 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models over Canonical Byte-Pair Encodings
Jun 09, 2025Modern language models represent probability distributions over character strings as distributions over (shorter) token strings derived via a deterministic tokenizer, such as byte-pair encoding. While this approach is highly effective at scaling up language models to large corpora, its current incarnations have a concerning property: the model assigns nonzero probability mass to an exponential number of $\it{noncanonical}$ token encodings of each character string -- these are token strings that decode to valid character strings but are impossible under the deterministic tokenizer (i.e., they will never be seen in any training corpus, no matter how large). This misallocation is both erroneous, as noncanonical strings never appear in training data, and wasteful, diverting probability mass away from plausible outputs. These are avoidable mistakes! In this work, we propose methods to enforce canonicality in token-level language models, ensuring that only canonical token strings are assigned positive probability. We present two approaches: (1) canonicality by conditioning, leveraging test-time inference strategies without additional training, and (2) canonicality by construction, a model parameterization that guarantees canonical outputs but requires training. We demonstrate that fixing canonicality mistakes improves the likelihood of held-out data for several models and corpora.
Syntactic and Semantic Control of Large Language Models via Sequential Monte Carlo
Apr 18, 2025



A wide range of LM applications require generating text that conforms to syntactic or semantic constraints. Imposing such constraints can be naturally framed as probabilistic conditioning, but exact generation from the resulting distribution -- which can differ substantially from the LM's base distribution -- is generally intractable. In this work, we develop an architecture for controlled LM generation based on sequential Monte Carlo (SMC). Our SMC framework allows us to flexibly incorporate domain- and problem-specific constraints at inference time, and efficiently reallocate computational resources in light of new information during the course of generation. By comparing to a number of alternatives and ablations on four challenging domains -- Python code generation for data science, text-to-SQL, goal inference, and molecule synthesis -- we demonstrate that, with little overhead, our approach allows small open-source language models to outperform models over 8x larger, as well as closed-source, fine-tuned ones. In support of the probabilistic perspective, we show that these performance improvements are driven by better approximation to the posterior distribution. Our system builds on the framework of Lew et al. (2023) and integrates with its language model probabilistic programming language, giving users a simple, programmable way to apply SMC to a broad variety of controlled generation problems.
Fast Controlled Generation from Language Models with Adaptive Weighted Rejection Sampling
Apr 07, 2025The dominant approach to generating from language models subject to some constraint is locally constrained decoding (LCD), incrementally sampling tokens at each time step such that the constraint is never violated. Typically, this is achieved through token masking: looping over the vocabulary and excluding non-conforming tokens. There are two important problems with this approach. (i) Evaluating the constraint on every token can be prohibitively expensive -- LM vocabularies often exceed $100,000$ tokens. (ii) LCD can distort the global distribution over strings, sampling tokens based only on local information, even if they lead down dead-end paths. This work introduces a new algorithm that addresses both these problems. First, to avoid evaluating a constraint on the full vocabulary at each step of generation, we propose an adaptive rejection sampling algorithm that typically requires orders of magnitude fewer constraint evaluations. Second, we show how this algorithm can be extended to produce low-variance, unbiased estimates of importance weights at a very small additional cost -- estimates that can be soundly used within previously proposed sequential Monte Carlo algorithms to correct for the myopic behavior of local constraint enforcement. Through extensive empirical evaluation in text-to-SQL, molecular synthesis, goal inference, pattern matching, and JSON domains, we show that our approach is superior to state-of-the-art baselines, supporting a broader class of constraints and improving both runtime and performance. Additional theoretical and empirical analyses show that our method's runtime efficiency is driven by its dynamic use of computation, scaling with the divergence between the unconstrained and constrained LM, and as a consequence, runtime improvements are greater for better models.
Evaluating Distributional Distortion in Neural Language Modeling
Mar 24, 2022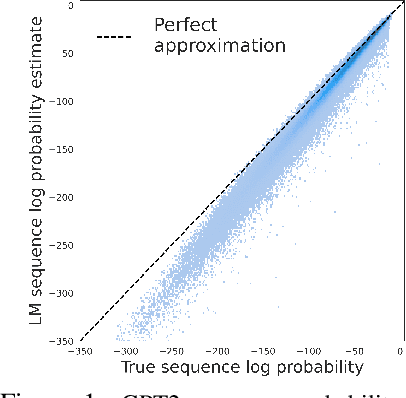


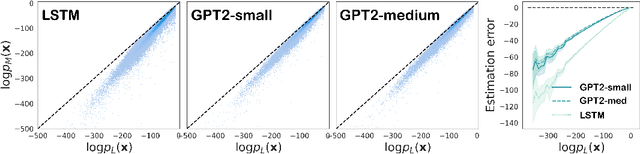
A fundamental characteristic of natural language is the high rate at which speakers produce novel expressions. Because of this novelty, a heavy-tail of rare events accounts for a significant amount of the total probability mass of distributions in language (Baayen, 2001). Standard language modeling metrics such as perplexity quantify the performance of language models (LM) in aggregate. As a result, we have relatively little understanding of whether neural LMs accurately estimate the probability of sequences in this heavy-tail of rare events. To address this gap, we develop a controlled evaluation scheme which uses generative models trained on natural data as artificial languages from which we can exactly compute sequence probabilities. Training LMs on generations from these artificial languages, we compare the sequence-level probability estimates given by LMs to the true probabilities in the target language. Our experiments reveal that LSTM and Transformer language models (i) systematically underestimate the probability of sequences drawn from the target language, and (ii) do so more severely for less-probable sequences. Investigating where this probability mass went, (iii) we find that LMs tend to overestimate the probability of ill formed (perturbed) sequences. In addition, we find that this underestimation behaviour (iv) is weakened, but not eliminated by greater amounts of training data, and (v) is exacerbated for target distributions with lower entropy.