 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Assisted Scientific Assessment: A Case Study on Climate Change
Feb 10, 2026The emerging paradigm of AI co-scientists focuses on tasks characterized by repeatable verification, where agents explore search spaces in 'guess and check' loops. This paradigm does not extend to problems where repeated evaluation is impossible and ground truth is established by the consensus synthesis of theory and existing evidence. We evaluate a Gemini-based AI environment designed to support collaborative scientific assessment, integrated into a standard scientific workflow. In collaboration with a diverse group of 13 scientists working in the field of climate science, we tested the system on a complex topic: the stability of the Atlantic Meridional Overturning Circulation (AMOC). Our results show that AI can accelerate the scientific workflow. The group produced a comprehensive synthesis of 79 papers through 104 revision cycles in just over 46 person-hours. AI contribution was significant: most AI-generated content was retained in the report. AI also helped maintain logical consistency and presentation quality. However, expert additions were crucial to ensure its acceptability: less than half of the report was produced by AI. Furthermore, substantial oversight was required to expand and elevate the content to rigorous scientific standards.
Assessing Large Language Models on Climate Information
Oct 04, 2023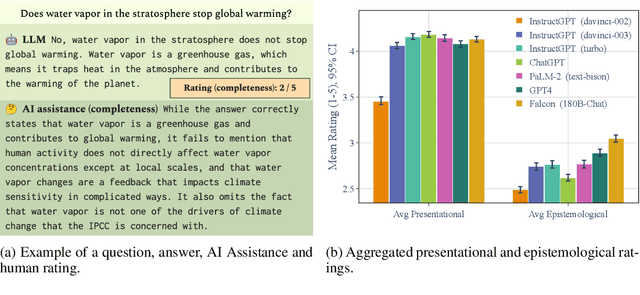
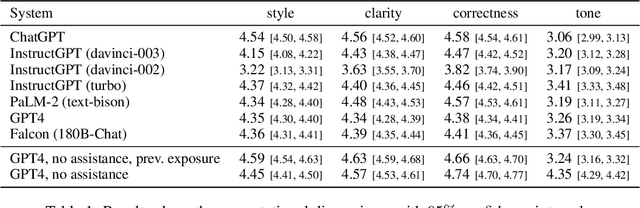
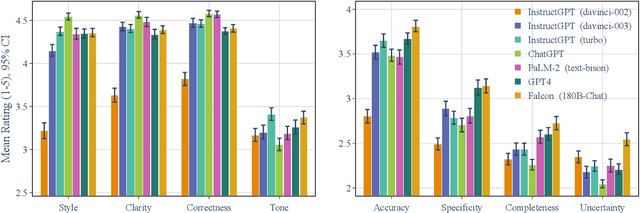
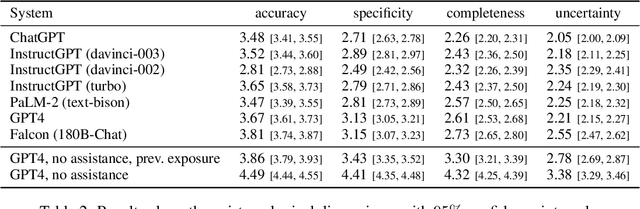
Understanding how climate change affects us and learning about available solutions are key steps toward empowering individuals and communities to mitigate and adapt to it. As Large Language Models (LLMs) rise in popularity, it is necessary to assess their capability in this domain. In this study, we present a comprehensive evaluation framework, grounded in science communication principles, to analyze LLM responses to climate change topics. Our framework emphasizes both the presentational and epistemological adequacy of answers, offering a fine-grained analysis of LLM generations. Spanning 8 dimensions, our framework discerns up to 30 distinct issues in model outputs. The task is a real-world example of a growing number of challenging problems where AI can complement and lift human performance. We introduce a novel and practical protocol for scalable oversight that uses AI Assistance and relies on raters with relevant educational backgrounds. We evaluate several recent LLMs and conduct a comprehensive analysis of the results, shedding light on both the potential and the limitations of LLMs in the realm of climate communication.
Zero-Shot Retrieval with Search Agents and Hybrid Environments
Sep 30, 2022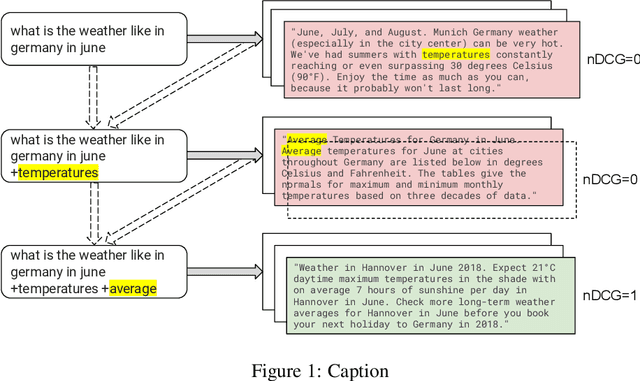
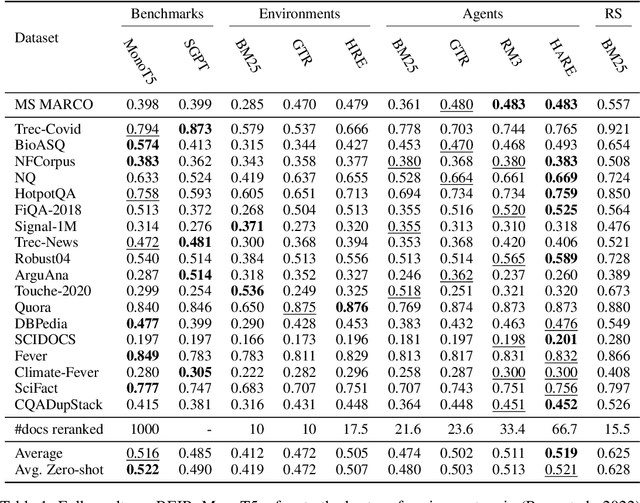
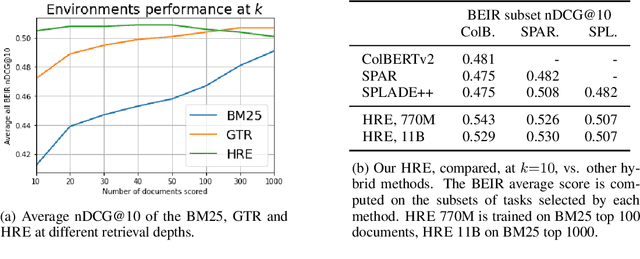
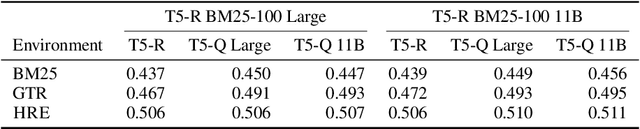
Learning to search is the task of building artificial agents that learn to autonomously use a search box to find information. So far, it has been shown that current language models can learn symbolic query reformulation policies, in combination with traditional term-based retrieval, but fall short of outperforming neural retrievers. We extend the previous learning to search setup to a hybrid environment, which accepts discrete query refinement operations, after a first-pass retrieval step performed by a dual encoder. Experiments on the BEIR task show that search agents, trained via behavioral cloning, outperform the underlying search system based on a combined dual encoder retriever and cross encoder reranker. Furthermore, we find that simple heuristic Hybrid Retrieval Environments (HRE) can improve baseline performance by several nDCG points. The search agent based on HRE (HARE) produces state-of-the-art performance on both zero-shot and in-domain evaluations. We carry out an extensive qualitative analysis to shed light on the agents policies.
Tomayto, Tomahto. Beyond Token-level Answer Equivalence for Question Answering Evaluation
Feb 15, 2022The predictions of question answering (QA) systems are typically evaluated against manually annotated finite sets of one or more answers. This leads to a coverage limitation that results in underestimating the true performance of systems, and is typically addressed by extending over exact match (EM) with predefined rules or with the token-level F1 measure. In this paper, we present the first systematic conceptual and data-driven analysis to examine the shortcomings of token-level equivalence measures. To this end, we define the asymmetric notion of answer equivalence (AE), accepting answers that are equivalent to or improve over the reference, and collect over 26K human judgements for candidates produced by multiple QA systems on SQuAD. Through a careful analysis of this data, we reveal and quantify several concrete limitations of the F1 measure, such as false impression of graduality, missing dependence on question, and more. Since collecting AE annotations for each evaluated model is expensive, we learn a BERT matching BEM measure to approximate this task. Being a simpler task than QA, we find BEM to provide significantly better AE approximations than F1, and more accurately reflect the performance of systems. Finally, we also demonstrate the practical utility of AE and BEM on the concrete application of minimal accurate prediction sets, reducing the number of required answers by up to 2.6 times.
Boosting Search Engines with Interactive Agents
Sep 01, 2021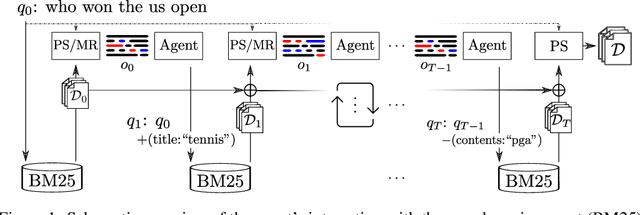
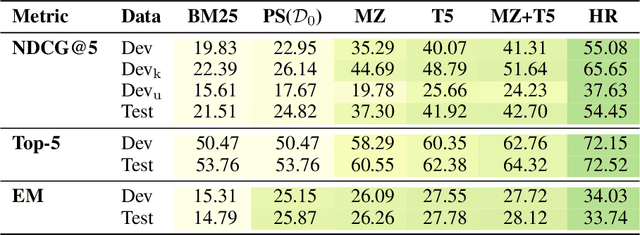
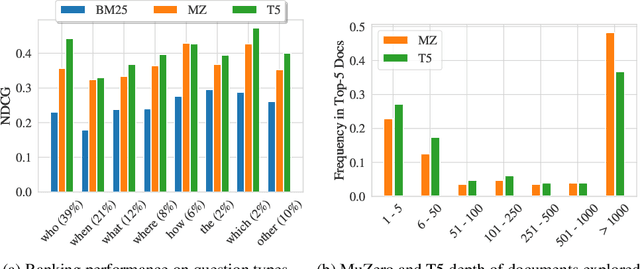

Can machines learn to use a search engine as an interactive tool for finding information? That would have far reaching consequences for making the world's knowledge more accessible. This paper presents first steps in designing agents that learn meta-strategies for contextual query refinements. Our approach uses machine reading to guide the selection of refinement terms from aggregated search results. Agents are then empowered with simple but effective search operators to exert fine-grained and transparent control over queries and search results. We develop a novel way of generating synthetic search sessions, which leverages the power of transformer-based generative language models through (self-)supervised learning. We also present a reinforcement learning agent with dynamically constrained actions that can learn interactive search strategies completely from scratch. In both cases, we obtain significant improvements over one-shot search with a strong information retrieval baseline. Finally, we provide an in-depth analysis of the learned search policies.
Meta Answering for Machine Reading
Nov 11, 2019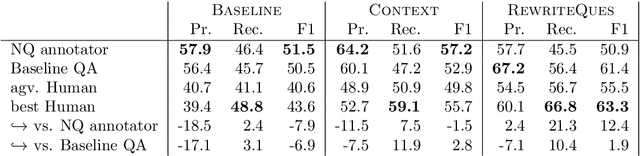
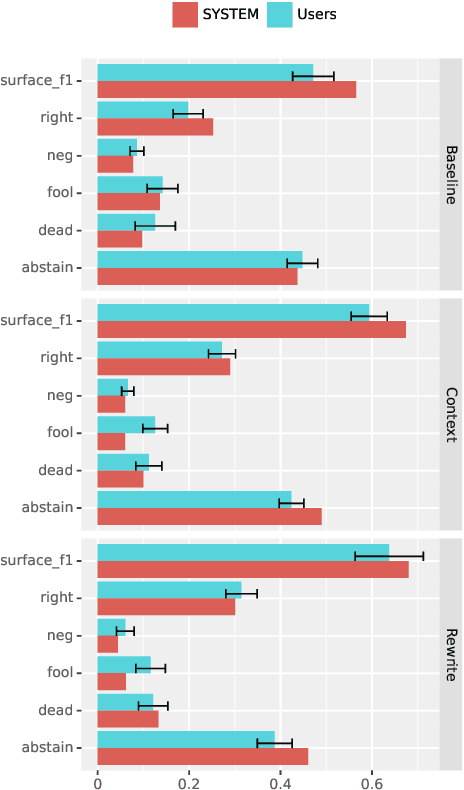

We investigate a framework for machine reading, inspired by real world information-seeking problems, where a meta question answering system interacts with a black box environment. The environment encapsulates a competitive machine reader based on BERT, providing candidate answers to questions, and possibly some context. To validate the realism of our formulation, we ask humans to play the role of a meta-answerer. With just a small snippet of text around an answer, humans can outperform the machine reader, improving recall. Similarly, a simple machine meta-answerer outperforms the environment, improving both precision and recall on the Natural Questions dataset. The system relies on joint training of answer scoring and the selection of conditioning information.
Zero-Shot Dual Machine Translation
May 25, 2018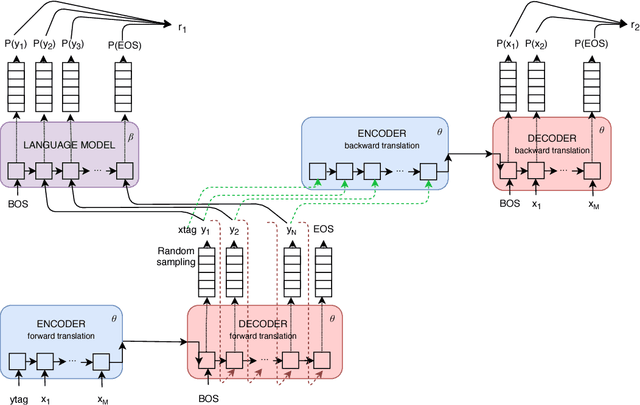
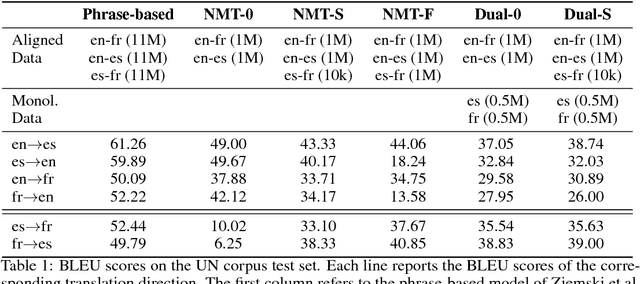
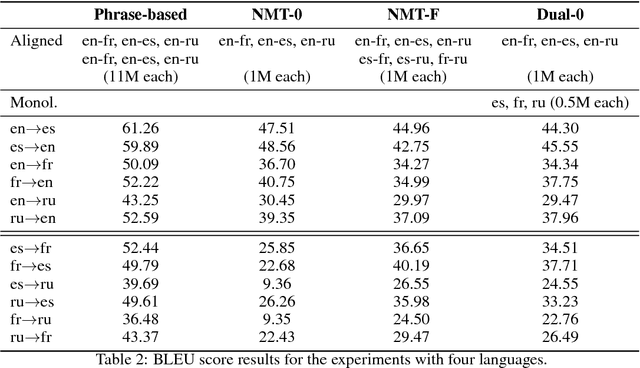
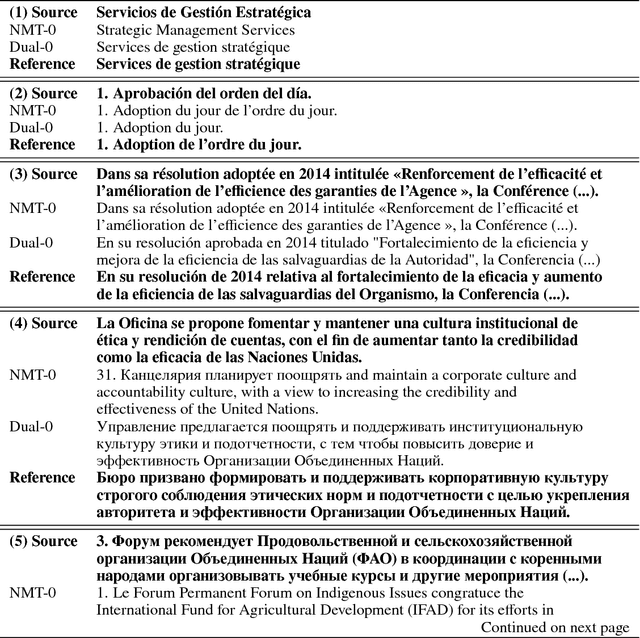
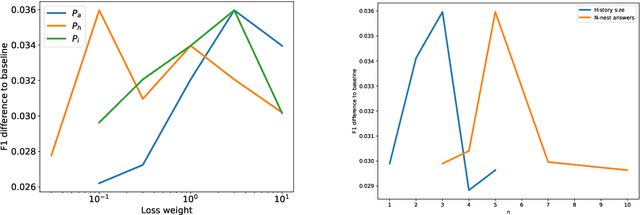
Neural Machine Translation (NMT) systems rely on large amounts of parallel data. This is a major challenge for low-resource languages. Building on recent work on unsupervised and semi-supervised methods, we present an approach that combines zero-shot and dual learning. The latter relies on reinforcement learning, to exploit the duality of the machine translation task, and requires only monolingual data for the target language pair. Experiments show that a zero-shot dual system, trained on English-French and English-Spanish, outperforms by large margins a standard NMT system in zero-shot translation performance on Spanish-French (both directions). The zero-shot dual method approaches the performance, within 2.2 BLEU points, of a comparable supervised setting. Our method can obtain improvements also on the setting where a small amount of parallel data for the zero-shot language pair is available. Adding Russian, to extend our experiments to jointly modeling 6 zero-shot translation directions, all directions improve between 4 and 15 BLEU points, again, reaching performance near that of the supervised setting.
Ask the Right Questions: Active Question Reformulation with Reinforcement Learning
Mar 02, 2018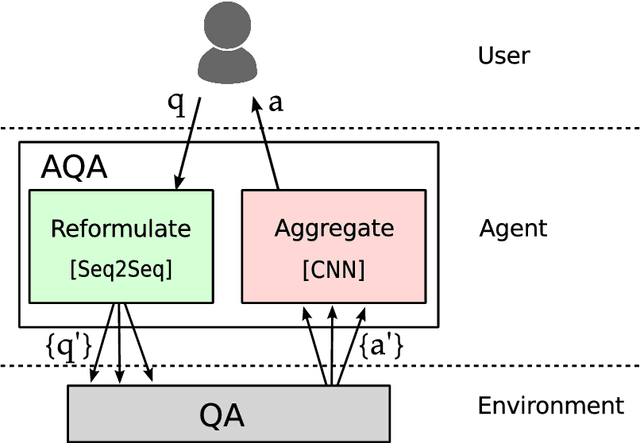
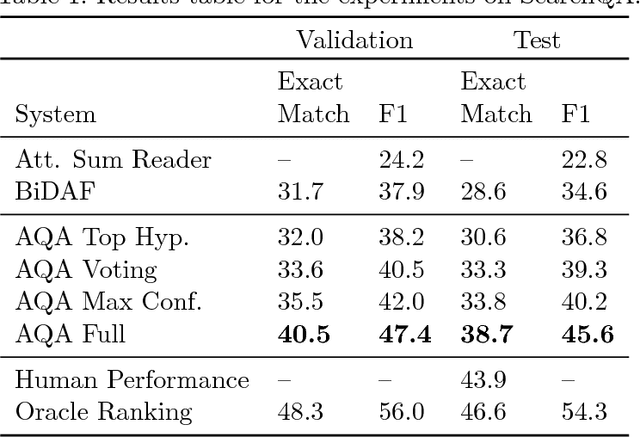
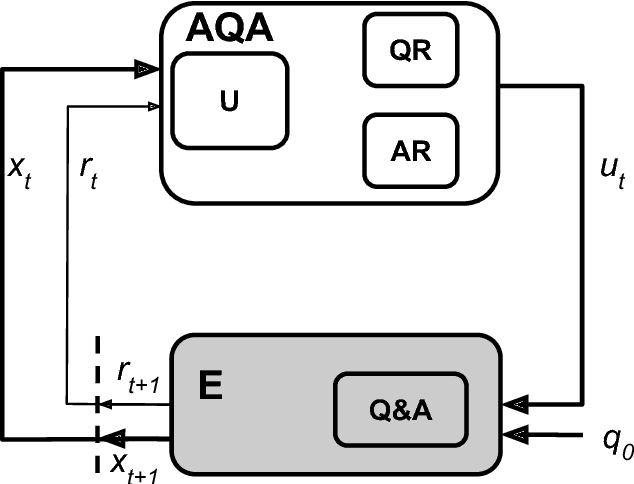
We frame Question Answering (QA) as a Reinforcement Learning task, an approach that we call Active Question Answering. We propose an agent that sits between the user and a black box QA system and learns to reformulate questions to elicit the best possible answers. The agent probes the system with, potentially many, natural language reformulations of an initial question and aggregates the returned evidence to yield the best answer. The reformulation system is trained end-to-end to maximize answer quality using policy gradient. We evaluate on SearchQA, a dataset of complex questions extracted from Jeopardy!. The agent outperforms a state-of-the-art base model, playing the role of the environment, and other benchmarks. We also analyze the language that the agent has learned while interacting with the question answering system. We find that successful question reformulations look quite different from natural language paraphrases. The agent is able to discover non-trivial reformulation strategies that resemble classic information retrieval techniques such as term re-weighting (tf-idf) and stemming.
Analyzing Language Learned by an Active Question Answering Agent
Jan 23, 2018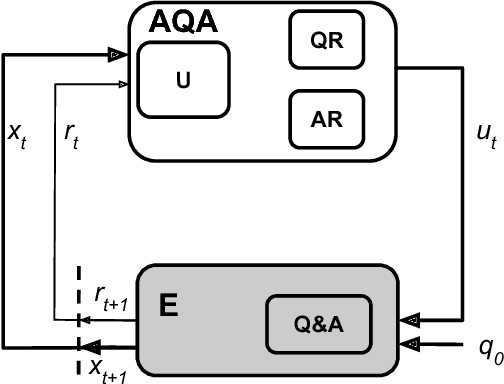
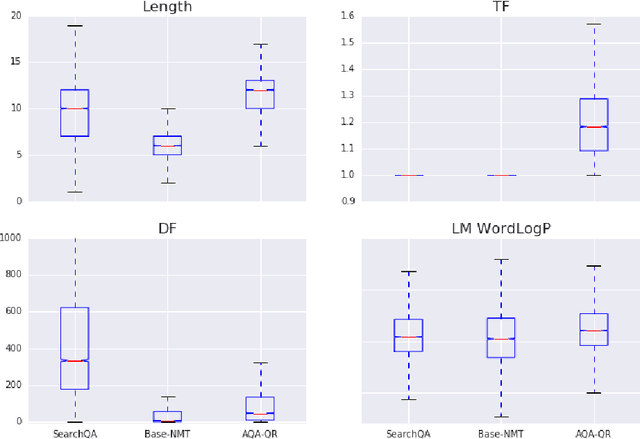
We analyze the language learned by an agent trained with reinforcement learning as a component of the ActiveQA system [Buck et al., 2017]. In ActiveQA, question answering is framed as a reinforcement learning task in which an agent sits between the user and a black box question-answering system. The agent learns to reformulate the user's questions to elicit the optimal answers. It probes the system with many versions of a question that are generated via a sequence-to-sequence question reformulation model, then aggregates the returned evidence to find the best answer. This process is an instance of \emph{machine-machine} communication. The question reformulation model must adapt its language to increase the quality of the answers returned, matching the language of the question answering system. We find that the agent does not learn transformations that align with semantic intuitions but discovers through learning classical information retrieval techniques such as tf-idf re-weighting and stemming.