 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-Universal Multiplicative Updates for Nonnegative Einsum Factorization
Feb 02, 2026Despite the ubiquity of multiway data across scientific domains, there are few user-friendly tools that fit tailored nonnegative tensor factorizations. Researchers may use gradient-based automatic differentiation (which often struggles in nonnegative settings), choose between a limited set of methods with mature implementations, or implement their own model from scratch. As an alternative, we introduce NNEinFact, an einsum-based multiplicative update algorithm that fits any nonnegative tensor factorization expressible as a tensor contraction by minimizing one of many user-specified loss functions (including the $(α,β)$-divergence). To use NNEinFact, the researcher simply specifies their model with a string. NNEinFact converges to a local minimum of the loss, supports missing data, and fits to tensors with hundreds of millions of entries in seconds. Empirically, NNEinFact fits custom models which outperform standard ones in heldout prediction tasks on real-world tensor data by over $37\%$ and attains less than half the test loss of gradient-based methods while converging up to 90 times faster.
Broad Spectrum Structure Discovery in Large-Scale Higher-Order Networks
May 27, 2025Complex systems are often driven by higher-order interactions among multiple units, naturally represented as hypergraphs. Understanding dependency structures within these hypergraphs is crucial for understanding and predicting the behavior of complex systems but is made challenging by their combinatorial complexity and computational demands. In this paper, we introduce a class of probabilistic models that efficiently represents and discovers a broad spectrum of mesoscale structure in large-scale hypergraphs. The key insight enabling this approach is to treat classes of similar units as themselves nodes in a latent hypergraph. By modeling observed node interactions through latent interactions among classes using low-rank representations, our approach tractably captures rich structural patterns while ensuring model identifiability. This allows for direct interpretation of distinct node- and class-level structures. Empirically, our model improves link prediction over state-of-the-art methods and discovers interpretable structures in diverse real-world systems, including pharmacological and social networks, advancing the ability to incorporate large-scale higher-order data into the scientific process.
Linear Representations of Political Perspective Emerge in Large Language Models
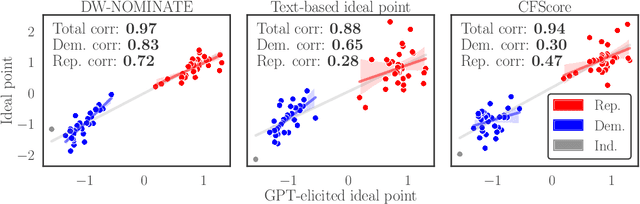
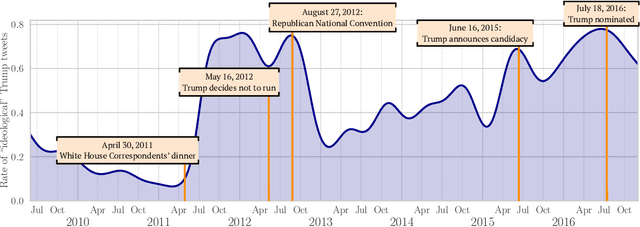
Mar 03, 2025Large language models (LLMs) have demonstrated the ability to generate text that realistically reflects a range of different subjective human perspectives. This paper studies how LLMs are seemingly able to reflect more liberal versus more conservative viewpoints among other political perspectives in American politics. We show that LLMs possess linear representations of political perspectives within activation space, wherein more similar perspectives are represented closer together. To do so, we probe the attention heads across the layers of three open transformer-based LLMs (\texttt{Llama-2-7b-chat}, \texttt{Mistral-7b-instruct}, \texttt{Vicuna-7b}). We first prompt models to generate text from the perspectives of different U.S.~lawmakers. We then identify sets of attention heads whose activations linearly predict those lawmakers' DW-NOMINATE scores, a widely-used and validated measure of political ideology. We find that highly predictive heads are primarily located in the middle layers, often speculated to encode high-level concepts and tasks. Using probes only trained to predict lawmakers' ideology, we then show that the same probes can predict measures of news outlets' slant from the activations of models prompted to simulate text from those news outlets. These linear probes allow us to visualize, interpret, and monitor ideological stances implicitly adopted by an LLM as it generates open-ended responses. Finally, we demonstrate that by applying linear interventions to these attention heads, we can steer the model outputs toward a more liberal or conservative stance. Overall, our research suggests that LLMs possess a high-level linear representation of American political ideology and that by leveraging recent advances in mechanistic interpretability, we can identify, monitor, and steer the subjective perspective underlying generated text.
Activation Scaling for Steering and Interpreting Language Models
Oct 07, 2024



Given the prompt "Rome is in", can we steer a language model to flip its prediction of an incorrect token "France" to a correct token "Italy" by only multiplying a few relevant activation vectors with scalars? We argue that successfully intervening on a model is a prerequisite for interpreting its internal workings. Concretely, we establish a three-term objective: a successful intervention should flip the correct with the wrong token and vice versa (effectiveness), and leave other tokens unaffected (faithfulness), all while being sparse (minimality). Using gradient-based optimization, this objective lets us learn (and later evaluate) a specific kind of efficient and interpretable intervention: activation scaling only modifies the signed magnitude of activation vectors to strengthen, weaken, or reverse the steering directions already encoded in the model. On synthetic tasks, this intervention performs comparably with steering vectors in terms of effectiveness and faithfulness, but is much more minimal allowing us to pinpoint interpretable model components. We evaluate activation scaling from different angles, compare performance on different datasets, and make activation scalars a learnable function of the activation vectors themselves to generalize to varying-length prompts.
Addressing Discretization-Induced Bias in Demographic Prediction
May 27, 2024



Racial and other demographic imputation is necessary for many applications, especially in auditing disparities and outreach targeting in political campaigns. The canonical approach is to construct continuous predictions -- e.g., based on name and geography -- and then to $\textit{discretize}$ the predictions by selecting the most likely class (argmax). We study how this practice produces $\textit{discretization bias}$. In particular, we show that argmax labeling, as used by a prominent commercial voter file vendor to impute race/ethnicity, results in a substantial under-count of African-American voters, e.g., by 28.2% points in North Carolina. This bias can have substantial implications in downstream tasks that use such labels. We then introduce a $\textit{joint optimization}$ approach -- and a tractable $\textit{data-driven thresholding}$ heuristic -- that can eliminate this bias, with negligible individual-level accuracy loss. Finally, we theoretically analyze discretization bias, show that calibrated continuous models are insufficient to eliminate it, and that an approach such as ours is necessary. Broadly, we warn researchers and practitioners against discretizing continuous demographic predictions without considering downstream consequences.
Context versus Prior Knowledge in Language Models
Apr 06, 2024



To answer a question, language models often need to integrate prior knowledge learned during pretraining and new information presented in context. We hypothesize that models perform this integration in a predictable way across different questions and contexts: models will rely more on prior knowledge for questions about entities (e.g., persons, places, etc.) that they are more familiar with due to higher exposure in the training corpus, and be more easily persuaded by some contexts than others. To formalize this problem, we propose two mutual information-based metrics to measure a model's dependency on a context and on its prior about an entity: first, the persuasion score of a given context represents how much a model depends on the context in its decision, and second, the susceptibility score of a given entity represents how much the model can be swayed away from its original answer distribution about an entity. Following well-established measurement modeling methods, we empirically test for the validity and reliability of these metrics. Finally, we explore and find a relationship between the scores and the model's expected familiarity with an entity, and provide two use cases to illustrate their benefits.
The AL$\ell_0$CORE Tensor Decomposition for Sparse Count Data
Mar 12, 2024This paper introduces AL$\ell_0$CORE, a new form of probabilistic non-negative tensor decomposition. AL$\ell_0$CORE is a Tucker decomposition where the number of non-zero elements (i.e., the $\ell_0$-norm) of the core tensor is constrained to a preset value $Q$ much smaller than the size of the core. While the user dictates the total budget $Q$, the locations and values of the non-zero elements are latent variables and allocated across the core tensor during inference. AL$\ell_0$CORE -- i.e., $allo$cated $\ell_0$-$co$nstrained $core$-- thus enjoys both the computational tractability of CP decomposition and the qualitatively appealing latent structure of Tucker. In a suite of real-data experiments, we demonstrate that AL$\ell_0$CORE typically requires only tiny fractions (e.g.,~1%) of the full core to achieve the same results as full Tucker decomposition at only a correspondingly tiny fraction of the cost.
Measurement in the Age of LLMs: An Application to Ideological Scaling
Dec 14, 2023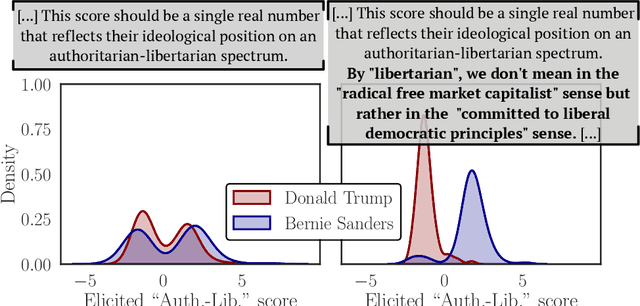

Much of social science is centered around terms like ``ideology'' or ``power'', which generally elude precise definition, and whose contextual meanings are trapped in surrounding language. This paper explores the use of large language models (LLMs) to flexibly navigate the conceptual clutter inherent to social scientific measurement tasks. We rely on LLMs' remarkable linguistic fluency to elicit ideological scales of both legislators and text, which accord closely to established methods and our own judgement. A key aspect of our approach is that we elicit such scores directly, instructing the LLM to furnish numeric scores itself. This approach affords a great deal of flexibility, which we showcase through a variety of different case studies. Our results suggest that LLMs can be used to characterize highly subtle and diffuse manifestations of political ideology in text.
The Ordered Matrix Dirichlet for Modeling Ordinal Dynamics
Dec 08, 2022



Many dynamical systems exhibit latent states with intrinsic orderings such as "ally", "neutral" and "enemy" relationships in international relations. Such latent states are evidenced through entities' cooperative versus conflictual interactions which are similarly ordered. Models of such systems often involve state-to-action emission and state-to-state transition matrices. It is common practice to assume that the rows of these stochastic matrices are independently sampled from a Dirichlet distribution. However, this assumption discards ordinal information and treats states and actions falsely as order-invariant categoricals, which hinders interpretation and evaluation. To address this problem, we propose the Ordered Matrix Dirichlet (OMD): rows are sampled conditionally dependent such that probability mass is shifted to the right of the matrix as we move down rows. This results in a well-ordered mapping between latent states and observed action types. We evaluate the OMD in two settings: a Hidden Markov Model and a novel Bayesian Dynamic Poisson Tucker Model tailored to political event data. Models built on the OMD recover interpretable latent states and show superior forecasting performance in few-shot settings. We detail the wide applicability of the OMD to other domains where models with Dirichlet-sampled matrices are popular (e.g. topic modeling) and publish user-friendly code.
An Ordinal Latent Variable Model of Conflict Intensity
Oct 08, 2022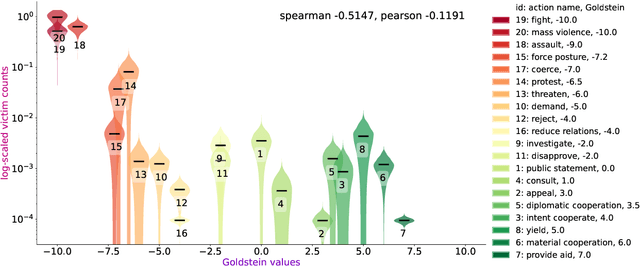
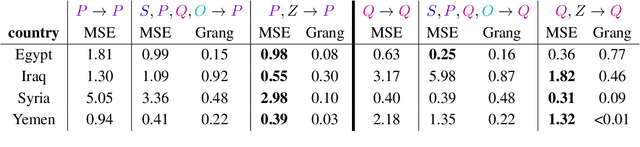
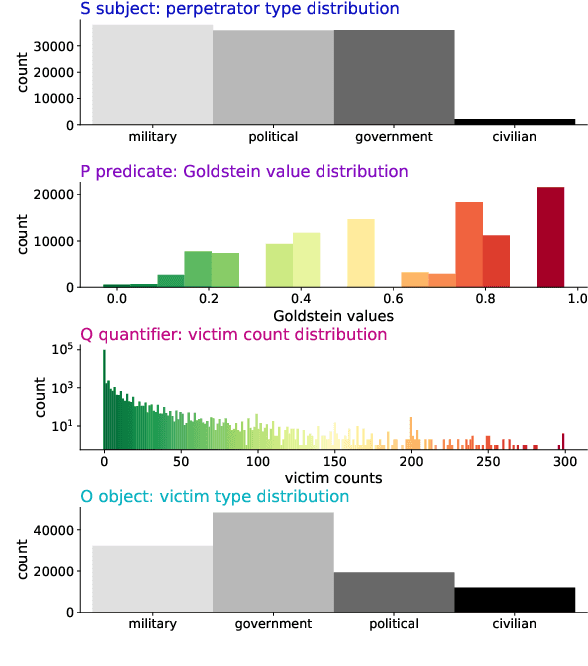

For the quantitative monitoring of international relations, political events are extracted from the news and parsed into "who-did-what-to-whom" patterns. This has resulted in large data collections which require aggregate statistics for analysis. The Goldstein Scale is an expert-based measure that ranks individual events on a one-dimensional scale from conflictual to cooperative. However, the scale disregards fatality counts as well as perpetrator and victim types involved in an event. This information is typically considered in qualitative conflict assessment. To address this limitation, we propose a probabilistic generative model over the full subject-predicate-quantifier-object tuples associated with an event. We treat conflict intensity as an interpretable, ordinal latent variable that correlates conflictual event types with high fatality counts. Taking a Bayesian approach, we learn a conflict intensity scale from data and find the optimal number of intensity classes. We evaluate the model by imputing missing data. Our scale proves to be more informative than the original Goldstein Scale in autoregressive forecasting and when compared with global online attention towards armed conflicts.