 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyntactic Control of Language Models by Posterior Inference
Jun 08, 2025Controlling the syntactic structure of text generated by language models is valuable for applications requiring clarity, stylistic consistency, or interpretability, yet it remains a challenging task. In this paper, we argue that sampling algorithms based on the posterior inference can effectively enforce a target constituency structure during generation. Our approach combines sequential Monte Carlo, which estimates the posterior distribution by sampling from a proposal distribution, with a syntactic tagger that ensures that each generated token aligns with the desired syntactic structure. Our experiments with GPT2 and Llama3-8B models show that with an appropriate proposal distribution, we can improve syntactic accuracy, increasing the F1 score from $12.31$ (GPT2-large) and $35.33$ (Llama3-8B) to about $93$ in both cases without compromising the language model's fluency. These results underscore both the complexity of syntactic control and the effectiveness of sampling algorithms, offering a promising approach for applications where precise control over syntax is essential.
Better Estimation of the KL Divergence Between Language Models
Apr 14, 2025Estimating the Kullback--Leibler (KL) divergence between language models has many applications, e.g., reinforcement learning from human feedback (RLHF), interpretability, and knowledge distillation. However, computing the exact KL divergence between two arbitrary language models is intractable. Thus, practitioners often resort to the use of sampling-based estimators. While it is easy to fashion a simple Monte Carlo (MC) estimator that provides an unbiased estimate of the KL divergence between language models, this estimator notoriously suffers from high variance, and can even result in a negative estimate of the KL divergence, a non-negative quantity. In this paper, we introduce a Rao--Blackwellized estimator that is also unbiased and provably has variance less than or equal to that of the standard Monte Carlo estimator. In an empirical study on sentiment-controlled fine-tuning, we show that our estimator provides more stable KL estimates and reduces variance substantially in practice. Additionally, we derive an analogous Rao--Blackwellized estimator of the gradient of the KL divergence, which leads to more stable training and produces models that more frequently appear on the Pareto frontier of reward vs. KL compared to the ones trained with the MC estimator of the gradient.
Reverse-Engineering the Reader
Oct 16, 2024Numerous previous studies have sought to determine to what extent language models, pretrained on natural language text, can serve as useful models of human cognition. In this paper, we are interested in the opposite question: whether we can directly optimize a language model to be a useful cognitive model by aligning it to human psychometric data. To achieve this, we introduce a novel alignment technique in which we fine-tune a language model to implicitly optimize the parameters of a linear regressor that directly predicts humans' reading times of in-context linguistic units, e.g., phonemes, morphemes, or words, using surprisal estimates derived from the language model. Using words as a test case, we evaluate our technique across multiple model sizes and datasets and find that it improves language models' psychometric predictive power. However, we find an inverse relationship between psychometric power and a model's performance on downstream NLP tasks as well as its perplexity on held-out test data. While this latter trend has been observed before (Oh et al., 2022; Shain et al., 2024), we are the first to induce it by manipulating a model's alignment to psychometric data.
Variational Best-of-N Alignment
Jul 08, 2024



Best-of-N (BoN) is a popular and effective algorithm for aligning language models to human preferences. The algorithm works as follows: at inference time, N samples are drawn from the language model, and the sample with the highest reward, as judged by a reward model, is returned as the output. Despite its effectiveness, BoN is computationally expensive; it reduces sampling throughput by a factor of N. To make BoN more efficient at inference time, one strategy is to fine-tune the language model to mimic what BoN does during inference. To achieve this, we derive the distribution induced by the BoN algorithm. We then propose to fine-tune the language model to minimize backward KL divergence to the BoN distribution. Our approach is analogous to mean-field variational inference and, thus, we term it variational BoN (vBoN). To the extent this fine-tuning is successful and we end up with a good approximation, we have reduced the inference cost by a factor of N. Our experiments on a controlled generation task suggest that while variational BoN is not as effective as BoN in aligning language models, it is close to BoN performance as vBoN appears more often on the Pareto frontier of reward and KL divergence compared to models trained with KL-constrained RL objective.
The Role of $n$-gram Smoothing in the Age of Neural Networks
Mar 25, 2024For nearly three decades, language models derived from the $n$-gram assumption held the state of the art on the task. The key to their success lay in the application of various smoothing techniques that served to combat overfitting. However, when neural language models toppled $n$-gram models as the best performers, $n$-gram smoothing techniques became less relevant. Indeed, it would hardly be an understatement to suggest that the line of inquiry into $n$-gram smoothing techniques became dormant. This paper re-opens the role classical $n$-gram smoothing techniques may play in the age of neural language models. First, we draw a formal equivalence between label smoothing, a popular regularization technique for neural language models, and add-$\lambda$ smoothing. Second, we derive a generalized framework for converting \emph{any} $n$-gram smoothing technique into a regularizer compatible with neural language models. Our empirical results find that our novel regularizers are comparable to and, indeed, sometimes outperform label smoothing on language modeling and machine translation.
Direct Preference Optimization with an Offset
Feb 16, 2024

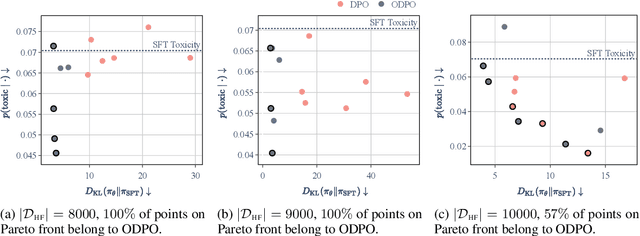

Direct preference optimization (DPO) is a successful fine-tuning strategy for aligning large language models with human preferences without the need to train a reward model or employ reinforcement learning. DPO, as originally formulated, relies on binary preference data and fine-tunes a language model to increase the likelihood of a preferred response over a dispreferred response. However, not all preference pairs are equal: while in some cases the preferred response is only slightly better than the dispreferred response, there can be a stronger preference for one response when, for example, the other response includes harmful or toxic content. In this paper, we propose a generalization of DPO, termed DPO with an offset (ODPO), that does not treat every preference pair equally during fine-tuning. Intuitively, ODPO requires the difference between the likelihood of the preferred and dispreferred response to be greater than an offset value. The offset is determined based on the extent to which one response is preferred over another. Our experiments on various tasks suggest that ODPO significantly outperforms DPO in aligning language models, especially when the number of preference pairs is limited.
Principled Gradient-based Markov Chain Monte Carlo for Text Generation
Dec 29, 2023Recent papers have demonstrated the possibility of energy-based text generation by adapting gradient-based sampling algorithms, a paradigm of MCMC algorithms that promises fast convergence. However, as we show in this paper, previous attempts on this approach to text generation all fail to sample correctly from the target language model distributions. To address this limitation, we consider the problem of designing text samplers that are faithful, meaning that they have the target text distribution as its limiting distribution. We propose several faithful gradient-based sampling algorithms to sample from the target energy-based text distribution correctly, and study their theoretical properties. Through experiments on various forms of text generation, we demonstrate that faithful samplers are able to generate more fluent text while adhering to the control objectives better.
Assessing Large Language Models on Climate Information
Oct 04, 2023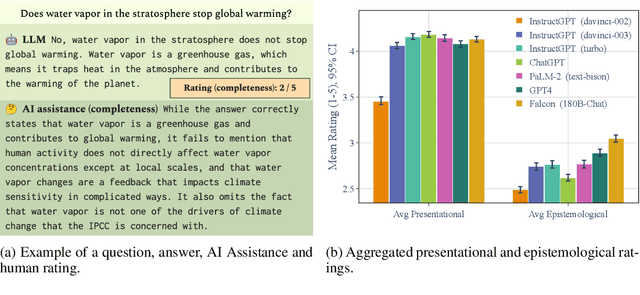
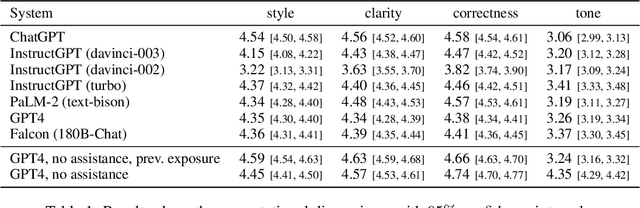
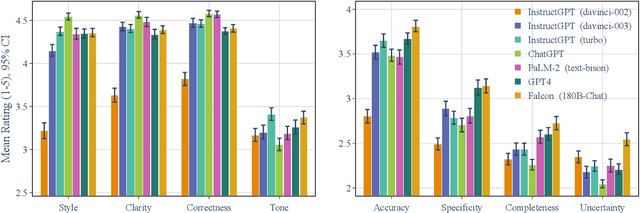
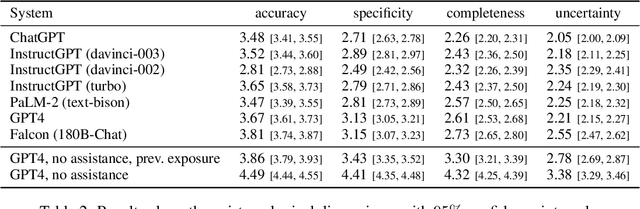
Understanding how climate change affects us and learning about available solutions are key steps toward empowering individuals and communities to mitigate and adapt to it. As Large Language Models (LLMs) rise in popularity, it is necessary to assess their capability in this domain. In this study, we present a comprehensive evaluation framework, grounded in science communication principles, to analyze LLM responses to climate change topics. Our framework emphasizes both the presentational and epistemological adequacy of answers, offering a fine-grained analysis of LLM generations. Spanning 8 dimensions, our framework discerns up to 30 distinct issues in model outputs. The task is a real-world example of a growing number of challenging problems where AI can complement and lift human performance. We introduce a novel and practical protocol for scalable oversight that uses AI Assistance and relies on raters with relevant educational backgrounds. We evaluate several recent LLMs and conduct a comprehensive analysis of the results, shedding light on both the potential and the limitations of LLMs in the realm of climate communication.
Which Spurious Correlations Impact Reasoning in NLI Models? A Visual Interactive Diagnosis through Data-Constrained Counterfactuals
Jun 21, 2023

We present a human-in-the-loop dashboard tailored to diagnosing potential spurious features that NLI models rely on for predictions. The dashboard enables users to generate diverse and challenging examples by drawing inspiration from GPT-3 suggestions. Additionally, users can receive feedback from a trained NLI model on how challenging the newly created example is and make refinements based on the feedback. Through our investigation, we discover several categories of spurious correlations that impact the reasoning of NLI models, which we group into three categories: Semantic Relevance, Logical Fallacies, and Bias. Based on our findings, we identify and describe various research opportunities, including diversifying training data and assessing NLI models' robustness by creating adversarial test suites.
Hexatagging: Projective Dependency Parsing as Tagging
Jun 08, 2023



We introduce a novel dependency parser, the hexatagger, that constructs dependency trees by tagging the words in a sentence with elements from a finite set of possible tags. In contrast to many approaches to dependency parsing, our approach is fully parallelizable at training time, i.e., the structure-building actions needed to build a dependency parse can be predicted in parallel to each other. Additionally, exact decoding is linear in time and space complexity. Furthermore, we derive a probabilistic dependency parser that predicts hexatags using no more than a linear model with features from a pretrained language model, i.e., we forsake a bespoke architecture explicitly designed for the task. Despite the generality and simplicity of our approach, we achieve state-of-the-art performance of 96.4 LAS and 97.4 UAS on the Penn Treebank test set. Additionally, our parser's linear time complexity and parallelism significantly improve computational efficiency, with a roughly 10-times speed-up over previous state-of-the-art models during decoding.