 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasurement in the Age of LLMs: An Application to Ideological Scaling
Paper and Code
Dec 14, 2023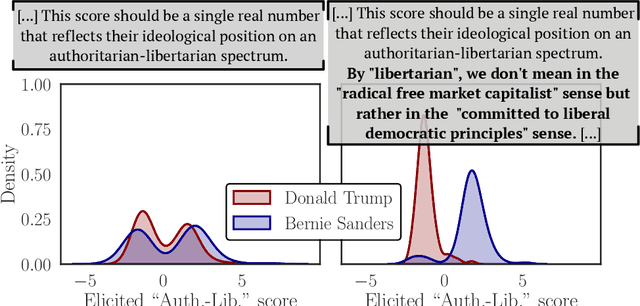

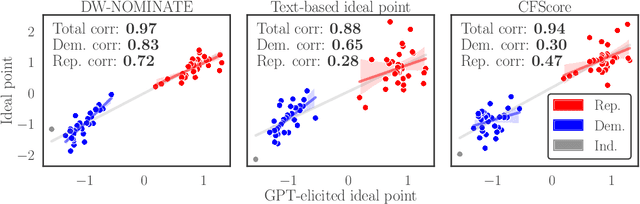
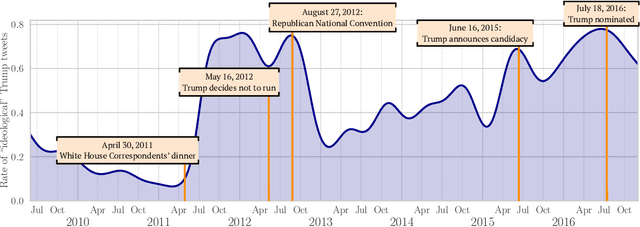
Much of social science is centered around terms like ``ideology'' or ``power'', which generally elude precise definition, and whose contextual meanings are trapped in surrounding language. This paper explores the use of large language models (LLMs) to flexibly navigate the conceptual clutter inherent to social scientific measurement tasks. We rely on LLMs' remarkable linguistic fluency to elicit ideological scales of both legislators and text, which accord closely to established methods and our own judgement. A key aspect of our approach is that we elicit such scores directly, instructing the LLM to furnish numeric scores itself. This approach affords a great deal of flexibility, which we showcase through a variety of different case studies. Our results suggest that LLMs can be used to characterize highly subtle and diffuse manifestations of political ideology in text.