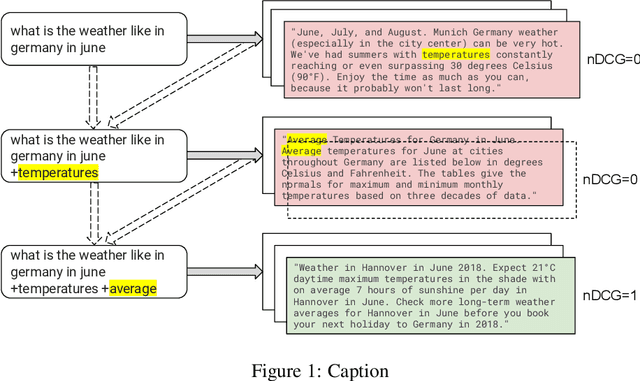
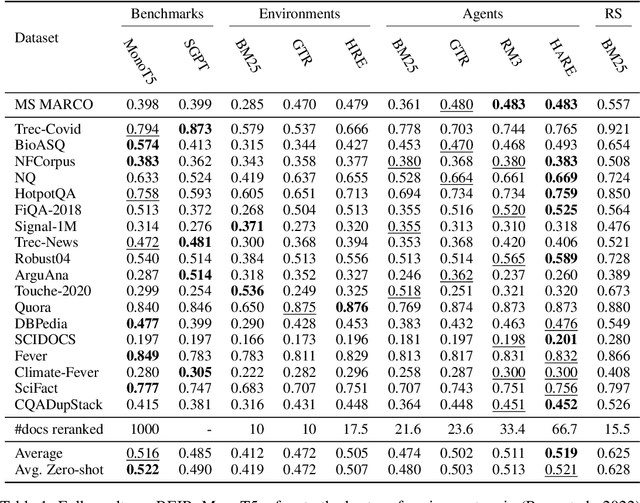
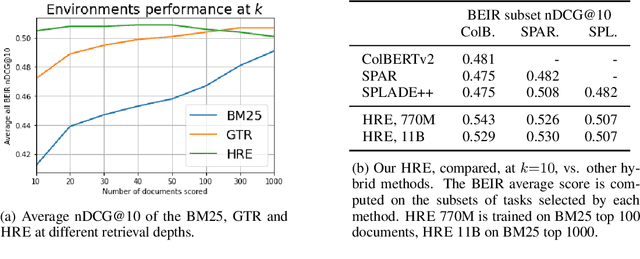
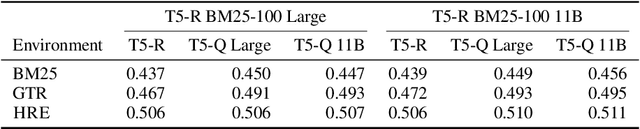
Learning to search is the task of building artificial agents that learn to autonomously use a search box to find information. So far, it has been shown that current language models can learn symbolic query reformulation policies, in combination with traditional term-based retrieval, but fall short of outperforming neural retrievers. We extend the previous learning to search setup to a hybrid environment, which accepts discrete query refinement operations, after a first-pass retrieval step performed by a dual encoder. Experiments on the BEIR task show that search agents, trained via behavioral cloning, outperform the underlying search system based on a combined dual encoder retriever and cross encoder reranker. Furthermore, we find that simple heuristic Hybrid Retrieval Environments (HRE) can improve baseline performance by several nDCG points. The search agent based on HRE (HARE) produces state-of-the-art performance on both zero-shot and in-domain evaluations. We carry out an extensive qualitative analysis to shed light on the agents policies.
Boosting Search Engines with Interactive Agents
Sep 01, 2021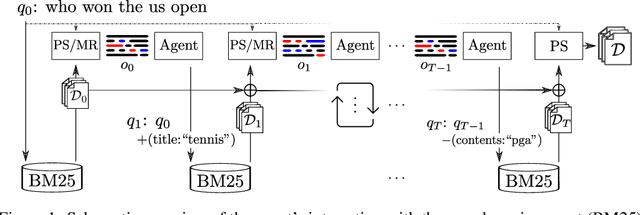
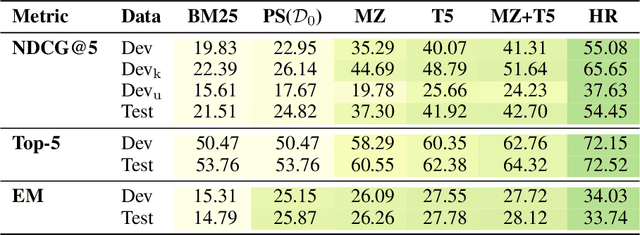
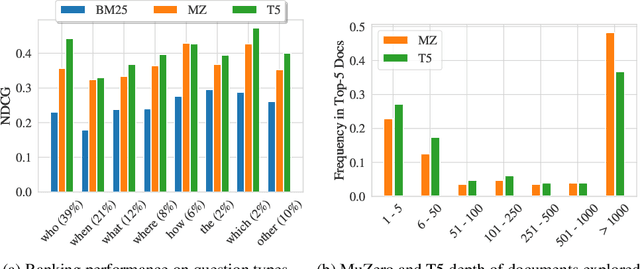

Can machines learn to use a search engine as an interactive tool for finding information? That would have far reaching consequences for making the world's knowledge more accessible. This paper presents first steps in designing agents that learn meta-strategies for contextual query refinements. Our approach uses machine reading to guide the selection of refinement terms from aggregated search results. Agents are then empowered with simple but effective search operators to exert fine-grained and transparent control over queries and search results. We develop a novel way of generating synthetic search sessions, which leverages the power of transformer-based generative language models through (self-)supervised learning. We also present a reinforcement learning agent with dynamically constrained actions that can learn interactive search strategies completely from scratch. In both cases, we obtain significant improvements over one-shot search with a strong information retrieval baseline. Finally, we provide an in-depth analysis of the learned search policies.
ClimaText: A Dataset for Climate Change Topic Detection
Jan 02, 2021


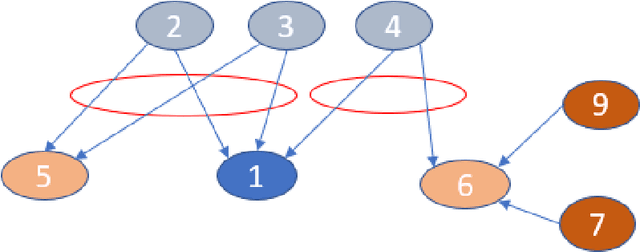
Climate change communication in the mass media and other textual sources may affect and shape public perception. Extracting climate change information from these sources is an important task, e.g., for filtering content and e-discovery, sentiment analysis, automatic summarization, question-answering, and fact-checking. However, automating this process is a challenge, as climate change is a complex, fast-moving, and often ambiguous topic with scarce resources for popular text-based AI tasks. In this paper, we introduce \textsc{ClimaText}, a dataset for sentence-based climate change topic detection, which we make publicly available. We explore different approaches to identify the climate change topic in various text sources. We find that popular keyword-based models are not adequate for such a complex and evolving task. Context-based algorithms like BERT \cite{devlin2018bert} can detect, in addition to many trivial cases, a variety of complex and implicit topic patterns. Nevertheless, our analysis reveals a great potential for improvement in several directions, such as, e.g., capturing the discussion on indirect effects of climate change. Hence, we hope this work can serve as a good starting point for further research on this topic.
CLIMATE-FEVER: A Dataset for Verification of Real-World Climate Claims
Jan 02, 2021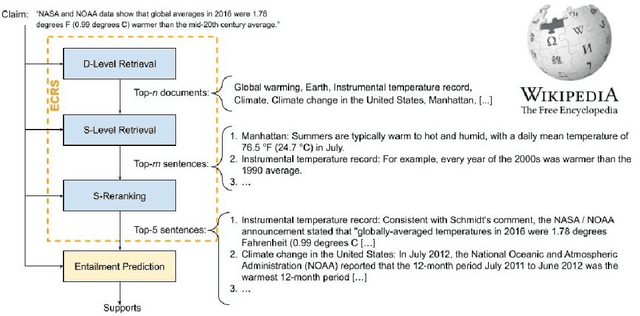
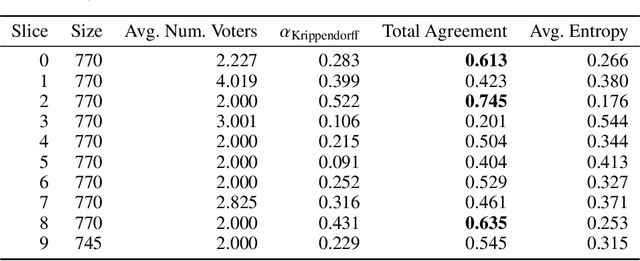
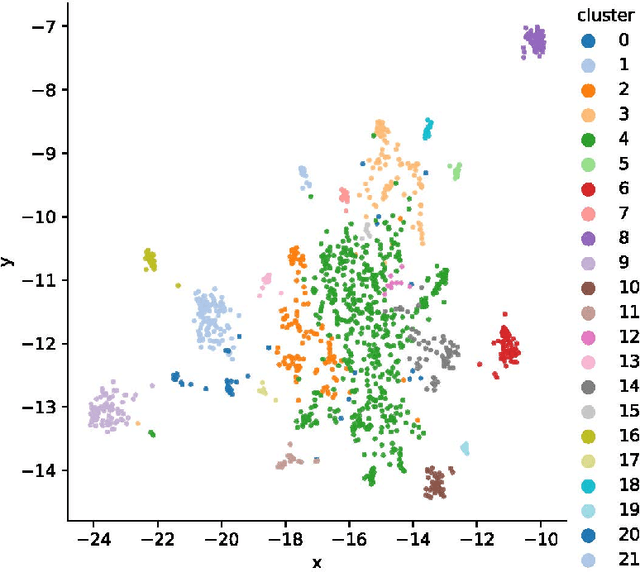
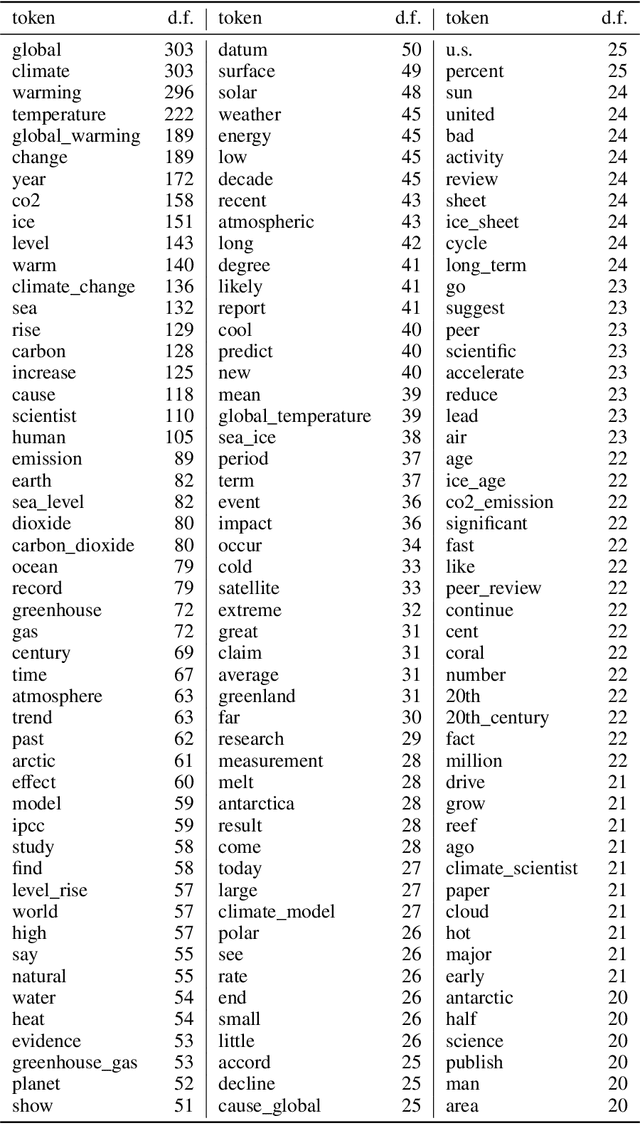
We introduce CLIMATE-FEVER, a new publicly available dataset for verification of climate change-related claims. By providing a dataset for the research community, we aim to facilitate and encourage work on improving algorithms for retrieving evidential support for climate-specific claims, addressing the underlying language understanding challenges, and ultimately help alleviate the impact of misinformation on climate change. We adapt the methodology of FEVER [1], the largest dataset of artificially designed claims, to real-life claims collected from the Internet. While during this process, we could rely on the expertise of renowned climate scientists, it turned out to be no easy task. We discuss the surprising, subtle complexity of modeling real-world climate-related claims within the \textsc{fever} framework, which we believe provides a valuable challenge for general natural language understanding. We hope that our work will mark the beginning of a new exciting long-term joint effort by the climate science and AI community.
Meta Answering for Machine Reading
Nov 11, 2019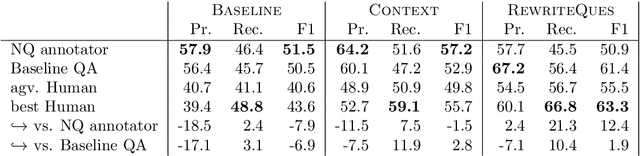
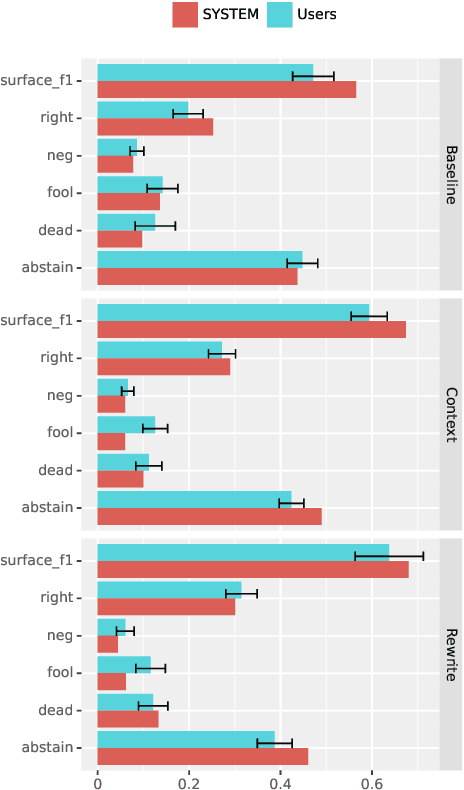

We investigate a framework for machine reading, inspired by real world information-seeking problems, where a meta question answering system interacts with a black box environment. The environment encapsulates a competitive machine reader based on BERT, providing candidate answers to questions, and possibly some context. To validate the realism of our formulation, we ask humans to play the role of a meta-answerer. With just a small snippet of text around an answer, humans can outperform the machine reader, improving recall. Similarly, a simple machine meta-answerer outperforms the environment, improving both precision and recall on the Natural Questions dataset. The system relies on joint training of answer scoring and the selection of conditioning information.
Learning to Coordinate Multiple Reinforcement Learning Agents for Diverse Query Reformulation
Sep 27, 2018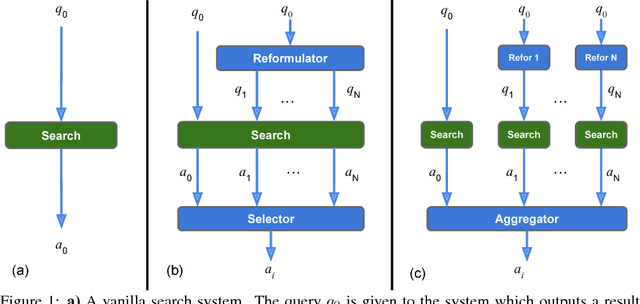
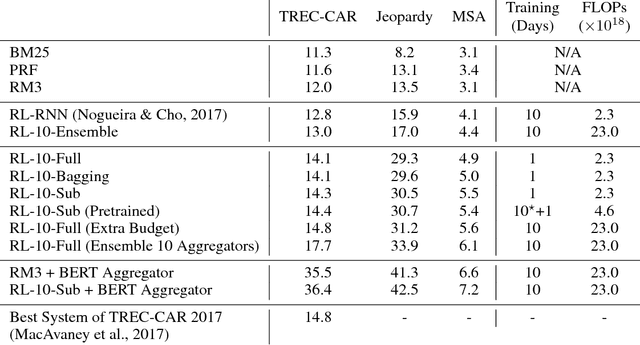
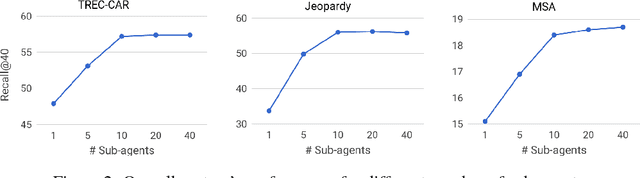
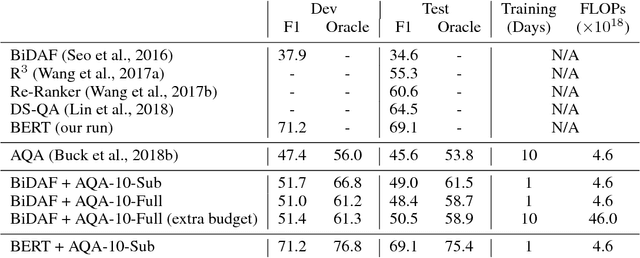
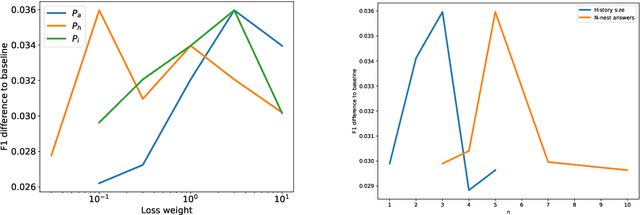
We propose a method to efficiently learn diverse strategies in reinforcement learning for query reformulation in the tasks of document retrieval and question answering. In the proposed framework an agent consists of multiple specialized sub-agents and a meta-agent that learns to aggregate the answers from sub-agents to produce a final answer. Sub-agents are trained on disjoint partitions of the training data, while the meta-agent is trained on the full training set. Our method makes learning faster, because it is highly parallelizable, and has better generalization performance than strong baselines, such as an ensemble of agents trained on the full data. We show that the improved performance is due to the increased diversity of reformulation strategies.
Zero-Shot Dual Machine Translation
May 25, 2018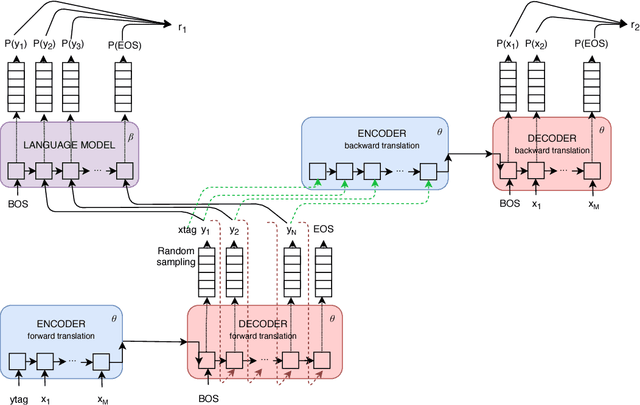
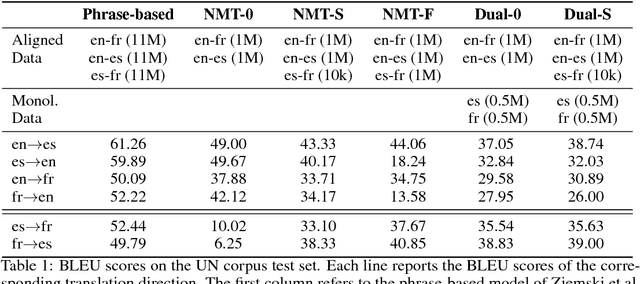
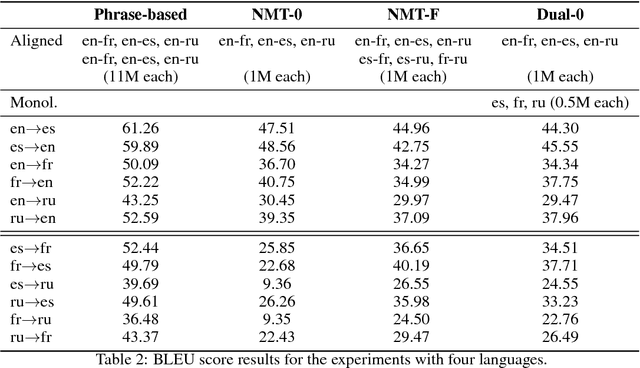
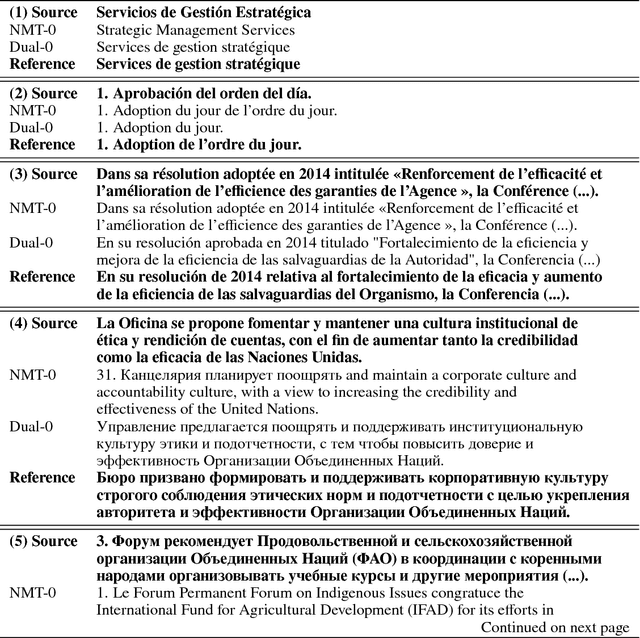
Neural Machine Translation (NMT) systems rely on large amounts of parallel data. This is a major challenge for low-resource languages. Building on recent work on unsupervised and semi-supervised methods, we present an approach that combines zero-shot and dual learning. The latter relies on reinforcement learning, to exploit the duality of the machine translation task, and requires only monolingual data for the target language pair. Experiments show that a zero-shot dual system, trained on English-French and English-Spanish, outperforms by large margins a standard NMT system in zero-shot translation performance on Spanish-French (both directions). The zero-shot dual method approaches the performance, within 2.2 BLEU points, of a comparable supervised setting. Our method can obtain improvements also on the setting where a small amount of parallel data for the zero-shot language pair is available. Adding Russian, to extend our experiments to jointly modeling 6 zero-shot translation directions, all directions improve between 4 and 15 BLEU points, again, reaching performance near that of the supervised setting.