 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrefix Parsing is Just Parsing
Apr 23, 2026Prefix parsing asks whether an input prefix can be extended to a complete string generated by a given grammar. In the weighted setting, it also provides prefix probabilities, which are central to context-free language modeling, psycholinguistic analysis, and syntactically constrained generation from large language models. We introduce the prefix grammar transformation, an efficient reduction of prefix parsing to ordinary parsing. Given a grammar, our method constructs another grammar that generates exactly the prefixes of its original strings. Prefix parsing is then solved by applying any ordinary parsing algorithm on the transformed grammar without modification. The reduction is both elegant and practical: the transformed grammar is only a small factor larger than the input, and any optimized implementation can be used directly, eliminating the need for bespoke prefix-parsing algorithms. We also present a strategy-based on algorithmic differentiation-for computing the next-token weight vector, i.e., the prefix weights of all one-token extensions, enabling efficient prediction of the next token. Together, these contributions yield a simple, general, and efficient framework for prefix parsing.
Ensembling Language Models with Sequential Monte Carlo
Mar 05, 2026Practitioners have access to an abundance of language models and prompting strategies for solving many language modeling tasks; yet prior work shows that modeling performance is highly sensitive to both choices. Classical machine learning ensembling techniques offer a principled approach: aggregate predictions from multiple sources to achieve better performance than any single one. However, applying ensembling to language models during decoding is challenging: naively aggregating next-token probabilities yields samples from a locally normalized, biased approximation of the generally intractable ensemble distribution over strings. In this work, we introduce a unified framework for composing $K$ language models into $f$-ensemble distributions for a wide range of functions $f\colon\mathbb{R}_{\geq 0}^{K}\to\mathbb{R}_{\geq 0}$. To sample from these distributions, we propose a byte-level sequential Monte Carlo (SMC) algorithm that operates in a shared character space, enabling ensembles of models with mismatching vocabularies and consistent sampling in the limit. We evaluate a family of $f$-ensembles across prompt and model combinations for various structured text generation tasks, highlighting the benefits of alternative aggregation strategies over traditional probability averaging, and showing that better posterior approximations can yield better ensemble performance.
Transducing Language Models
Mar 05, 2026Modern language models define distributions over strings, but downstream tasks often require different output formats. For instance, a model that generates byte-pair strings does not directly produce word-level predictions, and a DNA model does not directly produce amino-acid sequences. In such cases, a deterministic string-to-string transformation can convert the model's output to the desired form. This is a familiar pattern in probability theory: applying a function $f$ to a random variable $X\sim p$ yields a transformed random variable $f(X)$ with an induced distribution. While such transformations are occasionally used in language modeling, prior work does not treat them as yielding new, fully functional language models. We formalize this perspective and introduce a general framework for language models derived from deterministic string-to-string transformations. We focus on transformations representable as finite-state transducers -- a commonly used state-machine abstraction for efficient string-to-string mappings. We develop algorithms that compose a language model with an FST to *marginalize* over source strings mapping to a given target, propagating probabilities through the transducer without altering model parameters and enabling *conditioning* on transformed outputs. We present an exact algorithm, an efficient approximation, and a theoretical analysis. We conduct experiments in three domains: converting language models from tokens to bytes, from tokens to words, and from DNA to amino acids. These experiments demonstrate inference-time adaptation of pretrained language models to match application-specific output requirements.
Language Models over Canonical Byte-Pair Encodings
Jun 09, 2025Modern language models represent probability distributions over character strings as distributions over (shorter) token strings derived via a deterministic tokenizer, such as byte-pair encoding. While this approach is highly effective at scaling up language models to large corpora, its current incarnations have a concerning property: the model assigns nonzero probability mass to an exponential number of $\it{noncanonical}$ token encodings of each character string -- these are token strings that decode to valid character strings but are impossible under the deterministic tokenizer (i.e., they will never be seen in any training corpus, no matter how large). This misallocation is both erroneous, as noncanonical strings never appear in training data, and wasteful, diverting probability mass away from plausible outputs. These are avoidable mistakes! In this work, we propose methods to enforce canonicality in token-level language models, ensuring that only canonical token strings are assigned positive probability. We present two approaches: (1) canonicality by conditioning, leveraging test-time inference strategies without additional training, and (2) canonicality by construction, a model parameterization that guarantees canonical outputs but requires training. We demonstrate that fixing canonicality mistakes improves the likelihood of held-out data for several models and corpora.
Syntactic Control of Language Models by Posterior Inference
Jun 08, 2025Controlling the syntactic structure of text generated by language models is valuable for applications requiring clarity, stylistic consistency, or interpretability, yet it remains a challenging task. In this paper, we argue that sampling algorithms based on the posterior inference can effectively enforce a target constituency structure during generation. Our approach combines sequential Monte Carlo, which estimates the posterior distribution by sampling from a proposal distribution, with a syntactic tagger that ensures that each generated token aligns with the desired syntactic structure. Our experiments with GPT2 and Llama3-8B models show that with an appropriate proposal distribution, we can improve syntactic accuracy, increasing the F1 score from $12.31$ (GPT2-large) and $35.33$ (Llama3-8B) to about $93$ in both cases without compromising the language model's fluency. These results underscore both the complexity of syntactic control and the effectiveness of sampling algorithms, offering a promising approach for applications where precise control over syntax is essential.
Syntactic and Semantic Control of Large Language Models via Sequential Monte Carlo
Apr 18, 2025



A wide range of LM applications require generating text that conforms to syntactic or semantic constraints. Imposing such constraints can be naturally framed as probabilistic conditioning, but exact generation from the resulting distribution -- which can differ substantially from the LM's base distribution -- is generally intractable. In this work, we develop an architecture for controlled LM generation based on sequential Monte Carlo (SMC). Our SMC framework allows us to flexibly incorporate domain- and problem-specific constraints at inference time, and efficiently reallocate computational resources in light of new information during the course of generation. By comparing to a number of alternatives and ablations on four challenging domains -- Python code generation for data science, text-to-SQL, goal inference, and molecule synthesis -- we demonstrate that, with little overhead, our approach allows small open-source language models to outperform models over 8x larger, as well as closed-source, fine-tuned ones. In support of the probabilistic perspective, we show that these performance improvements are driven by better approximation to the posterior distribution. Our system builds on the framework of Lew et al. (2023) and integrates with its language model probabilistic programming language, giving users a simple, programmable way to apply SMC to a broad variety of controlled generation problems.
Better Estimation of the KL Divergence Between Language Models
Apr 14, 2025Estimating the Kullback--Leibler (KL) divergence between language models has many applications, e.g., reinforcement learning from human feedback (RLHF), interpretability, and knowledge distillation. However, computing the exact KL divergence between two arbitrary language models is intractable. Thus, practitioners often resort to the use of sampling-based estimators. While it is easy to fashion a simple Monte Carlo (MC) estimator that provides an unbiased estimate of the KL divergence between language models, this estimator notoriously suffers from high variance, and can even result in a negative estimate of the KL divergence, a non-negative quantity. In this paper, we introduce a Rao--Blackwellized estimator that is also unbiased and provably has variance less than or equal to that of the standard Monte Carlo estimator. In an empirical study on sentiment-controlled fine-tuning, we show that our estimator provides more stable KL estimates and reduces variance substantially in practice. Additionally, we derive an analogous Rao--Blackwellized estimator of the gradient of the KL divergence, which leads to more stable training and produces models that more frequently appear on the Pareto frontier of reward vs. KL compared to the ones trained with the MC estimator of the gradient.
Fast Controlled Generation from Language Models with Adaptive Weighted Rejection Sampling
Apr 07, 2025The dominant approach to generating from language models subject to some constraint is locally constrained decoding (LCD), incrementally sampling tokens at each time step such that the constraint is never violated. Typically, this is achieved through token masking: looping over the vocabulary and excluding non-conforming tokens. There are two important problems with this approach. (i) Evaluating the constraint on every token can be prohibitively expensive -- LM vocabularies often exceed $100,000$ tokens. (ii) LCD can distort the global distribution over strings, sampling tokens based only on local information, even if they lead down dead-end paths. This work introduces a new algorithm that addresses both these problems. First, to avoid evaluating a constraint on the full vocabulary at each step of generation, we propose an adaptive rejection sampling algorithm that typically requires orders of magnitude fewer constraint evaluations. Second, we show how this algorithm can be extended to produce low-variance, unbiased estimates of importance weights at a very small additional cost -- estimates that can be soundly used within previously proposed sequential Monte Carlo algorithms to correct for the myopic behavior of local constraint enforcement. Through extensive empirical evaluation in text-to-SQL, molecular synthesis, goal inference, pattern matching, and JSON domains, we show that our approach is superior to state-of-the-art baselines, supporting a broader class of constraints and improving both runtime and performance. Additional theoretical and empirical analyses show that our method's runtime efficiency is driven by its dynamic use of computation, scaling with the divergence between the unconstrained and constrained LM, and as a consequence, runtime improvements are greater for better models.
From Language Models over Tokens to Language Models over Characters
Dec 04, 2024Modern language models are internally -- and mathematically -- distributions over token strings rather than \emph{character} strings, posing numerous challenges for programmers building user applications on top of them. For example, if a prompt is specified as a character string, it must be tokenized before passing it to the token-level language model. Thus, the tokenizer and consequent analyses are very sensitive to the specification of the prompt (e.g., if the prompt ends with a space or not). This paper presents algorithms for converting token-level language models to character-level ones. We present both exact and approximate algorithms. In the empirical portion of the paper, we benchmark the practical runtime and approximation quality. We find that -- even with a small computation budget -- our method is able to accurately approximate the character-level distribution (less than 0.00021 excess bits / character) at reasonably fast speeds (46.3 characters / second) on the Llama 3.1 8B language model.
On the Proper Treatment of Tokenization in Psycholinguistics
Oct 03, 2024
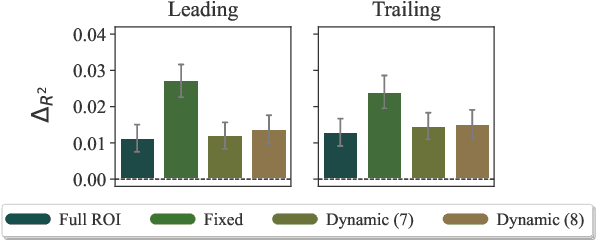

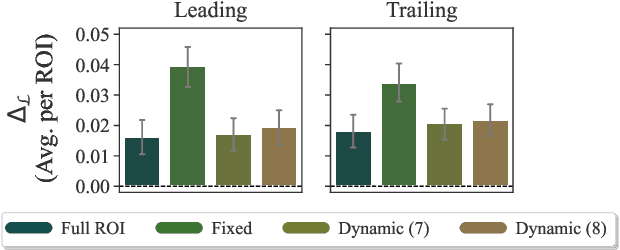
Language models are widely used in computational psycholinguistics to test theories that relate the negative log probability (the surprisal) of a region of interest (a substring of characters) under a language model to its cognitive cost experienced by readers, as operationalized, for example, by gaze duration on the region. However, the application of modern language models to psycholinguistic studies is complicated by the practice of using tokenization as an intermediate step in training a model. Doing so results in a language model over token strings rather than one over character strings. Vexingly, regions of interest are generally misaligned with these token strings. The paper argues that token-level language models should be (approximately) marginalized into character-level language models before they are used in psycholinguistic studies to compute the surprisal of a region of interest; then, the marginalized character-level language model can be used to compute the surprisal of an arbitrary character substring, which we term a focal area, that the experimenter may wish to use as a predictor. Our proposal of marginalizing a token-level model into a character-level one solves this misalignment issue independently of the tokenization scheme. Empirically, we discover various focal areas whose surprisal is a better psychometric predictor than the surprisal of the region of interest itself.