 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSchrödinger's Bat: Diffusion Models Sometimes Generate Polysemous Words in Superposition
Paper and Code

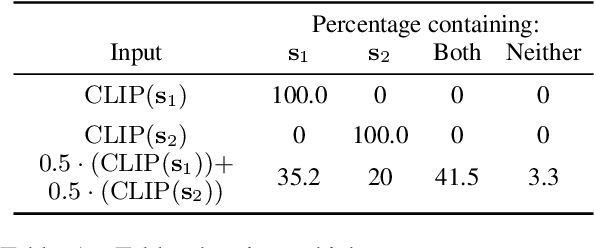

Recent work has shown that despite their impressive capabilities, text-to-image diffusion models such as DALL-E 2 (Ramesh et al., 2022) can display strange behaviours when a prompt contains a word with multiple possible meanings, often generating images containing both senses of the word (Rassin et al., 2022). In this work we seek to put forward a possible explanation of this phenomenon. Using the similar Stable Diffusion model (Rombach et al., 2022), we first show that when given an input that is the sum of encodings of two distinct words, the model can produce an image containing both concepts represented in the sum. We then demonstrate that the CLIP encoder used to encode prompts (Radford et al., 2021) encodes polysemous words as a superposition of meanings, and that using linear algebraic techniques we can edit these representations to influence the senses represented in the generated images. Combining these two findings, we suggest that the homonym duplication phenomenon described by Rassin et al. (2022) is caused by diffusion models producing images representing both of the meanings that are present in superposition in the encoding of a polysemous word.