 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrincipled Gradient-based Markov Chain Monte Carlo for Text Generation
Dec 29, 2023Recent papers have demonstrated the possibility of energy-based text generation by adapting gradient-based sampling algorithms, a paradigm of MCMC algorithms that promises fast convergence. However, as we show in this paper, previous attempts on this approach to text generation all fail to sample correctly from the target language model distributions. To address this limitation, we consider the problem of designing text samplers that are faithful, meaning that they have the target text distribution as its limiting distribution. We propose several faithful gradient-based sampling algorithms to sample from the target energy-based text distribution correctly, and study their theoretical properties. Through experiments on various forms of text generation, we demonstrate that faithful samplers are able to generate more fluent text while adhering to the control objectives better.
Towards Verifiable Text Generation with Symbolic References
Nov 15, 2023
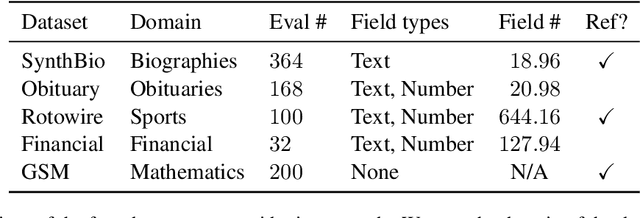
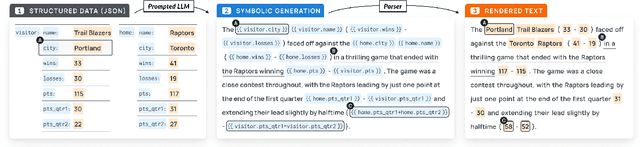
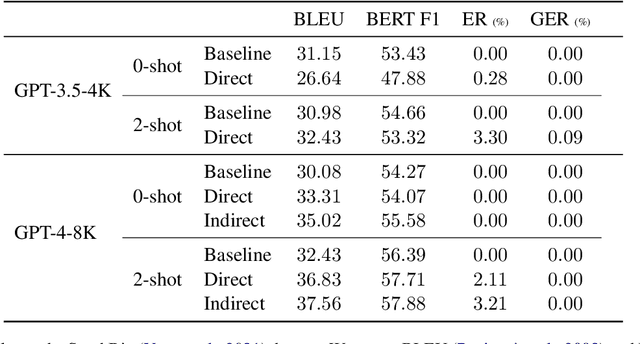
Large language models (LLMs) have demonstrated an impressive ability to synthesize plausible and fluent text. However they remain vulnerable to hallucinations, and thus their outputs generally require manual human verification for high-stakes applications, which can be time-consuming and difficult. This paper proposes symbolically grounded generation (SymGen) as a simple approach for enabling easier validation of an LLM's output. SymGen prompts an LLM to interleave its regular output text with explicit symbolic references to fields present in some conditioning data (e.g., a table in JSON format). The references can be used to display the provenance of different spans of text in the generation, reducing the effort required for manual verification. Across data-to-text and question answering experiments, we find that LLMs are able to directly output text that makes use of symbolic references while maintaining fluency and accuracy.
Generalizing Backpropagation for Gradient-Based Interpretability
Jul 06, 2023



Many popular feature-attribution methods for interpreting deep neural networks rely on computing the gradients of a model's output with respect to its inputs. While these methods can indicate which input features may be important for the model's prediction, they reveal little about the inner workings of the model itself. In this paper, we observe that the gradient computation of a model is a special case of a more general formulation using semirings. This observation allows us to generalize the backpropagation algorithm to efficiently compute other interpretable statistics about the gradient graph of a neural network, such as the highest-weighted path and entropy. We implement this generalized algorithm, evaluate it on synthetic datasets to better understand the statistics it computes, and apply it to study BERT's behavior on the subject-verb number agreement task (SVA). With this method, we (a) validate that the amount of gradient flow through a component of a model reflects its importance to a prediction and (b) for SVA, identify which pathways of the self-attention mechanism are most important.
Deriving Language Models from Masked Language Models
May 24, 2023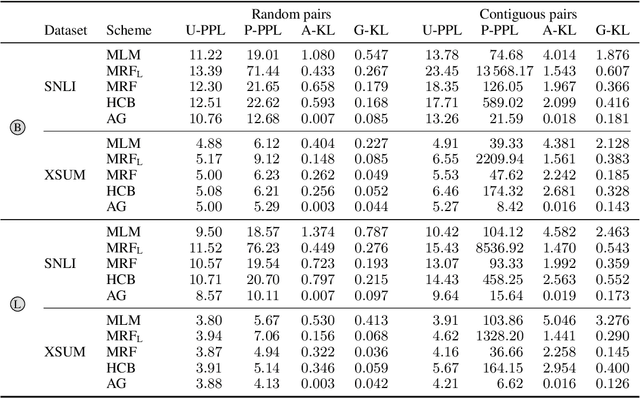
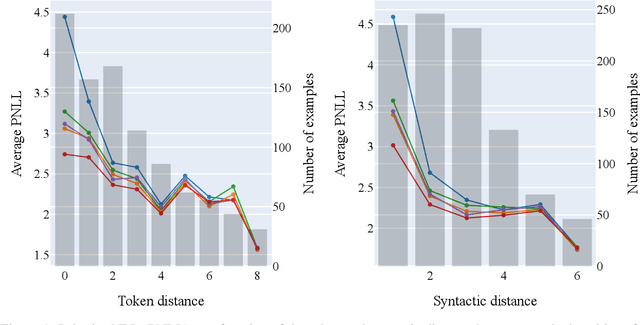
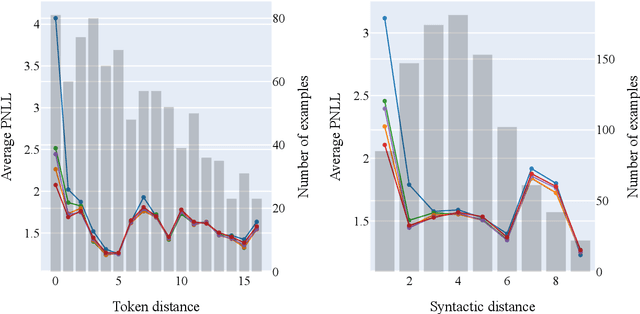
Masked language models (MLM) do not explicitly define a distribution over language, i.e., they are not language models per se. However, recent work has implicitly treated them as such for the purposes of generation and scoring. This paper studies methods for deriving explicit joint distributions from MLMs, focusing on distributions over two tokens, which makes it possible to calculate exact distributional properties. We find that an approach based on identifying joints whose conditionals are closest to those of the MLM works well and outperforms existing Markov random field-based approaches. We further find that this derived model's conditionals can even occasionally outperform the original MLM's conditionals.
Learning to Grow Pretrained Models for Efficient Transformer Training
Mar 02, 2023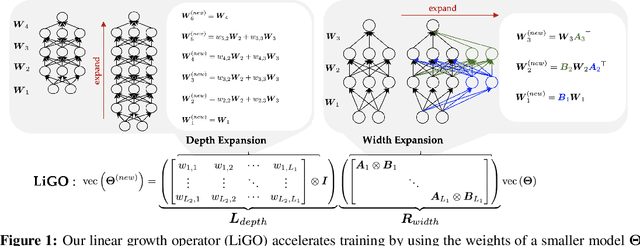

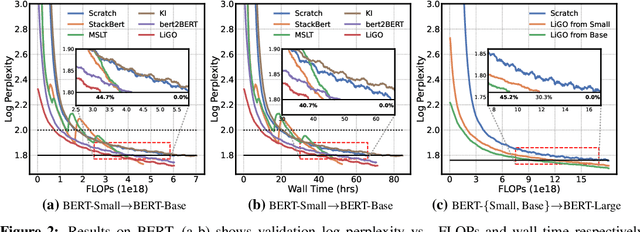
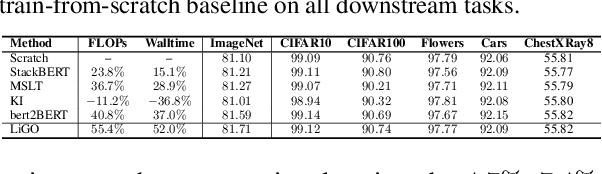
Scaling transformers has led to significant breakthroughs in many domains, leading to a paradigm in which larger versions of existing models are trained and released on a periodic basis. New instances of such models are typically trained completely from scratch, despite the fact that they are often just scaled-up versions of their smaller counterparts. How can we use the implicit knowledge in the parameters of smaller, extant models to enable faster training of newer, larger models? This paper describes an approach for accelerating transformer training by learning to grow pretrained transformers, where we learn to linearly map the parameters of the smaller model to initialize the larger model. For tractable learning, we factorize the linear transformation as a composition of (linear) width- and depth-growth operators, and further employ a Kronecker factorization of these growth operators to encode architectural knowledge. Extensive experiments across both language and vision transformers demonstrate that our learned Linear Growth Operator (LiGO) can save up to 50% computational cost of training from scratch, while also consistently outperforming strong baselines that also reuse smaller pretrained models to initialize larger models.
A Measure-Theoretic Characterization of Tight Language Models
Dec 20, 2022
Language modeling, a central task in natural language processing, involves estimating a probability distribution over strings. In most cases, the estimated distribution sums to 1 over all finite strings. However, in some pathological cases, probability mass can ``leak'' onto the set of infinite sequences. In order to characterize the notion of leakage more precisely, this paper offers a measure-theoretic treatment of language modeling. We prove that many popular language model families are in fact tight, meaning that they will not leak in this sense. We also generalize characterizations of tightness proposed in previous works.
An Ordinal Latent Variable Model of Conflict Intensity
Oct 08, 2022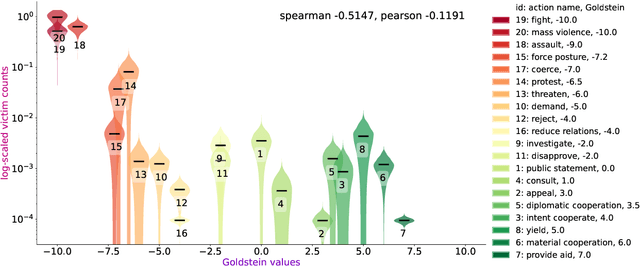
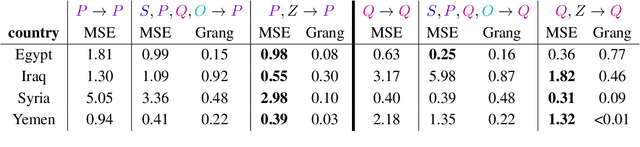
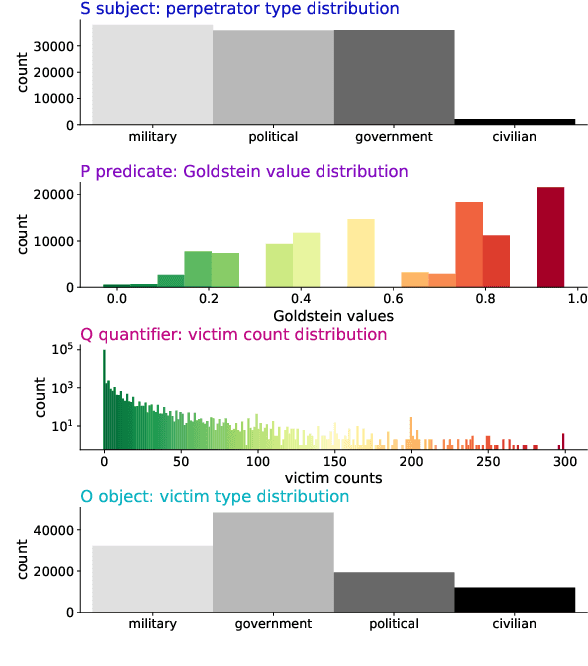

For the quantitative monitoring of international relations, political events are extracted from the news and parsed into "who-did-what-to-whom" patterns. This has resulted in large data collections which require aggregate statistics for analysis. The Goldstein Scale is an expert-based measure that ranks individual events on a one-dimensional scale from conflictual to cooperative. However, the scale disregards fatality counts as well as perpetrator and victim types involved in an event. This information is typically considered in qualitative conflict assessment. To address this limitation, we propose a probabilistic generative model over the full subject-predicate-quantifier-object tuples associated with an event. We treat conflict intensity as an interpretable, ordinal latent variable that correlates conflictual event types with high fatality counts. Taking a Bayesian approach, we learn a conflict intensity scale from data and find the optimal number of intensity classes. We evaluate the model by imputing missing data. Our scale proves to be more informative than the original Goldstein Scale in autoregressive forecasting and when compared with global online attention towards armed conflicts.
UniMorph 4.0: Universal Morphology
May 10, 2022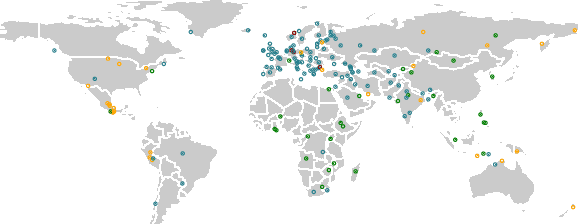

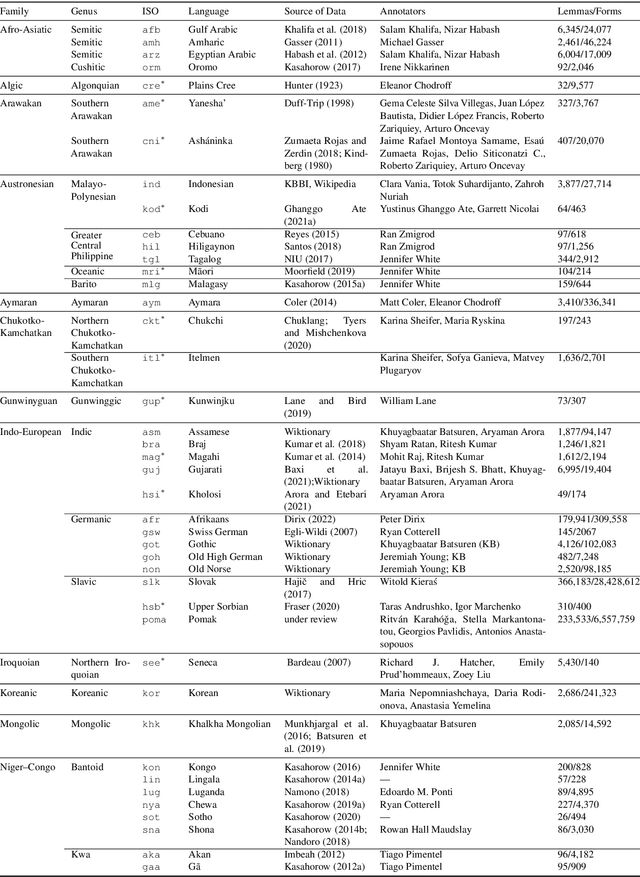
The Universal Morphology (UniMorph) project is a collaborative effort providing broad-coverage instantiated normalized morphological inflection tables for hundreds of diverse world languages. The project comprises two major thrusts: a language-independent feature schema for rich morphological annotation and a type-level resource of annotated data in diverse languages realizing that schema. This paper presents the expansions and improvements made on several fronts over the last couple of years (since McCarthy et al. (2020)). Collaborative efforts by numerous linguists have added 67 new languages, including 30 endangered languages. We have implemented several improvements to the extraction pipeline to tackle some issues, e.g. missing gender and macron information. We have also amended the schema to use a hierarchical structure that is needed for morphological phenomena like multiple-argument agreement and case stacking, while adding some missing morphological features to make the schema more inclusive. In light of the last UniMorph release, we also augmented the database with morpheme segmentation for 16 languages. Lastly, this new release makes a push towards inclusion of derivational morphology in UniMorph by enriching the data and annotation schema with instances representing derivational processes from MorphyNet.
Same Neurons, Different Languages: Probing Morphosyntax in Multilingual Pre-trained Models
May 08, 2022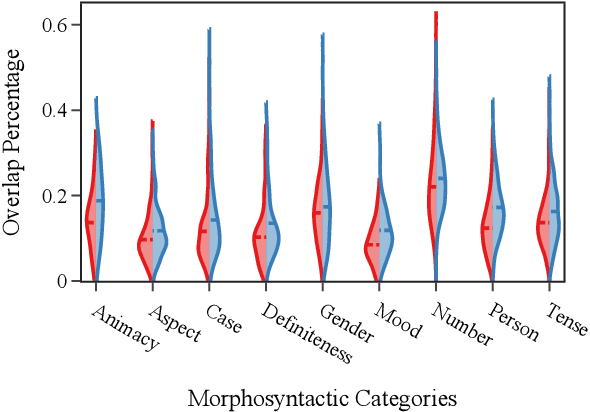
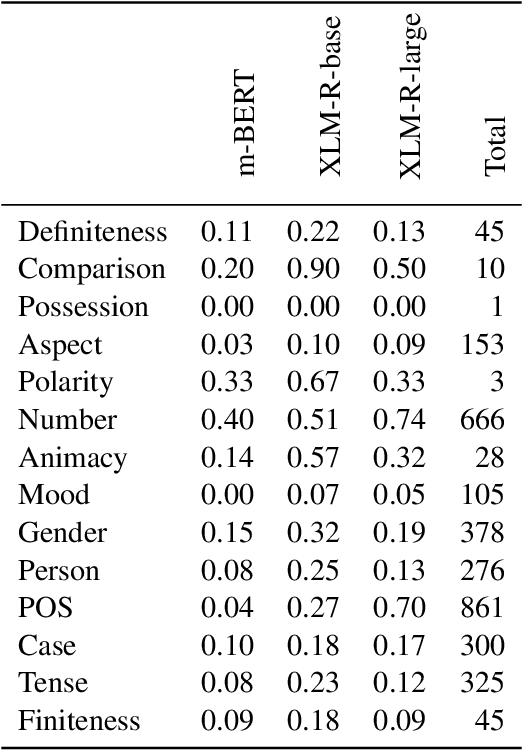
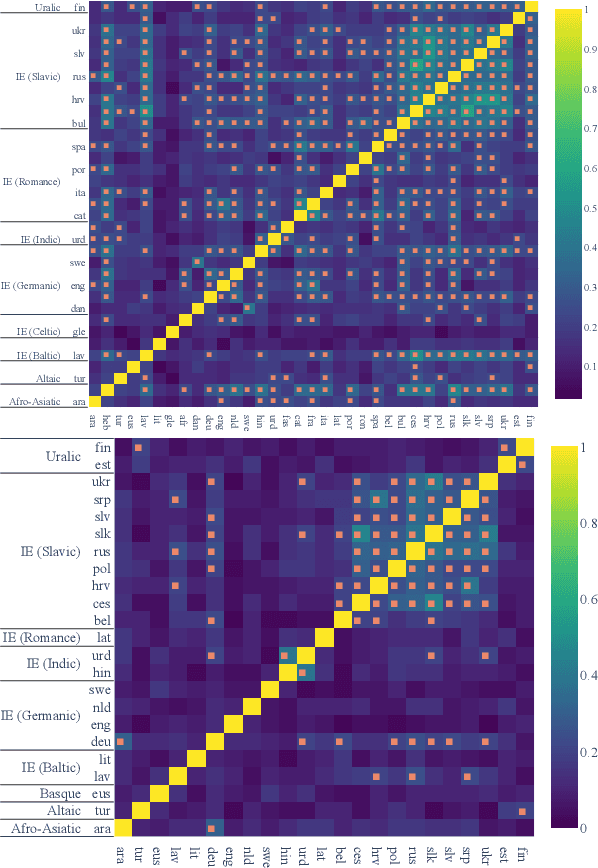
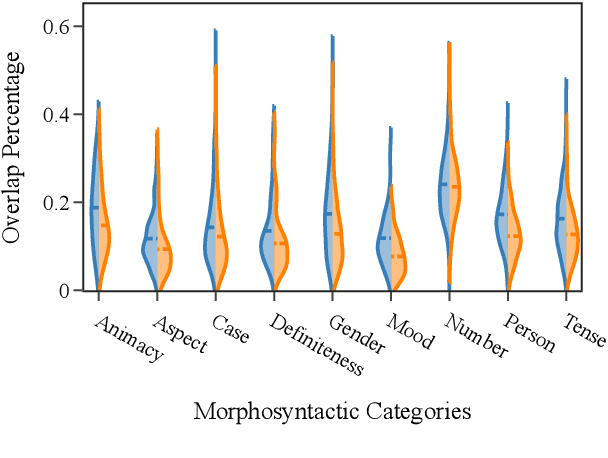
The success of multilingual pre-trained models is underpinned by their ability to learn representations shared by multiple languages even in absence of any explicit supervision. However, it remains unclear how these models learn to generalise across languages. In this work, we conjecture that multilingual pre-trained models can derive language-universal abstractions about grammar. In particular, we investigate whether morphosyntactic information is encoded in the same subset of neurons in different languages. We conduct the first large-scale empirical study over 43 languages and 14 morphosyntactic categories with a state-of-the-art neuron-level probe. Our findings show that the cross-lingual overlap between neurons is significant, but its extent may vary across categories and depends on language proximity and pre-training data size.
A Latent-Variable Model for Intrinsic Probing
Jan 20, 2022The success of pre-trained contextualized representations has prompted researchers to analyze them for the presence of linguistic information. Indeed, it is natural to assume that these pre-trained representations do encode some level of linguistic knowledge as they have brought about large empirical improvements on a wide variety of NLP tasks, which suggests they are learning true linguistic generalization. In this work, we focus on intrinsic probing, an analysis technique where the goal is not only to identify whether a representation encodes a linguistic attribute, but also to pinpoint where this attribute is encoded. We propose a novel latent-variable formulation for constructing intrinsic probes and derive a tractable variational approximation to the log-likelihood. Our results show that our model is versatile and yields tighter mutual information estimates than two intrinsic probes previously proposed in the literature. Finally, we find empirical evidence that pre-trained representations develop a cross-lingually entangled notion of morphosyntax.