 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Transformer with Stack Attention
May 07, 2024



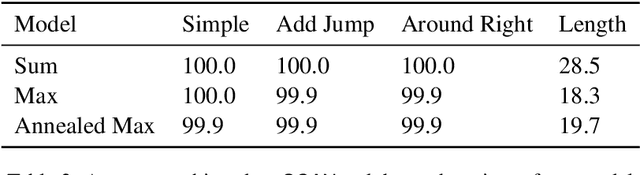
Natural languages are believed to be (mildly) context-sensitive. Despite underpinning remarkably capable large language models, transformers are unable to model many context-free language tasks. In an attempt to address this limitation in the modeling power of transformer-based language models, we propose augmenting them with a differentiable, stack-based attention mechanism. Our stack-based attention mechanism can be incorporated into any transformer-based language model and adds a level of interpretability to the model. We show that the addition of our stack-based attention mechanism enables the transformer to model some, but not all, deterministic context-free languages.
Context versus Prior Knowledge in Language Models
Apr 06, 2024



To answer a question, language models often need to integrate prior knowledge learned during pretraining and new information presented in context. We hypothesize that models perform this integration in a predictable way across different questions and contexts: models will rely more on prior knowledge for questions about entities (e.g., persons, places, etc.) that they are more familiar with due to higher exposure in the training corpus, and be more easily persuaded by some contexts than others. To formalize this problem, we propose two mutual information-based metrics to measure a model's dependency on a context and on its prior about an entity: first, the persuasion score of a given context represents how much a model depends on the context in its decision, and second, the susceptibility score of a given entity represents how much the model can be swayed away from its original answer distribution about an entity. Following well-established measurement modeling methods, we empirically test for the validity and reliability of these metrics. Finally, we explore and find a relationship between the scores and the model's expected familiarity with an entity, and provide two use cases to illustrate their benefits.
Schrödinger's Bat: Diffusion Models Sometimes Generate Polysemous Words in Superposition
Nov 23, 2022
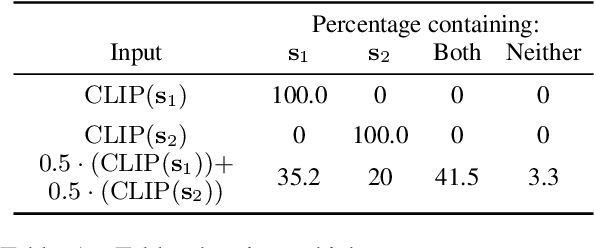

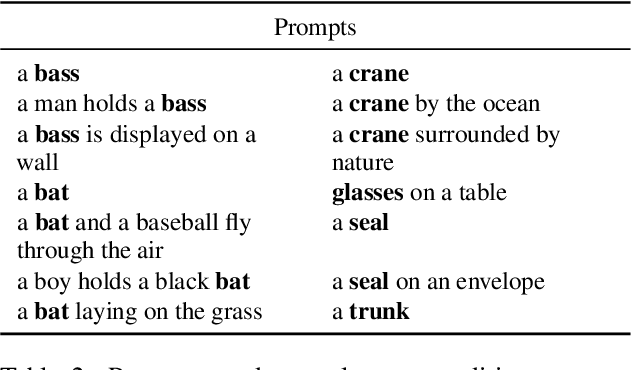
Recent work has shown that despite their impressive capabilities, text-to-image diffusion models such as DALL-E 2 (Ramesh et al., 2022) can display strange behaviours when a prompt contains a word with multiple possible meanings, often generating images containing both senses of the word (Rassin et al., 2022). In this work we seek to put forward a possible explanation of this phenomenon. Using the similar Stable Diffusion model (Rombach et al., 2022), we first show that when given an input that is the sum of encodings of two distinct words, the model can produce an image containing both concepts represented in the sum. We then demonstrate that the CLIP encoder used to encode prompts (Radford et al., 2021) encodes polysemous words as a superposition of meanings, and that using linear algebraic techniques we can edit these representations to influence the senses represented in the generated images. Combining these two findings, we suggest that the homonym duplication phenomenon described by Rassin et al. (2022) is caused by diffusion models producing images representing both of the meanings that are present in superposition in the encoding of a polysemous word.
Equivariant Transduction through Invariant Alignment
Sep 22, 2022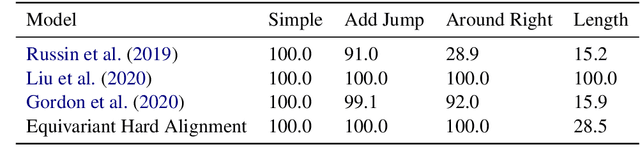

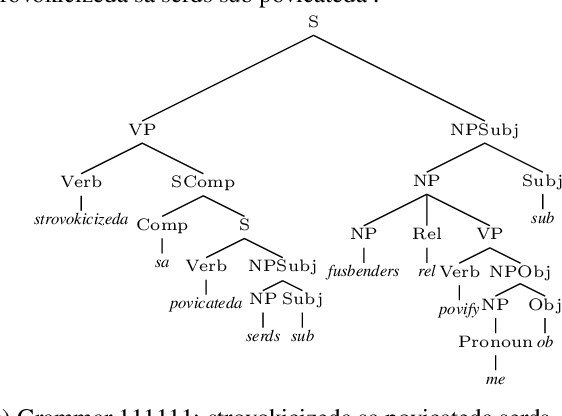
The ability to generalize compositionally is key to understanding the potentially infinite number of sentences that can be constructed in a human language from only a finite number of words. Investigating whether NLP models possess this ability has been a topic of interest: SCAN (Lake and Baroni, 2018) is one task specifically proposed to test for this property. Previous work has achieved impressive empirical results using a group-equivariant neural network that naturally encodes a useful inductive bias for SCAN (Gordon et al., 2020). Inspired by this, we introduce a novel group-equivariant architecture that incorporates a group-invariant hard alignment mechanism. We find that our network's structure allows it to develop stronger equivariance properties than existing group-equivariant approaches. We additionally find that it outperforms previous group-equivariant networks empirically on the SCAN task. Our results suggest that integrating group-equivariance into a variety of neural architectures is a potentially fruitful avenue of research, and demonstrate the value of careful analysis of the theoretical properties of such architectures.
Examining the Inductive Bias of Neural Language Models with Artificial Languages
Jun 02, 2021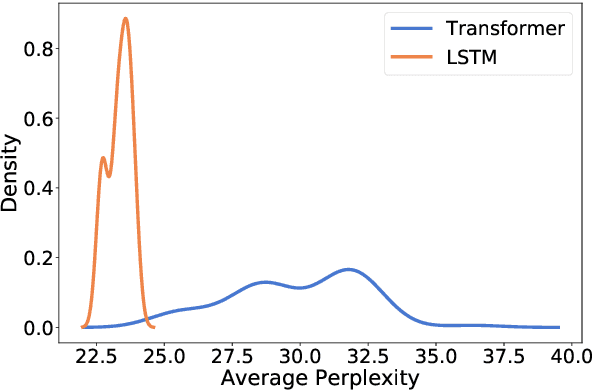


Since language models are used to model a wide variety of languages, it is natural to ask whether the neural architectures used for the task have inductive biases towards modeling particular types of languages. Investigation of these biases has proved complicated due to the many variables that appear in the experimental setup. Languages vary in many typological dimensions, and it is difficult to single out one or two to investigate without the others acting as confounders. We propose a novel method for investigating the inductive biases of language models using artificial languages. These languages are constructed to allow us to create parallel corpora across languages that differ only in the typological feature being investigated, such as word order. We then use them to train and test language models. This constitutes a fully controlled causal framework, and demonstrates how grammar engineering can serve as a useful tool for analyzing neural models. Using this method, we find that commonly used neural architectures exhibit different inductive biases: LSTMs display little preference with respect to word ordering, while transformers display a clear preference for some orderings over others. Further, we find that neither the inductive bias of the LSTM nor that of the transformer appears to reflect any tendencies that we see in attested natural languages.
A Non-Linear Structural Probe
May 21, 2021
Probes are models devised to investigate the encoding of knowledge -- e.g. syntactic structure -- in contextual representations. Probes are often designed for simplicity, which has led to restrictions on probe design that may not allow for the full exploitation of the structure of encoded information; one such restriction is linearity. We examine the case of a structural probe (Hewitt and Manning, 2019), which aims to investigate the encoding of syntactic structure in contextual representations through learning only linear transformations. By observing that the structural probe learns a metric, we are able to kernelize it and develop a novel non-linear variant with an identical number of parameters. We test on 6 languages and find that the radial-basis function (RBF) kernel, in conjunction with regularization, achieves a statistically significant improvement over the baseline in all languages -- implying that at least part of the syntactic knowledge is encoded non-linearly. We conclude by discussing how the RBF kernel resembles BERT's self-attention layers and speculate that this resemblance leads to the RBF-based probe's stronger performance.