 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodebook LLMs: Adapting Political Science Codebooks for LLM Use and Adapting LLMs to Follow Codebooks
Jul 15, 2024


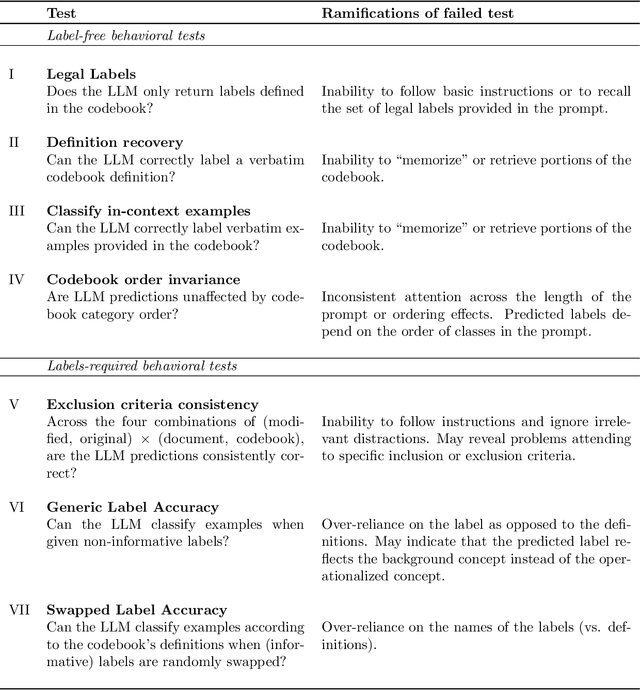
Codebooks -- documents that operationalize constructs and outline annotation procedures -- are used almost universally by social scientists when coding unstructured political texts. Recently, to reduce manual annotation costs, political scientists have looked to generative large language models (LLMs) to label and analyze text data. However, previous work using LLMs for classification has implicitly relied on the universal label assumption -- correct classification of documents is possible using only a class label or minimal definition and the information that the LLM inductively learns during its pre-training. In contrast, we argue that political scientists who care about valid measurement should instead make a codebook-construct label assumption -- an LLM should follow the definition and exclusion criteria of a construct/label provided in a codebook. In this work, we collect and curate three political science datasets and their original codebooks and conduct a set of experiments to understand whether LLMs comply with codebook instructions, whether rewriting codebooks improves performance, and whether instruction-tuning LLMs on codebook-document-label tuples improves performance over zero-shot classification. Using Mistral 7B Instruct as our LLM, we find re-structuring the original codebooks gives modest gains in zero-shot performance but the model still struggles to comply with the constraints of the codebooks. Optimistically, instruction-tuning Mistral on one of our datasets gives significant gains over zero-shot inference (0.76 versus 0.53 micro F1). We hope our conceptualization of the codebook-specific task, assumptions, and instruction-tuning pipeline as well our semi-structured LLM codebook format will help political scientists readily adapt to the LLM era.
Creating Custom Event Data Without Dictionaries: A Bag-of-Tricks
Apr 03, 2023Event data, or structured records of ``who did what to whom'' that are automatically extracted from text, is an important source of data for scholars of international politics. The high cost of developing new event datasets, especially using automated systems that rely on hand-built dictionaries, means that most researchers draw on large, pre-existing datasets such as ICEWS rather than developing tailor-made event datasets optimized for their specific research question. This paper describes a ``bag of tricks'' for efficient, custom event data production, drawing on recent advances in natural language processing (NLP) that allow researchers to rapidly produce customized event datasets. The paper introduces techniques for training an event category classifier with active learning, identifying actors and the recipients of actions in text using large language models and standard machine learning classifiers and pretrained ``question-answering'' models from NLP, and resolving mentions of actors to their Wikipedia article to categorize them. We describe how these techniques produced the new POLECAT global event dataset that is intended to replace ICEWS, along with examples of how scholars can quickly produce smaller, custom event datasets. We publish example code and models to implement our new techniques.
Synthetically generated text for supervised text analysis
Mar 28, 2023Supervised text models are a valuable tool for political scientists but present several obstacles to their use, including the expense of hand-labeling documents, the difficulty of retrieving rare relevant documents for annotation, and copyright and privacy concerns involved in sharing annotated documents. This article proposes a partial solution to these three issues, in the form of controlled generation of synthetic text with large language models. I provide a conceptual overview of text generation, guidance on when researchers should prefer different techniques for generating synthetic text, a discussion of ethics, and a simple technique for improving the quality of synthetic text. I demonstrate the usefulness of synthetic text with three applications: generating synthetic tweets describing the fighting in Ukraine, synthetic news articles describing specified political events for training an event detection system, and a multilingual corpus of populist manifesto statements for training a sentence-level populism classifier.
Mordecai 3: A Neural Geoparser and Event Geocoder
Mar 23, 2023Mordecai3 is a new end-to-end text geoparser and event geolocation system. The system performs toponym resolution using a new neural ranking model to resolve a place name extracted from a document to its entry in the Geonames gazetteer. It also performs event geocoding, the process of linking events reported in text with the place names where they are reported to occur, using an off-the-shelf question-answering model. The toponym resolution model is trained on a diverse set of existing training data, along with several thousand newly annotated examples. The paper describes the model, its training process, and performance comparisons with existing geoparsers. The system is available as an open source Python library, Mordecai 3, and replaces an earlier geoparser, Mordecai v2, one of the most widely used text geoparsers (Halterman 2017).
Corpus-Level Evaluation for Event QA: The IndiaPoliceEvents Corpus Covering the 2002 Gujarat Violence
May 27, 2021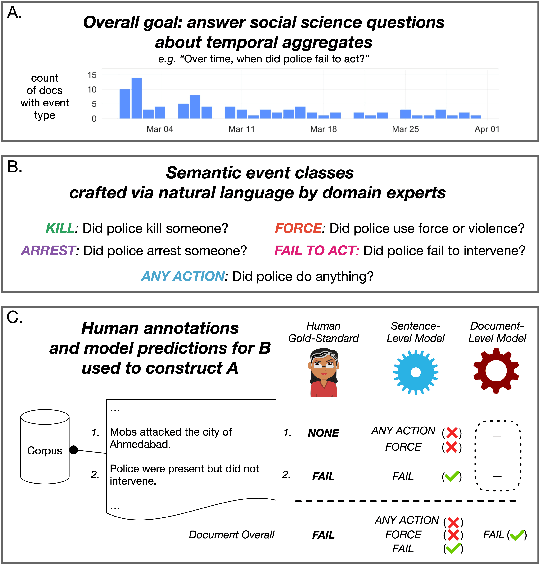
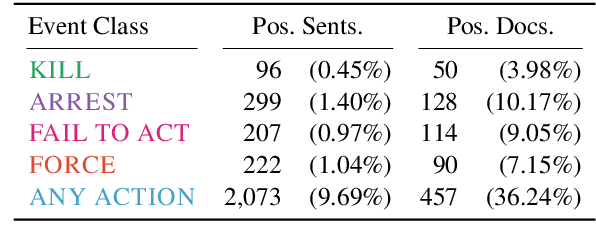

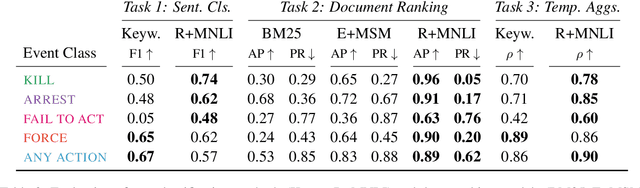
Automated event extraction in social science applications often requires corpus-level evaluations: for example, aggregating text predictions across metadata and unbiased estimates of recall. We combine corpus-level evaluation requirements with a real-world, social science setting and introduce the IndiaPoliceEvents corpus--all 21,391 sentences from 1,257 English-language Times of India articles about events in the state of Gujarat during March 2002. Our trained annotators read and label every document for mentions of police activity events, allowing for unbiased recall evaluations. In contrast to other datasets with structured event representations, we gather annotations by posing natural questions, and evaluate off-the-shelf models for three different tasks: sentence classification, document ranking, and temporal aggregation of target events. We present baseline results from zero-shot BERT-based models fine-tuned on natural language inference and passage retrieval tasks. Our novel corpus-level evaluations and annotation approach can guide creation of similar social-science-oriented resources in the future.
* To appear in Findings of ACL 2021
Few-Shot Upsampling for Protest Size Detection
May 24, 2021

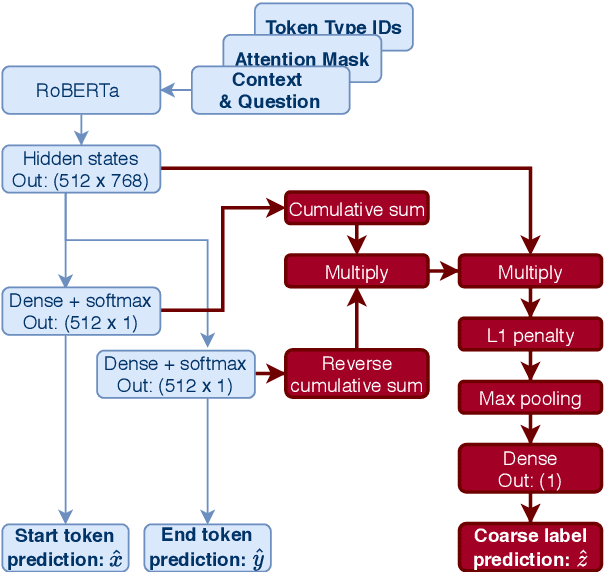

We propose a new task and dataset for a common problem in social science research: "upsampling" coarse document labels to fine-grained labels or spans. We pose the problem in a question answering format, with the answers providing the fine-grained labels. We provide a benchmark dataset and baselines on a socially impactful task: identifying the exact crowd size at protests and demonstrations in the United States given only order-of-magnitude information about protest attendance, a very small sample of fine-grained examples, and English-language news text. We evaluate several baseline models, including zero-shot results from rule-based and question-answering models, few-shot models fine-tuned on a small set of documents, and weakly supervised models using a larger set of coarsely-labeled documents. We find that our rule-based model initially outperforms a zero-shot pre-trained transformer language model but that further fine-tuning on a very small subset of 25 examples substantially improves out-of-sample performance. We also demonstrate a method for fine-tuning the transformer span on only the coarse labels that performs similarly to our rule-based approach. This work will contribute to social scientists' ability to generate data to understand the causes and successes of collective action.
Geolocating Political Events in Text
May 29, 2019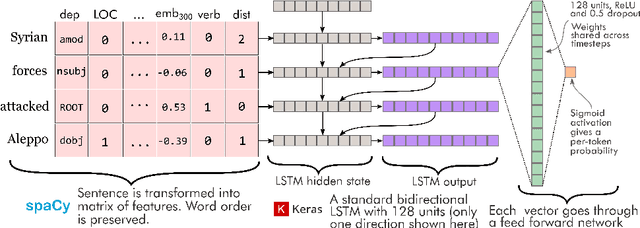
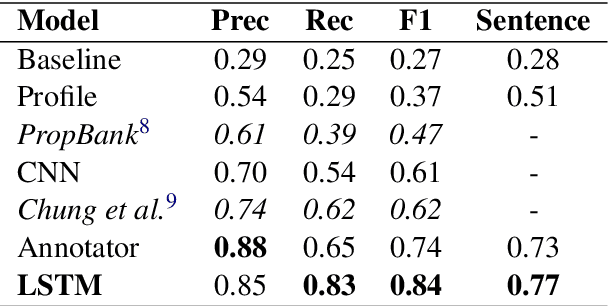

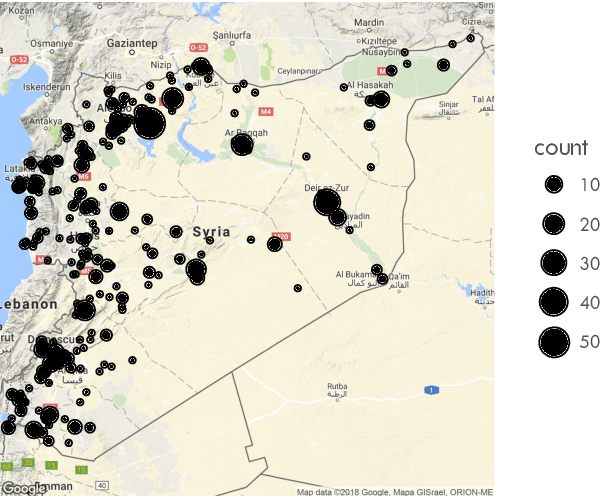
This work introduces a general method for automatically finding the locations where political events in text occurred. Using a novel set of 8,000 labeled sentences, I create a method to link automatically extracted events and locations in text. The model achieves human level performance on the annotation task and outperforms previous event geolocation systems. It can be applied to most event extraction systems across geographic contexts. I formalize the event--location linking task, describe the neural network model, describe the potential uses of such a system in political science, and demonstrate a workflow to answer an open question on the role of conventional military offensives in causing civilian casualties in the Syrian civil war.