 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining the Inductive Bias of Neural Language Models with Artificial Languages
Paper and Code
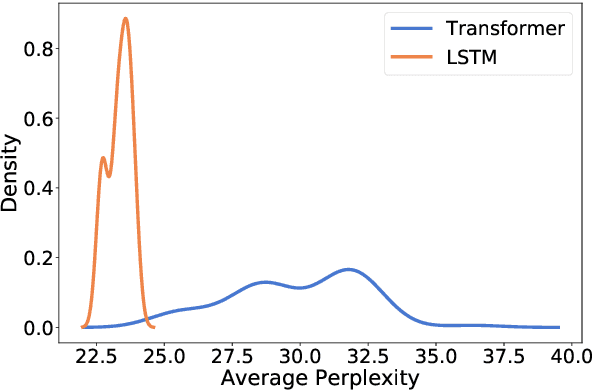


Since language models are used to model a wide variety of languages, it is natural to ask whether the neural architectures used for the task have inductive biases towards modeling particular types of languages. Investigation of these biases has proved complicated due to the many variables that appear in the experimental setup. Languages vary in many typological dimensions, and it is difficult to single out one or two to investigate without the others acting as confounders. We propose a novel method for investigating the inductive biases of language models using artificial languages. These languages are constructed to allow us to create parallel corpora across languages that differ only in the typological feature being investigated, such as word order. We then use them to train and test language models. This constitutes a fully controlled causal framework, and demonstrates how grammar engineering can serve as a useful tool for analyzing neural models. Using this method, we find that commonly used neural architectures exhibit different inductive biases: LSTMs display little preference with respect to word ordering, while transformers display a clear preference for some orderings over others. Further, we find that neither the inductive bias of the LSTM nor that of the transformer appears to reflect any tendencies that we see in attested natural languages.