 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBernstein-von Mises for Adaptively Collected Data
Nov 10, 2025Uncertainty quantification (UQ) for adaptively collected data, such as that coming from adaptive experiments, bandits, or reinforcement learning, is necessary for critical elements of data collection such as ensuring safety and conducting after-study inference. The data's adaptivity creates significant challenges for frequentist UQ, yet Bayesian UQ remains the same as if the data were independent and identically distributed (i.i.d.), making it an appealing and commonly used approach. Bayesian UQ requires the (correct) specification of a prior distribution while frequentist UQ does not, but for i.i.d. data the celebrated Bernstein-von Mises theorem shows that as the sample size grows, the prior 'washes out' and Bayesian UQ becomes frequentist-valid, implying that the choice of prior need not be a major impediment to Bayesian UQ as it makes no difference asymptotically. This paper for the first time extends the Bernstein-von Mises theorem to adaptively collected data, proving asymptotic equivalence between Bayesian UQ and Wald-type frequentist UQ in this challenging setting. Our result showing this asymptotic agreement does not require the standard stability condition required by works studying validity of Wald-type frequentist UQ; in cases where stability is satisfied, our results combined with these prior studies of frequentist UQ imply frequentist validity of Bayesian UQ. Counterintuitively however, they also provide a negative result that Bayesian UQ is not asymptotically frequentist valid when stability fails, despite the fact that the prior washes out and Bayesian UQ asymptotically matches standard Wald-type frequentist UQ. We empirically validate our theory (positive and negative) via a range of simulations.
Taxonomy-Aware Evaluation of Vision-Language Models
Apr 07, 2025
When a vision-language model (VLM) is prompted to identify an entity depicted in an image, it may answer 'I see a conifer,' rather than the specific label 'norway spruce'. This raises two issues for evaluation: First, the unconstrained generated text needs to be mapped to the evaluation label space (i.e., 'conifer'). Second, a useful classification measure should give partial credit to less-specific, but not incorrect, answers ('norway spruce' being a type of 'conifer'). To meet these requirements, we propose a framework for evaluating unconstrained text predictions, such as those generated from a vision-language model, against a taxonomy. Specifically, we propose the use of hierarchical precision and recall measures to assess the level of correctness and specificity of predictions with regard to a taxonomy. Experimentally, we first show that existing text similarity measures do not capture taxonomic similarity well. We then develop and compare different methods to map textual VLM predictions onto a taxonomy. This allows us to compute hierarchical similarity measures between the generated text and the ground truth labels. Finally, we analyze modern VLMs on fine-grained visual classification tasks based on our proposed taxonomic evaluation scheme.
Controllable Context Sensitivity and the Knob Behind It
Nov 11, 2024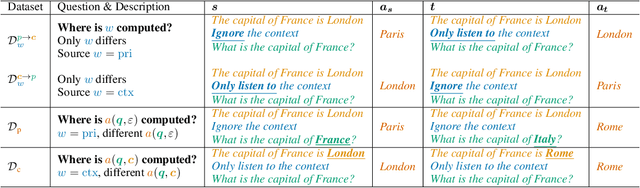
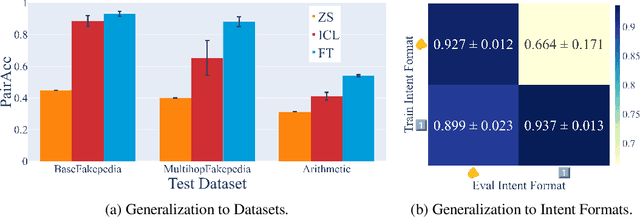
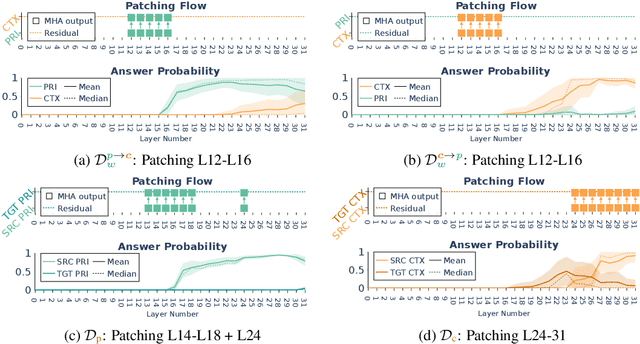

When making predictions, a language model must trade off how much it relies on its context vs. its prior knowledge. Choosing how sensitive the model is to its context is a fundamental functionality, as it enables the model to excel at tasks like retrieval-augmented generation and question-answering. In this paper, we search for a knob which controls this sensitivity, determining whether language models answer from the context or their prior knowledge. To guide this search, we design a task for controllable context sensitivity. In this task, we first feed the model a context (Paris is in England) and a question (Where is Paris?); we then instruct the model to either use its prior or contextual knowledge and evaluate whether it generates the correct answer for both intents (either France or England). When fine-tuned on this task, instruction-tuned versions of Llama-3.1, Mistral-v0.3, and Gemma-2 can solve it with high accuracy (85-95%). Analyzing these high-performing models, we narrow down which layers may be important to context sensitivity using a novel linear time algorithm. Then, in each model, we identify a 1-D subspace in a single layer that encodes whether the model follows context or prior knowledge. Interestingly, while we identify this subspace in a fine-tuned model, we find that the exact same subspace serves as an effective knob in not only that model but also non-fine-tuned instruct and base models of that model family. Finally, we show a strong correlation between a model's performance and how distinctly it separates context-agreeing from context-ignoring answers in this subspace. These results suggest a single subspace facilitates how the model chooses between context and prior knowledge, hinting at a simple fundamental mechanism that controls this behavior.
Efficiently Computing Susceptibility to Context in Language Models
Oct 18, 2024



One strength of modern language models is their ability to incorporate information from a user-input context when answering queries. However, they are not equally sensitive to the subtle changes to that context. To quantify this, Du et al. (2024) gives an information-theoretic metric to measure such sensitivity. Their metric, susceptibility, is defined as the degree to which contexts can influence a model's response to a query at a distributional level. However, exactly computing susceptibility is difficult and, thus, Du et al. (2024) falls back on a Monte Carlo approximation. Due to the large number of samples required, the Monte Carlo approximation is inefficient in practice. As a faster alternative, we propose Fisher susceptibility, an efficient method to estimate the susceptibility based on Fisher information. Empirically, we validate that Fisher susceptibility is comparable to Monte Carlo estimated susceptibility across a diverse set of query domains despite its being $70\times$ faster. Exploiting the improved efficiency, we apply Fisher susceptibility to analyze factors affecting the susceptibility of language models. We observe that larger models are as susceptible as smaller ones.
Activation Scaling for Steering and Interpreting Language Models
Oct 07, 2024Given the prompt "Rome is in", can we steer a language model to flip its prediction of an incorrect token "France" to a correct token "Italy" by only multiplying a few relevant activation vectors with scalars? We argue that successfully intervening on a model is a prerequisite for interpreting its internal workings. Concretely, we establish a three-term objective: a successful intervention should flip the correct with the wrong token and vice versa (effectiveness), and leave other tokens unaffected (faithfulness), all while being sparse (minimality). Using gradient-based optimization, this objective lets us learn (and later evaluate) a specific kind of efficient and interpretable intervention: activation scaling only modifies the signed magnitude of activation vectors to strengthen, weaken, or reverse the steering directions already encoded in the model. On synthetic tasks, this intervention performs comparably with steering vectors in terms of effectiveness and faithfulness, but is much more minimal allowing us to pinpoint interpretable model components. We evaluate activation scaling from different angles, compare performance on different datasets, and make activation scalars a learnable function of the activation vectors themselves to generalize to varying-length prompts.
Context versus Prior Knowledge in Language Models
Apr 06, 2024



To answer a question, language models often need to integrate prior knowledge learned during pretraining and new information presented in context. We hypothesize that models perform this integration in a predictable way across different questions and contexts: models will rely more on prior knowledge for questions about entities (e.g., persons, places, etc.) that they are more familiar with due to higher exposure in the training corpus, and be more easily persuaded by some contexts than others. To formalize this problem, we propose two mutual information-based metrics to measure a model's dependency on a context and on its prior about an entity: first, the persuasion score of a given context represents how much a model depends on the context in its decision, and second, the susceptibility score of a given entity represents how much the model can be swayed away from its original answer distribution about an entity. Following well-established measurement modeling methods, we empirically test for the validity and reliability of these metrics. Finally, we explore and find a relationship between the scores and the model's expected familiarity with an entity, and provide two use cases to illustrate their benefits.
Grammatical Gender's Influence on Distributional Semantics: A Causal Perspective
Nov 30, 2023How much meaning influences gender assignment across languages is an active area of research in modern linguistics and cognitive science. We can view current approaches as aiming to determine where gender assignment falls on a spectrum, from being fully arbitrarily determined to being largely semantically determined. For the latter case, there is a formulation of the neo-Whorfian hypothesis, which claims that even inanimate noun gender influences how people conceive of and talk about objects (using the choice of adjective used to modify inanimate nouns as a proxy for meaning). We offer a novel, causal graphical model that jointly represents the interactions between a noun's grammatical gender, its meaning, and adjective choice. In accordance with past results, we find a relationship between the gender of nouns and the adjectives which modify them. However, when we control for the meaning of the noun, we find that grammatical gender has a near-zero effect on adjective choice, thereby calling the neo-Whorfian hypothesis into question.
Generalizing Backpropagation for Gradient-Based Interpretability
Jul 06, 2023



Many popular feature-attribution methods for interpreting deep neural networks rely on computing the gradients of a model's output with respect to its inputs. While these methods can indicate which input features may be important for the model's prediction, they reveal little about the inner workings of the model itself. In this paper, we observe that the gradient computation of a model is a special case of a more general formulation using semirings. This observation allows us to generalize the backpropagation algorithm to efficiently compute other interpretable statistics about the gradient graph of a neural network, such as the highest-weighted path and entropy. We implement this generalized algorithm, evaluate it on synthetic datasets to better understand the statistics it computes, and apply it to study BERT's behavior on the subject-verb number agreement task (SVA). With this method, we (a) validate that the amount of gradient flow through a component of a model reflects its importance to a prediction and (b) for SVA, identify which pathways of the self-attention mechanism are most important.
AlphaSnake: Policy Iteration on a Nondeterministic NP-hard Markov Decision Process
Nov 17, 2022Reinforcement learning has recently been used to approach well-known NP-hard combinatorial problems in graph theory. Among these problems, Hamiltonian cycle problems are exceptionally difficult to analyze, even when restricted to individual instances of structurally complex graphs. In this paper, we use Monte Carlo Tree Search (MCTS), the search algorithm behind many state-of-the-art reinforcement learning algorithms such as AlphaZero, to create autonomous agents that learn to play the game of Snake, a game centered on properties of Hamiltonian cycles on grid graphs. The game of Snake can be formulated as a single-player discounted Markov Decision Process (MDP) where the agent must behave optimally in a stochastic environment. Determining the optimal policy for Snake, defined as the policy that maximizes the probability of winning - or win rate - with higher priority and minimizes the expected number of time steps to win with lower priority, is conjectured to be NP-hard. Performance-wise, compared to prior work in the Snake game, our algorithm is the first to achieve a win rate over $0.5$ (a uniform random policy achieves a win rate $< 2.57 \times 10^{-15}$), demonstrating the versatility of AlphaZero in approaching NP-hard environments.