 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Language Learned by an Active Question Answering Agent
Paper and Code
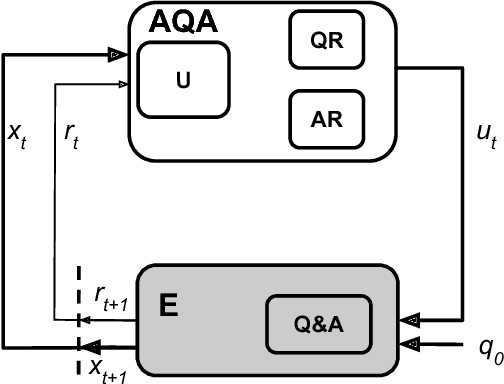
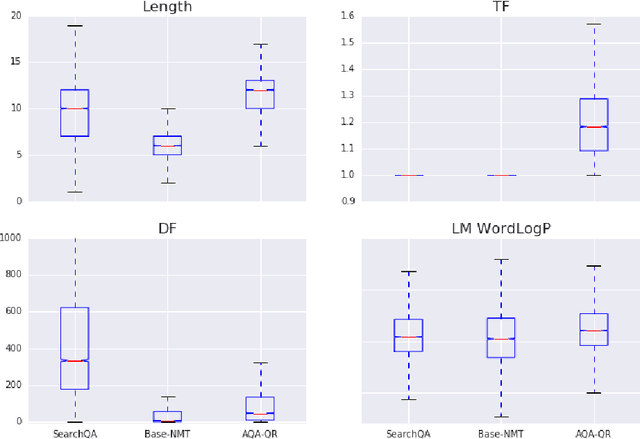
We analyze the language learned by an agent trained with reinforcement learning as a component of the ActiveQA system [Buck et al., 2017]. In ActiveQA, question answering is framed as a reinforcement learning task in which an agent sits between the user and a black box question-answering system. The agent learns to reformulate the user's questions to elicit the optimal answers. It probes the system with many versions of a question that are generated via a sequence-to-sequence question reformulation model, then aggregates the returned evidence to find the best answer. This process is an instance of \emph{machine-machine} communication. The question reformulation model must adapt its language to increase the quality of the answers returned, matching the language of the question answering system. We find that the agent does not learn transformations that align with semantic intuitions but discovers through learning classical information retrieval techniques such as tf-idf re-weighting and stemming.