 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodebook LLMs: Adapting Political Science Codebooks for LLM Use and Adapting LLMs to Follow Codebooks
Paper and Code



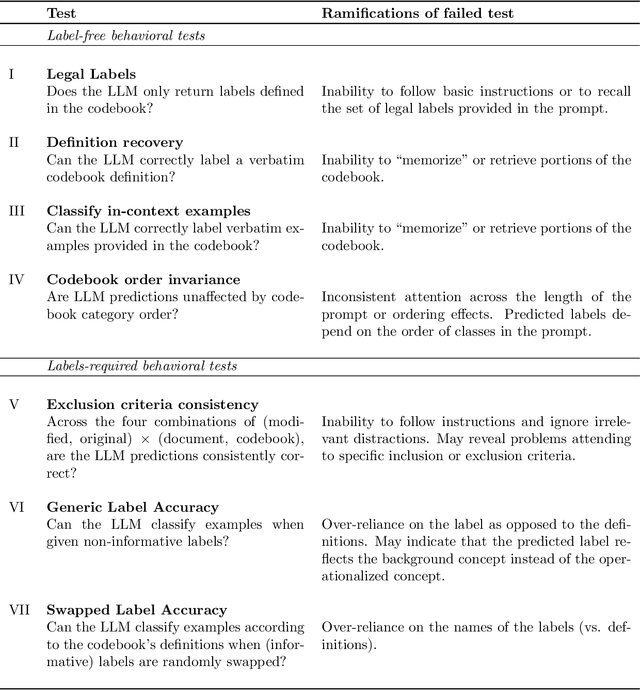
Codebooks -- documents that operationalize constructs and outline annotation procedures -- are used almost universally by social scientists when coding unstructured political texts. Recently, to reduce manual annotation costs, political scientists have looked to generative large language models (LLMs) to label and analyze text data. However, previous work using LLMs for classification has implicitly relied on the universal label assumption -- correct classification of documents is possible using only a class label or minimal definition and the information that the LLM inductively learns during its pre-training. In contrast, we argue that political scientists who care about valid measurement should instead make a codebook-construct label assumption -- an LLM should follow the definition and exclusion criteria of a construct/label provided in a codebook. In this work, we collect and curate three political science datasets and their original codebooks and conduct a set of experiments to understand whether LLMs comply with codebook instructions, whether rewriting codebooks improves performance, and whether instruction-tuning LLMs on codebook-document-label tuples improves performance over zero-shot classification. Using Mistral 7B Instruct as our LLM, we find re-structuring the original codebooks gives modest gains in zero-shot performance but the model still struggles to comply with the constraints of the codebooks. Optimistically, instruction-tuning Mistral on one of our datasets gives significant gains over zero-shot inference (0.76 versus 0.53 micro F1). We hope our conceptualization of the codebook-specific task, assumptions, and instruction-tuning pipeline as well our semi-structured LLM codebook format will help political scientists readily adapt to the LLM era.