 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Ordered Matrix Dirichlet for Modeling Ordinal Dynamics
Dec 08, 2022



Many dynamical systems exhibit latent states with intrinsic orderings such as "ally", "neutral" and "enemy" relationships in international relations. Such latent states are evidenced through entities' cooperative versus conflictual interactions which are similarly ordered. Models of such systems often involve state-to-action emission and state-to-state transition matrices. It is common practice to assume that the rows of these stochastic matrices are independently sampled from a Dirichlet distribution. However, this assumption discards ordinal information and treats states and actions falsely as order-invariant categoricals, which hinders interpretation and evaluation. To address this problem, we propose the Ordered Matrix Dirichlet (OMD): rows are sampled conditionally dependent such that probability mass is shifted to the right of the matrix as we move down rows. This results in a well-ordered mapping between latent states and observed action types. We evaluate the OMD in two settings: a Hidden Markov Model and a novel Bayesian Dynamic Poisson Tucker Model tailored to political event data. Models built on the OMD recover interpretable latent states and show superior forecasting performance in few-shot settings. We detail the wide applicability of the OMD to other domains where models with Dirichlet-sampled matrices are popular (e.g. topic modeling) and publish user-friendly code.
Regressing Location on Text for Probabilistic Geocoding
Jun 30, 2021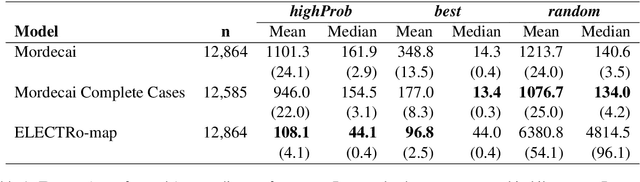
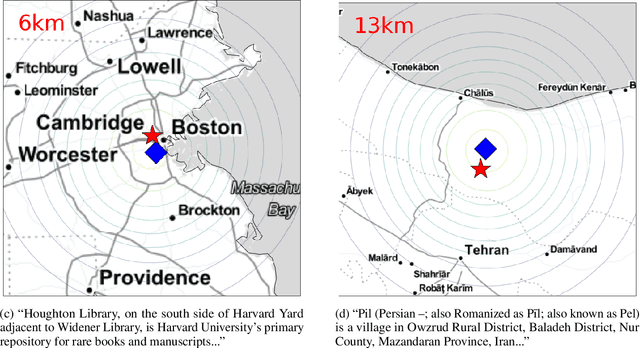
Text data are an important source of detailed information about social and political events. Automated systems parse large volumes of text data to infer or extract structured information that describes actors, actions, dates, times, and locations. One of these sub-tasks is geocoding: predicting the geographic coordinates associated with events or locations described by a given text. We present an end-to-end probabilistic model for geocoding text data. Additionally, we collect a novel data set for evaluating the performance of geocoding systems. We compare the model-based solution, called ELECTRo-map, to the current state-of-the-art open source system for geocoding texts for event data. Finally, we discuss the benefits of end-to-end model-based geocoding, including principled uncertainty estimation and the ability of these models to leverage contextual information.
Few-Shot Upsampling for Protest Size Detection
May 24, 2021

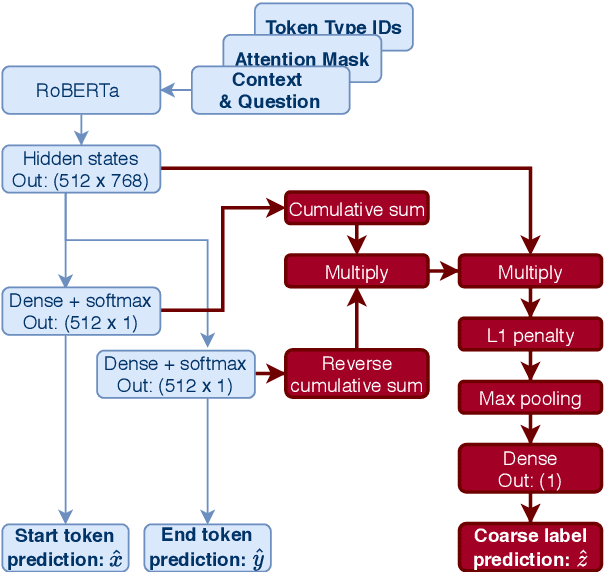

We propose a new task and dataset for a common problem in social science research: "upsampling" coarse document labels to fine-grained labels or spans. We pose the problem in a question answering format, with the answers providing the fine-grained labels. We provide a benchmark dataset and baselines on a socially impactful task: identifying the exact crowd size at protests and demonstrations in the United States given only order-of-magnitude information about protest attendance, a very small sample of fine-grained examples, and English-language news text. We evaluate several baseline models, including zero-shot results from rule-based and question-answering models, few-shot models fine-tuned on a small set of documents, and weakly supervised models using a larger set of coarsely-labeled documents. We find that our rule-based model initially outperforms a zero-shot pre-trained transformer language model but that further fine-tuning on a very small subset of 25 examples substantially improves out-of-sample performance. We also demonstrate a method for fine-tuning the transformer span on only the coarse labels that performs similarly to our rule-based approach. This work will contribute to social scientists' ability to generate data to understand the causes and successes of collective action.
Seeing the Forest and the Trees: Detection and Cross-Document Coreference Resolution of Militarized Interstate Disputes
May 06, 2020
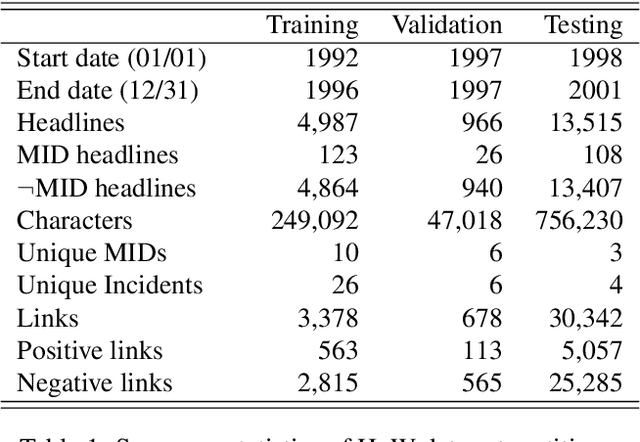
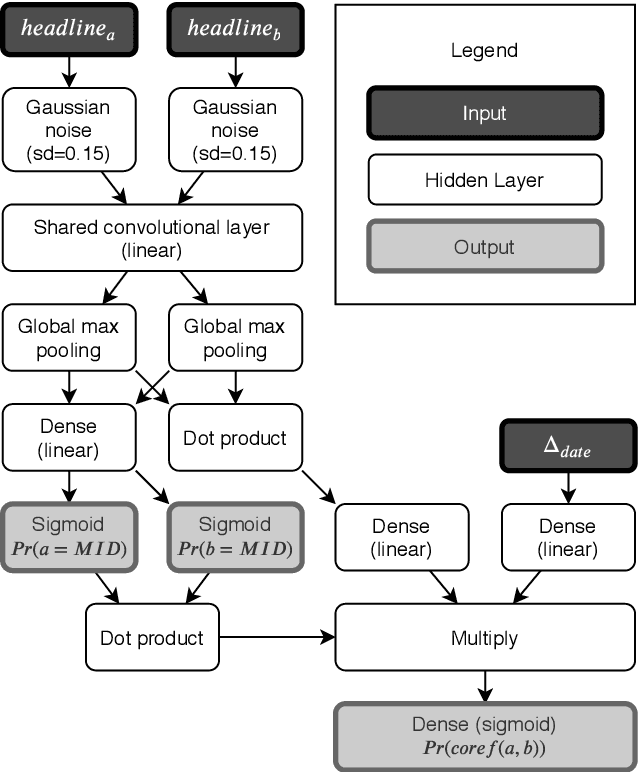
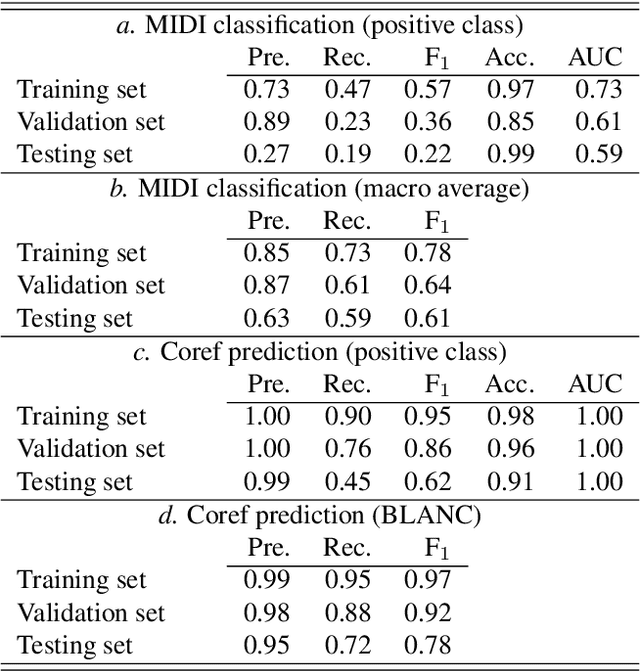
Previous efforts to automate the detection of social and political events in text have primarily focused on identifying events described within single sentences or documents. Within a corpus of documents, these automated systems are unable to link event references -- recognize singular events across multiple sentences or documents. A separate literature in computational linguistics on event coreference resolution attempts to link known events to one another within (and across) documents. I provide a data set for evaluating methods to identify certain political events in text and to link related texts to one another based on shared events. The data set, Headlines of War, is built on the Militarized Interstate Disputes data set and offers headlines classified by dispute status and headline pairs labeled with coreference indicators. Additionally, I introduce a model capable of accomplishing both tasks. The multi-task convolutional neural network is shown to be capable of recognizing events and event coreferences given the headlines' texts and publication dates.
Multitask Models for Supervised Protests Detection in Texts
May 06, 2020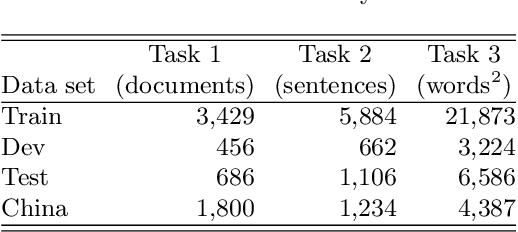
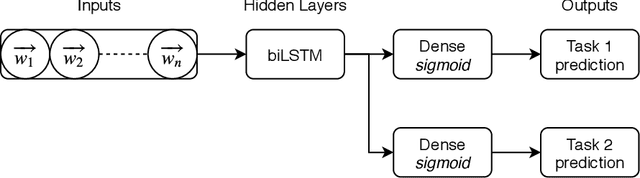
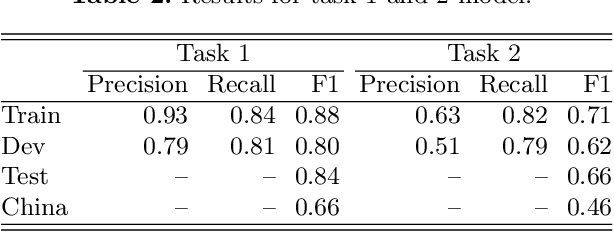
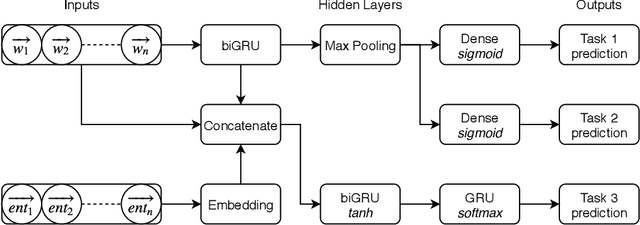
The CLEF 2019 ProtestNews Lab tasks participants to identify text relating to political protests within larger corpora of news data. Three tasks include article classification, sentence detection, and event extraction. I apply multitask neural networks capable of producing predictions for two and three of these tasks simultaneously. The multitask framework allows the model to learn relevant features from the training data of all three tasks. This paper demonstrates performance near or above the reported state-of-the-art for automated political event coding though noted differences in research design make direct comparisons difficult.
Sequence Aggregation Rules for Anomaly Detection in Computer Network Traffic
May 14, 2018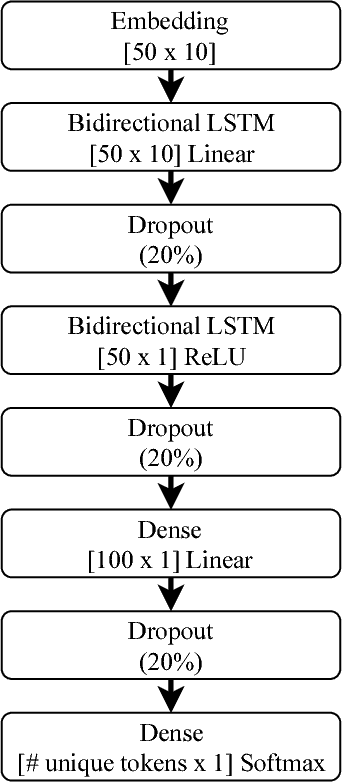
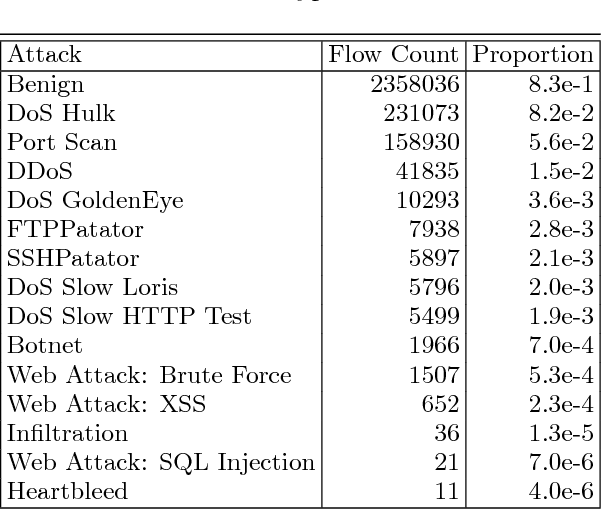
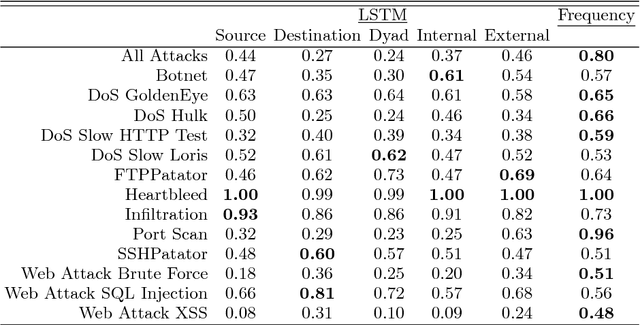
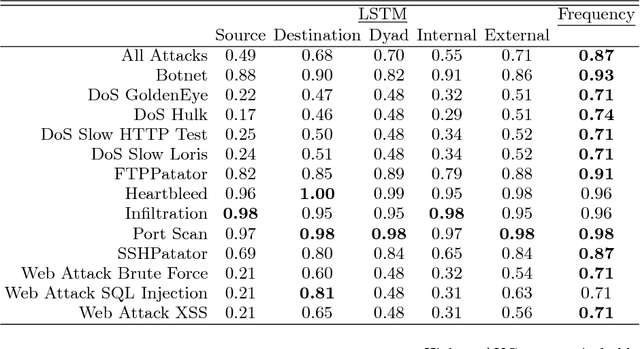
We evaluate methods for applying unsupervised anomaly detection to cybersecurity applications on computer network traffic data, or flow. We borrow from the natural language processing literature and conceptualize flow as a sort of "language" spoken between machines. Five sequence aggregation rules are evaluated for their efficacy in flagging multiple attack types in a labeled flow dataset, CICIDS2017. For sequence modeling, we rely on long short-term memory (LSTM) recurrent neural networks (RNN). Additionally, a simple frequency-based model is described and its performance with respect to attack detection is compared to the LSTM models. We conclude that the frequency-based model tends to perform as well as or better than the LSTM models for the tasks at hand, with a few notable exceptions.
Network Traffic Anomaly Detection Using Recurrent Neural Networks
Mar 28, 2018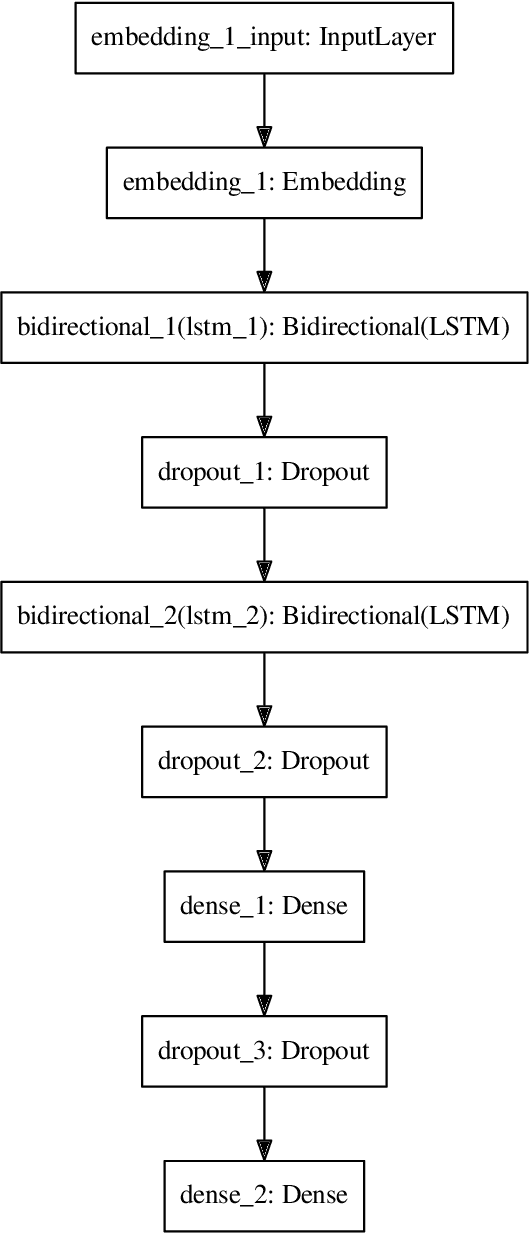
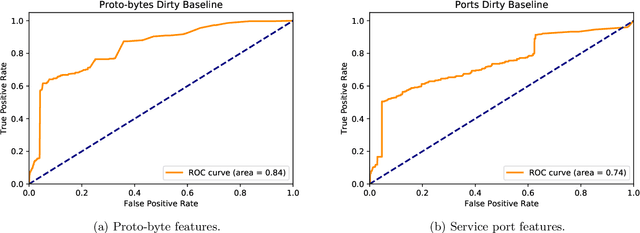
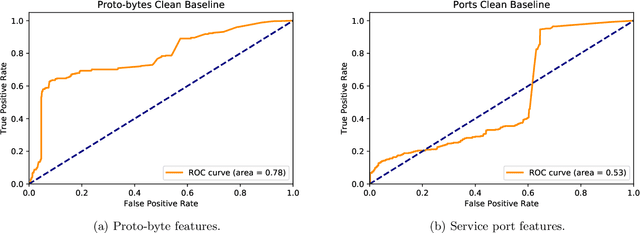
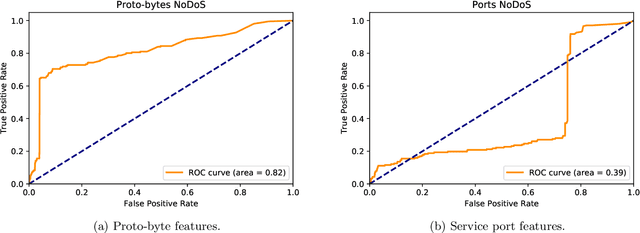
We show that a recurrent neural network is able to learn a model to represent sequences of communications between computers on a network and can be used to identify outlier network traffic. Defending computer networks is a challenging problem and is typically addressed by manually identifying known malicious actor behavior and then specifying rules to recognize such behavior in network communications. However, these rule-based approaches often generalize poorly and identify only those patterns that are already known to researchers. An alternative approach that does not rely on known malicious behavior patterns can potentially also detect previously unseen patterns. We tokenize and compress netflow into sequences of "words" that form "sentences" representative of a conversation between computers. These sentences are then used to generate a model that learns the semantic and syntactic grammar of the newly generated language. We use Long-Short-Term Memory (LSTM) cell Recurrent Neural Networks (RNN) to capture the complex relationships and nuances of this language. The language model is then used predict the communications between two IPs and the prediction error is used as a measurement of how typical or atyptical the observed communication are. By learning a model that is specific to each network, yet generalized to typical computer-to-computer traffic within and outside the network, a language model is able to identify sequences of network activity that are outliers with respect to the model. We demonstrate positive unsupervised attack identification performance (AUC 0.84) on the ISCX IDS dataset which contains seven days of network activity with normal traffic and four distinct attack patterns.