 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColour augmentation for improved semi-supervised semantic segmentation
Oct 09, 2021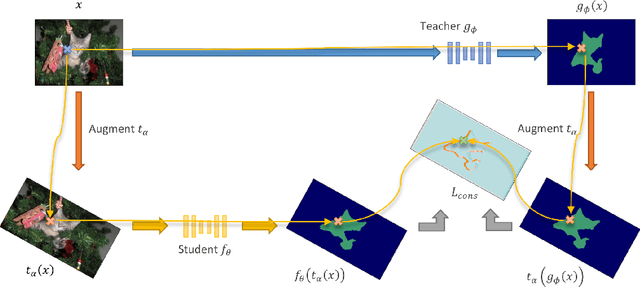
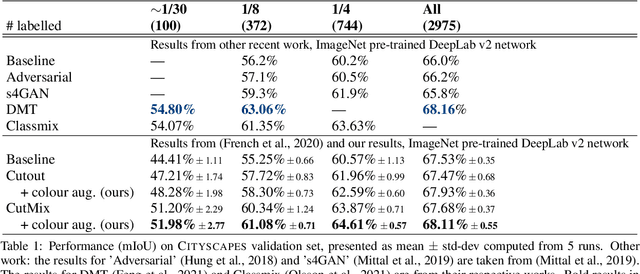
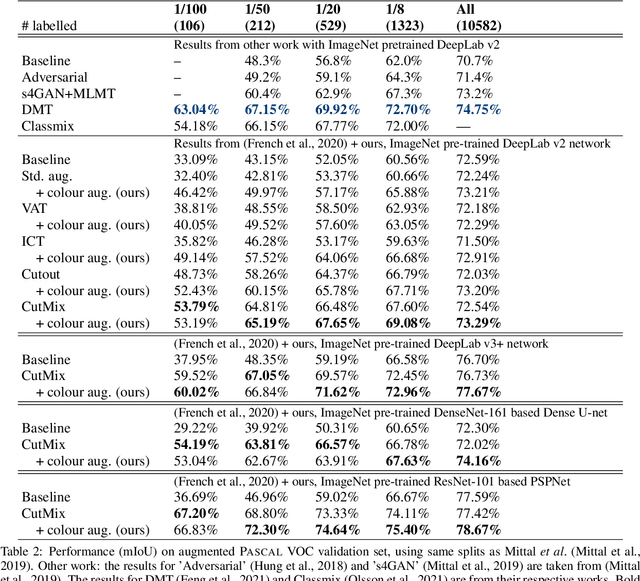
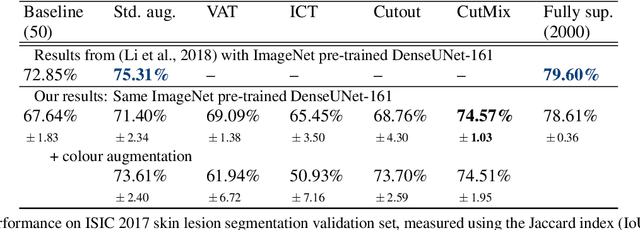
Consistency regularization describes a class of approaches that have yielded state-of-the-art results for semi-supervised classification. While semi-supervised semantic segmentation proved to be more challenging, a number of successful approaches have been recently proposed. Recent work explored the challenges involved in using consistency regularization for segmentation problems. In their self-supervised work Chen et al. found that colour augmentation prevents a classification network from using image colour statistics as a short-cut for self-supervised learning via instance discrimination. Drawing inspiration from this we find that a similar problem impedes semi-supervised semantic segmentation and offer colour augmentation as a solution, improving semi-supervised semantic segmentation performance on challenging photographic imagery.
Milking CowMask for Semi-Supervised Image Classification
Apr 03, 2020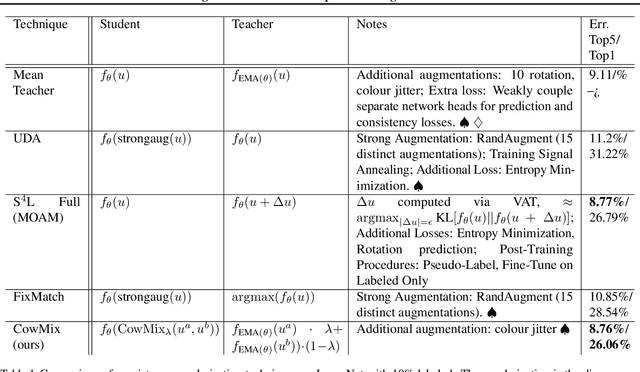

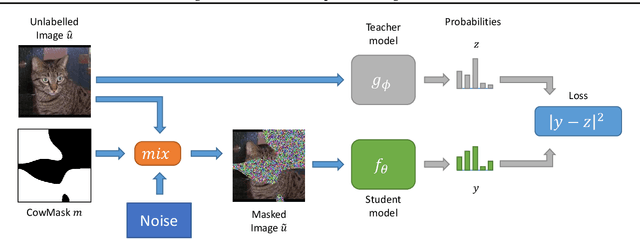
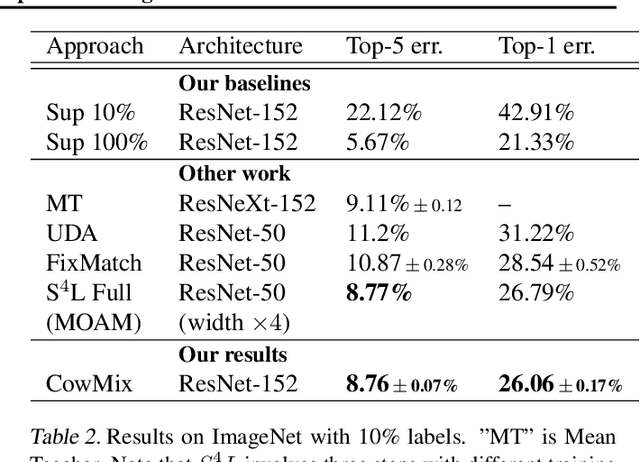
Consistency regularization is a technique for semi-supervised learning that has recently been shown to yield strong results for classification with few labeled data. The method works by perturbing input data using augmentation or adversarial examples, and encouraging the learned model to be robust to these perturbations on unlabeled data. Here, we evaluate the use of a recently proposed augmentation method, called CowMasK, for this purpose. Using CowMask as the augmentation method in semi-supervised consistency regularization, we establish a new state-of-the-art result on Imagenet with 10% labeled data, with a top-5 error of 8.76% and top-1 error of 26.06%. Moreover, we do so with a method that is much simpler than alternative methods. We further investigate the behavior of CowMask for semi-supervised learning by running many smaller scale experiments on the small image benchmarks SVHN, CIFAR-10 and CIFAR-100, where we achieve results competitive with the state of the art, and where we find evidence that the CowMask perturbation is widely applicable. We open source our code at https://github.com/google-research/google-research/tree/master/milking_cowmask
Consistency regularization and CutMix for semi-supervised semantic segmentation
Jun 05, 2019
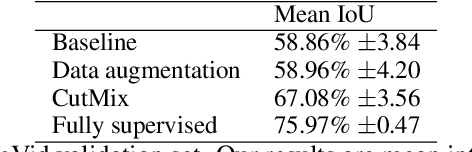
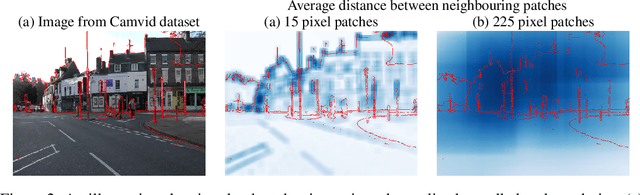

Consistency regularization describes a class of approaches that have yielded ground breaking results in semi-supervised classification problems. Prior work has established the cluster assumption -- under which the data distribution consists of uniform class clusters of samples separated by low density regions -- as key to its success. We analyse the problem of semantic segmentation and find that the data distribution does not exhibit low density regions separating classes and offer this as an explanation for why semi-supervised segmentation is a challenging problem. We adapt the recently proposed CutMix regularizer for semantic segmentation and find that it is able to overcome this obstacle, leading to a successful application of consistency regularization to semi-supervised semantic segmentation.