 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodied Concept Learner: Self-supervised Learning of Concepts and Mapping through Instruction Following
Apr 07, 2023



Humans, even at a very early age, can learn visual concepts and understand geometry and layout through active interaction with the environment, and generalize their compositions to complete tasks described by natural languages in novel scenes. To mimic such capability, we propose Embodied Concept Learner (ECL) in an interactive 3D environment. Specifically, a robot agent can ground visual concepts, build semantic maps and plan actions to complete tasks by learning purely from human demonstrations and language instructions, without access to ground-truth semantic and depth supervisions from simulations. ECL consists of: (i) an instruction parser that translates the natural languages into executable programs; (ii) an embodied concept learner that grounds visual concepts based on language descriptions; (iii) a map constructor that estimates depth and constructs semantic maps by leveraging the learned concepts; and (iv) a program executor with deterministic policies to execute each program. ECL has several appealing benefits thanks to its modularized design. Firstly, it enables the robotic agent to learn semantics and depth unsupervisedly acting like babies, e.g., ground concepts through active interaction and perceive depth by disparities when moving forward. Secondly, ECL is fully transparent and step-by-step interpretable in long-term planning. Thirdly, ECL could be beneficial for the embodied instruction following (EIF), outperforming previous works on the ALFRED benchmark when the semantic label is not provided. Also, the learned concept can be reused for other downstream tasks, such as reasoning of object states. Project page: http://ecl.csail.mit.edu/
Learning to Grow Pretrained Models for Efficient Transformer Training
Mar 02, 2023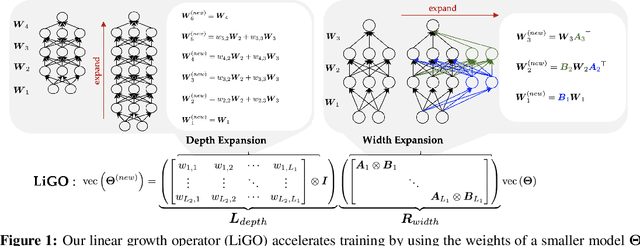

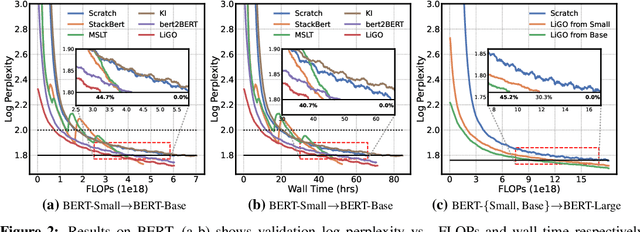
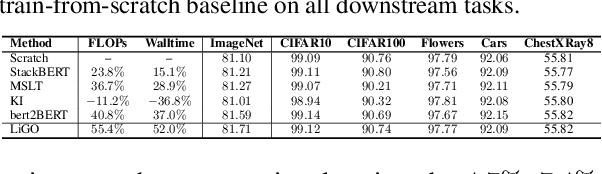
Scaling transformers has led to significant breakthroughs in many domains, leading to a paradigm in which larger versions of existing models are trained and released on a periodic basis. New instances of such models are typically trained completely from scratch, despite the fact that they are often just scaled-up versions of their smaller counterparts. How can we use the implicit knowledge in the parameters of smaller, extant models to enable faster training of newer, larger models? This paper describes an approach for accelerating transformer training by learning to grow pretrained transformers, where we learn to linearly map the parameters of the smaller model to initialize the larger model. For tractable learning, we factorize the linear transformation as a composition of (linear) width- and depth-growth operators, and further employ a Kronecker factorization of these growth operators to encode architectural knowledge. Extensive experiments across both language and vision transformers demonstrate that our learned Linear Growth Operator (LiGO) can save up to 50% computational cost of training from scratch, while also consistently outperforming strong baselines that also reuse smaller pretrained models to initialize larger models.