 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Upsampling for Protest Size Detection
Paper and Code


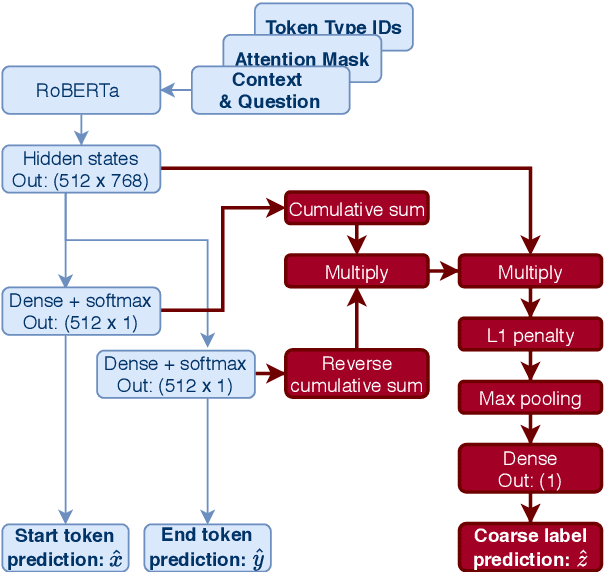

We propose a new task and dataset for a common problem in social science research: "upsampling" coarse document labels to fine-grained labels or spans. We pose the problem in a question answering format, with the answers providing the fine-grained labels. We provide a benchmark dataset and baselines on a socially impactful task: identifying the exact crowd size at protests and demonstrations in the United States given only order-of-magnitude information about protest attendance, a very small sample of fine-grained examples, and English-language news text. We evaluate several baseline models, including zero-shot results from rule-based and question-answering models, few-shot models fine-tuned on a small set of documents, and weakly supervised models using a larger set of coarsely-labeled documents. We find that our rule-based model initially outperforms a zero-shot pre-trained transformer language model but that further fine-tuning on a very small subset of 25 examples substantially improves out-of-sample performance. We also demonstrate a method for fine-tuning the transformer span on only the coarse labels that performs similarly to our rule-based approach. This work will contribute to social scientists' ability to generate data to understand the causes and successes of collective action.