 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Patch n' Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution
Jul 12, 2023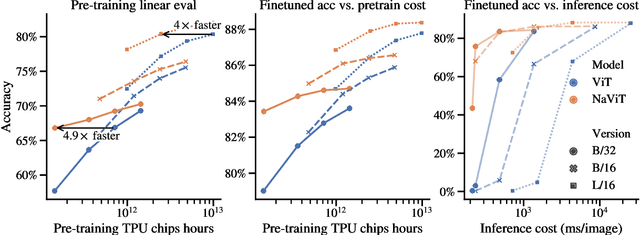
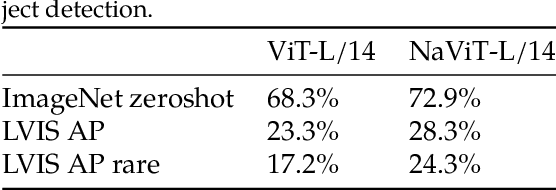
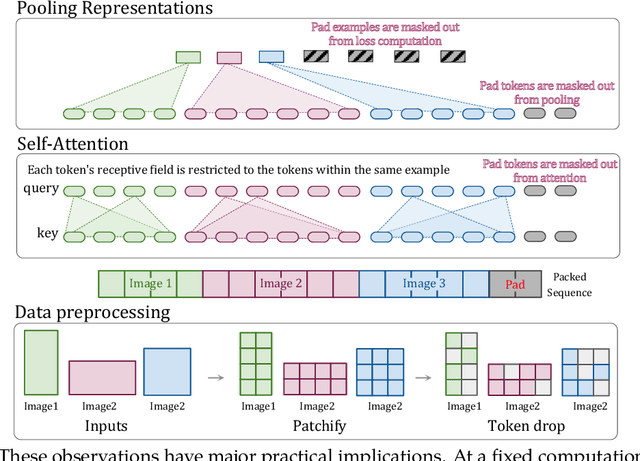
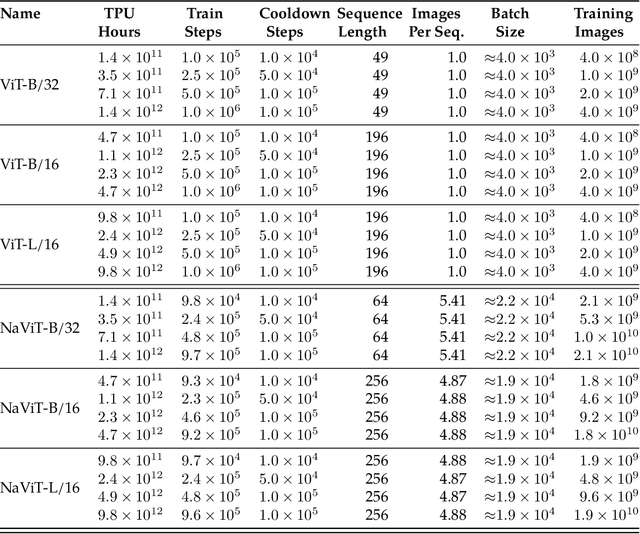
The ubiquitous and demonstrably suboptimal choice of resizing images to a fixed resolution before processing them with computer vision models has not yet been successfully challenged. However, models such as the Vision Transformer (ViT) offer flexible sequence-based modeling, and hence varying input sequence lengths. We take advantage of this with NaViT (Native Resolution ViT) which uses sequence packing during training to process inputs of arbitrary resolutions and aspect ratios. Alongside flexible model usage, we demonstrate improved training efficiency for large-scale supervised and contrastive image-text pretraining. NaViT can be efficiently transferred to standard tasks such as image and video classification, object detection, and semantic segmentation and leads to improved results on robustness and fairness benchmarks. At inference time, the input resolution flexibility can be used to smoothly navigate the test-time cost-performance trade-off. We believe that NaViT marks a departure from the standard, CNN-designed, input and modelling pipeline used by most computer vision models, and represents a promising direction for ViTs.
Scaling Vision Transformers to 22 Billion Parameters
Feb 10, 2023



The scaling of Transformers has driven breakthrough capabilities for language models. At present, the largest large language models (LLMs) contain upwards of 100B parameters. Vision Transformers (ViT) have introduced the same architecture to image and video modelling, but these have not yet been successfully scaled to nearly the same degree; the largest dense ViT contains 4B parameters (Chen et al., 2022). We present a recipe for highly efficient and stable training of a 22B-parameter ViT (ViT-22B) and perform a wide variety of experiments on the resulting model. When evaluated on downstream tasks (often with a lightweight linear model on frozen features), ViT-22B demonstrates increasing performance with scale. We further observe other interesting benefits of scale, including an improved tradeoff between fairness and performance, state-of-the-art alignment to human visual perception in terms of shape/texture bias, and improved robustness. ViT-22B demonstrates the potential for "LLM-like" scaling in vision, and provides key steps towards getting there.
Milking CowMask for Semi-Supervised Image Classification
Apr 03, 2020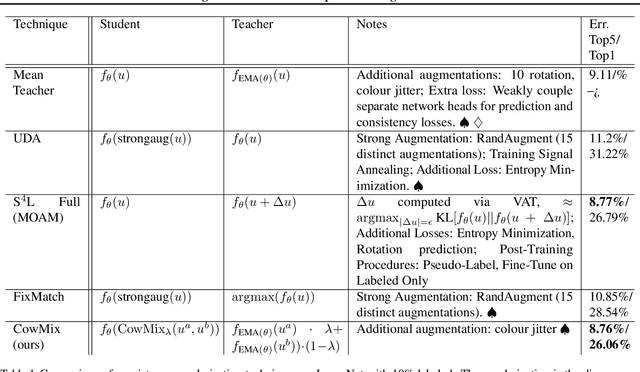

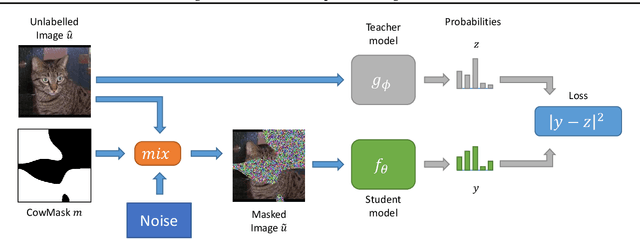
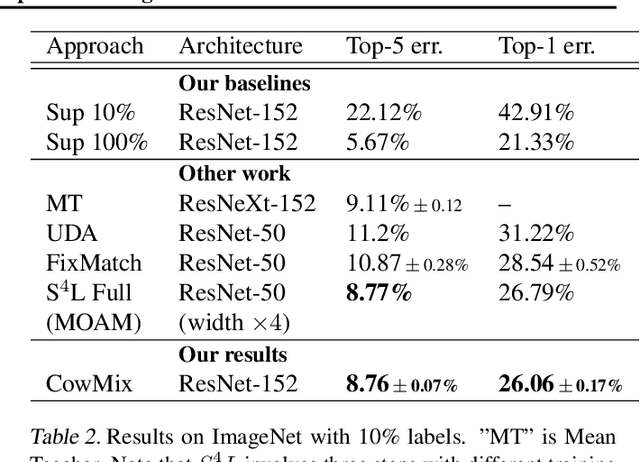
Consistency regularization is a technique for semi-supervised learning that has recently been shown to yield strong results for classification with few labeled data. The method works by perturbing input data using augmentation or adversarial examples, and encouraging the learned model to be robust to these perturbations on unlabeled data. Here, we evaluate the use of a recently proposed augmentation method, called CowMasK, for this purpose. Using CowMask as the augmentation method in semi-supervised consistency regularization, we establish a new state-of-the-art result on Imagenet with 10% labeled data, with a top-5 error of 8.76% and top-1 error of 26.06%. Moreover, we do so with a method that is much simpler than alternative methods. We further investigate the behavior of CowMask for semi-supervised learning by running many smaller scale experiments on the small image benchmarks SVHN, CIFAR-10 and CIFAR-100, where we achieve results competitive with the state of the art, and where we find evidence that the CowMask perturbation is widely applicable. We open source our code at https://github.com/google-research/google-research/tree/master/milking_cowmask
MetNet: A Neural Weather Model for Precipitation Forecasting
Mar 30, 2020Weather forecasting is a long standing scientific challenge with direct social and economic impact. The task is suitable for deep neural networks due to vast amounts of continuously collected data and a rich spatial and temporal structure that presents long range dependencies. We introduce MetNet, a neural network that forecasts precipitation up to 8 hours into the future at the high spatial resolution of 1 km$^2$ and at the temporal resolution of 2 minutes with a latency in the order of seconds. MetNet takes as input radar and satellite data and forecast lead time and produces a probabilistic precipitation map. The architecture uses axial self-attention to aggregate the global context from a large input patch corresponding to a million square kilometers. We evaluate the performance of MetNet at various precipitation thresholds and find that MetNet outperforms Numerical Weather Prediction at forecasts of up to 7 to 8 hours on the scale of the continental United States.
S$^\mathbf{4}$L: Self-Supervised Semi-Supervised Learning
May 09, 2019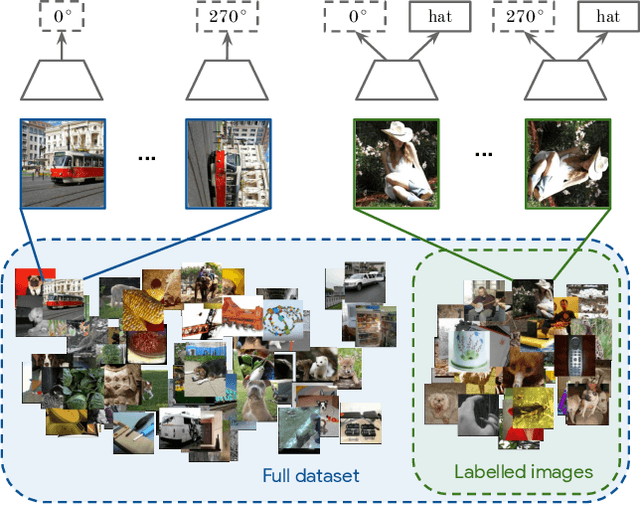
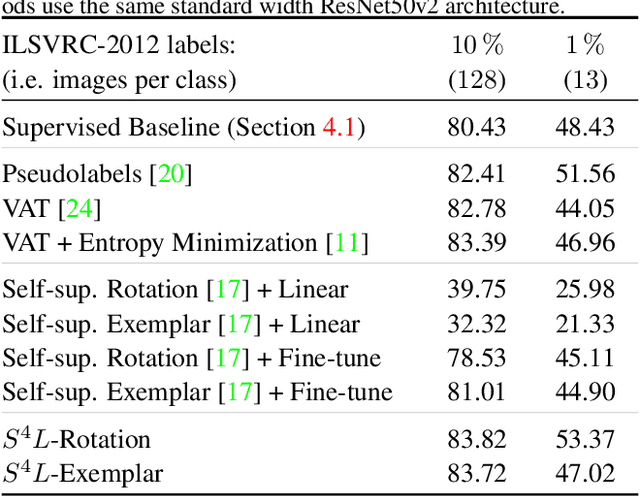
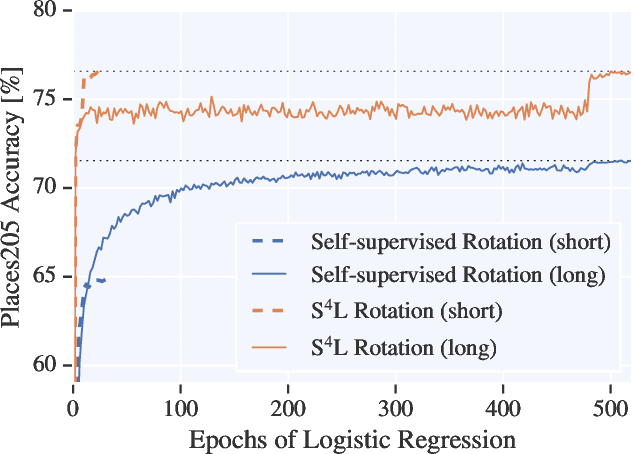
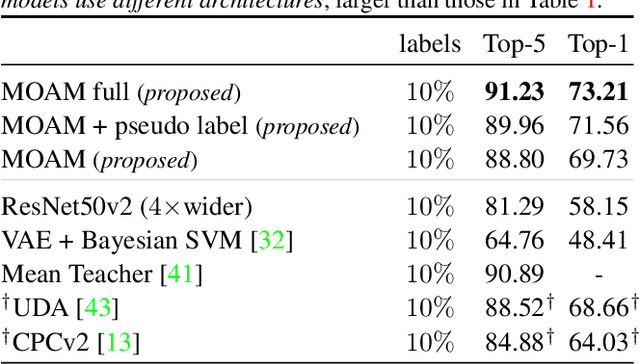
This work tackles the problem of semi-supervised learning of image classifiers. Our main insight is that the field of semi-supervised learning can benefit from the quickly advancing field of self-supervised visual representation learning. Unifying these two approaches, we propose the framework of self-supervised semi-supervised learning ($S^4L$) and use it to derive two novel semi-supervised image classification methods. We demonstrate the effectiveness of these methods in comparison to both carefully tuned baselines, and existing semi-supervised learning methods. We then show that $S^4L$ and existing semi-supervised methods can be jointly trained, yielding a new state-of-the-art result on semi-supervised ILSVRC-2012 with 10% of labels.
MixMatch: A Holistic Approach to Semi-Supervised Learning
May 06, 2019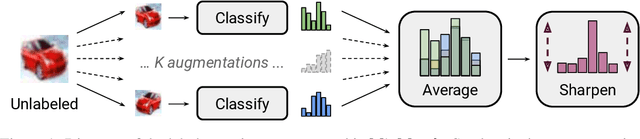

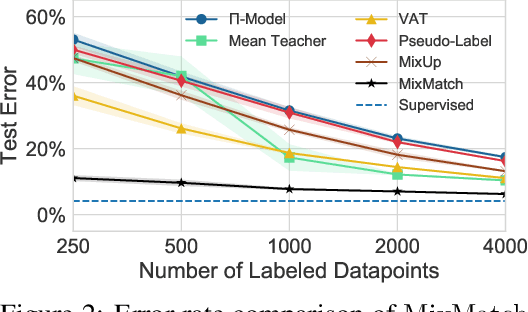

Semi-supervised learning has proven to be a powerful paradigm for leveraging unlabeled data to mitigate the reliance on large labeled datasets. In this work, we unify the current dominant approaches for semi-supervised learning to produce a new algorithm, MixMatch, that works by guessing low-entropy labels for data-augmented unlabeled examples and mixing labeled and unlabeled data using MixUp. We show that MixMatch obtains state-of-the-art results by a large margin across many datasets and labeled data amounts. For example, on CIFAR-10 with 250 labels, we reduce error rate by a factor of 4 (from 38% to 11%) and by a factor of 2 on STL-10. We also demonstrate how MixMatch can help achieve a dramatically better accuracy-privacy trade-off for differential privacy. Finally, we perform an ablation study to tease apart which components of MixMatch are most important for its success.
When Semi-Supervised Learning Meets Transfer Learning: Training Strategies, Models and Datasets
Dec 13, 2018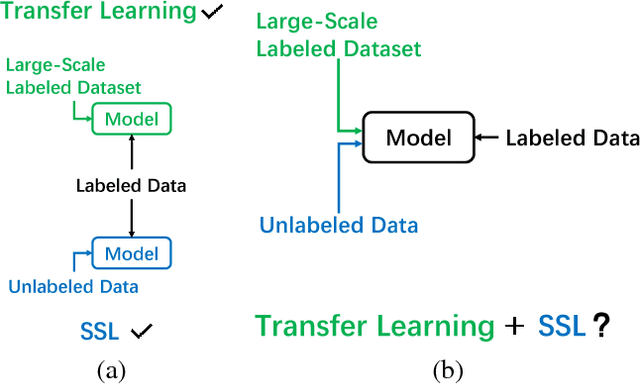
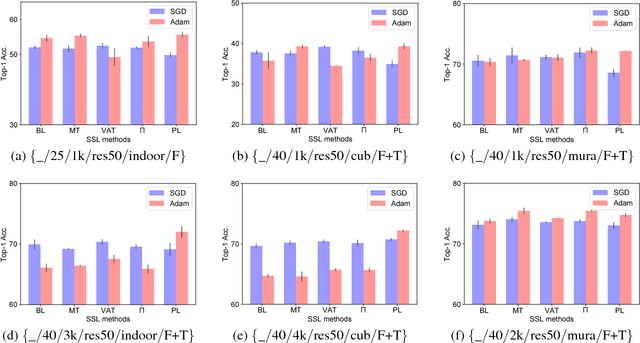
Semi-Supervised Learning (SSL) has been proved to be an effective way to leverage both labeled and unlabeled data at the same time. Recent semi-supervised approaches focus on deep neural networks and have achieved promising results on several benchmarks: CIFAR10, CIFAR100 and SVHN. However, most of their experiments are based on models trained from scratch instead of pre-trained models. On the other hand, transfer learning has demonstrated its value when the target domain has limited labeled data. Here comes the intuitive question: is it possible to incorporate SSL when fine-tuning a pre-trained model? We comprehensively study how SSL methods starting from pretrained models perform under varying conditions, including training strategies, architecture choice and datasets. From this study, we obtain several interesting and useful observations. While practitioners have had an intuitive understanding of these observations, we do a comprehensive emperical analysis and demonstrate that: (1) the gains from SSL techniques over a fully-supervised baseline are smaller when trained from a pre-trained model than when trained from random initialization, (2) when the domain of the source data used to train the pre-trained model differs significantly from the domain of the target task, the gains from SSL are significantly higher and (3) some SSL methods are able to advance fully-supervised baselines (like Pseudo-Label). We hope our studies can deepen the understanding of SSL research and facilitate the process of developing more effective SSL methods to utilize pre-trained models. Code is now available at github.
Realistic Evaluation of Deep Semi-Supervised Learning Algorithms
Oct 26, 2018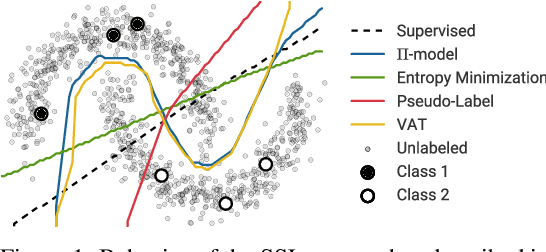

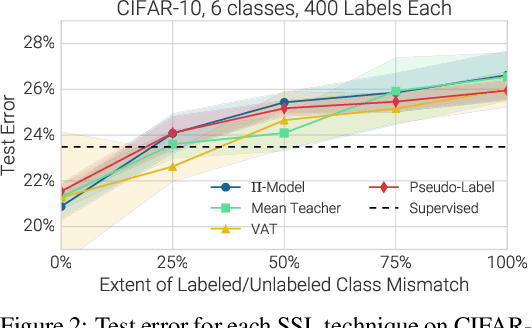

Semi-supervised learning (SSL) provides a powerful framework for leveraging unlabeled data when labels are limited or expensive to obtain. SSL algorithms based on deep neural networks have recently proven successful on standard benchmark tasks. However, we argue that these benchmarks fail to address many issues that these algorithms would face in real-world applications. After creating a unified reimplementation of various widely-used SSL techniques, we test them in a suite of experiments designed to address these issues. We find that the performance of simple baselines which do not use unlabeled data is often underreported, that SSL methods differ in sensitivity to the amount of labeled and unlabeled data, and that performance can degrade substantially when the unlabeled dataset contains out-of-class examples. To help guide SSL research towards real-world applicability, we make our unified reimplemention and evaluation platform publicly available.
Teacher-Student Curriculum Learning
Nov 29, 2017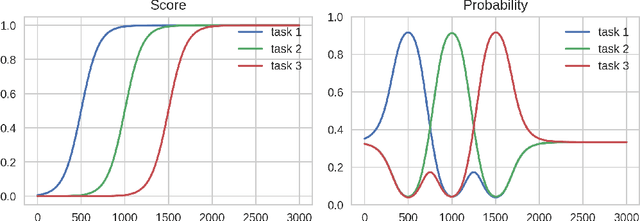
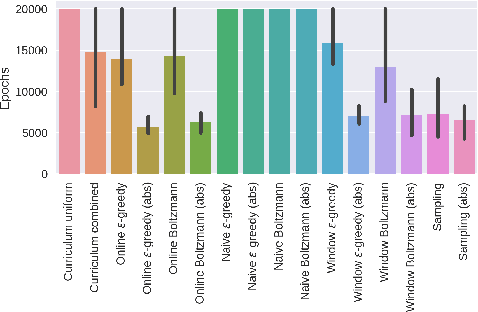
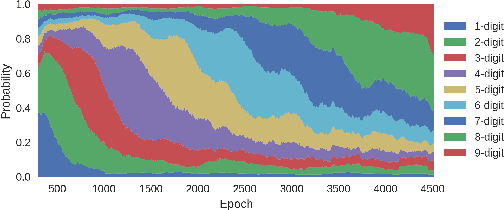
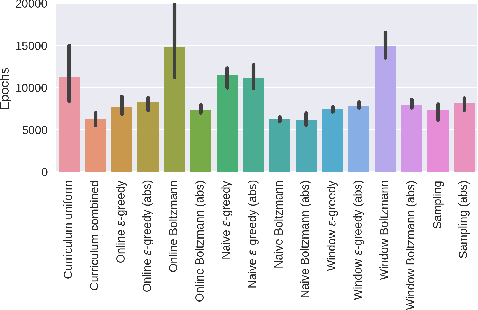
We propose Teacher-Student Curriculum Learning (TSCL), a framework for automatic curriculum learning, where the Student tries to learn a complex task and the Teacher automatically chooses subtasks from a given set for the Student to train on. We describe a family of Teacher algorithms that rely on the intuition that the Student should practice more those tasks on which it makes the fastest progress, i.e. where the slope of the learning curve is highest. In addition, the Teacher algorithms address the problem of forgetting by also choosing tasks where the Student's performance is getting worse. We demonstrate that TSCL matches or surpasses the results of carefully hand-crafted curricula in two tasks: addition of decimal numbers with LSTM and navigation in Minecraft. Using our automatically generated curriculum enabled to solve a Minecraft maze that could not be solved at all when training directly on solving the maze, and the learning was an order of magnitude faster than uniform sampling of subtasks.