 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistency regularization and CutMix for semi-supervised semantic segmentation
Paper and Code

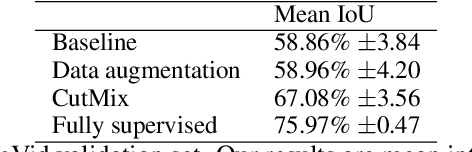
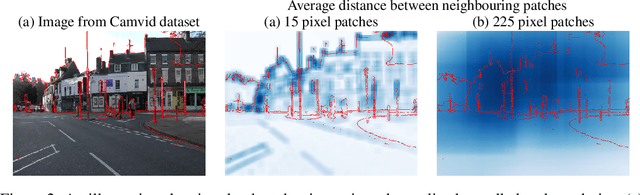

Consistency regularization describes a class of approaches that have yielded ground breaking results in semi-supervised classification problems. Prior work has established the cluster assumption -- under which the data distribution consists of uniform class clusters of samples separated by low density regions -- as key to its success. We analyse the problem of semantic segmentation and find that the data distribution does not exhibit low density regions separating classes and offer this as an explanation for why semi-supervised segmentation is a challenging problem. We adapt the recently proposed CutMix regularizer for semantic segmentation and find that it is able to overcome this obstacle, leading to a successful application of consistency regularization to semi-supervised semantic segmentation.