 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Does It Take to Be a Good AI Research Agent? Studying the Role of Ideation Diversity
Nov 19, 2025AI research agents offer the promise to accelerate scientific progress by automating the design, implementation, and training of machine learning models. However, the field is still in its infancy, and the key factors driving the success or failure of agent trajectories are not fully understood. We examine the role that ideation diversity plays in agent performance. First, we analyse agent trajectories on MLE-bench, a well-known benchmark to evaluate AI research agents, across different models and agent scaffolds. Our analysis reveals that different models and agent scaffolds yield varying degrees of ideation diversity, and that higher-performing agents tend to have increased ideation diversity. Further, we run a controlled experiment where we modify the degree of ideation diversity, demonstrating that higher ideation diversity results in stronger performance. Finally, we strengthen our results by examining additional evaluation metrics beyond the standard medal-based scoring of MLE-bench, showing that our findings still hold across other agent performance metrics.
RL-finetuning LLMs from on- and off-policy data with a single algorithm
Mar 25, 2025We introduce a novel reinforcement learning algorithm (AGRO, for Any-Generation Reward Optimization) for fine-tuning large-language models. AGRO leverages the concept of generation consistency, which states that the optimal policy satisfies the notion of consistency across any possible generation of the model. We derive algorithms that find optimal solutions via the sample-based policy gradient and provide theoretical guarantees on their convergence. Our experiments demonstrate the effectiveness of AGRO in both on-policy and off-policy settings, showing improved performance on the mathematical reasoning dataset over baseline algorithms.
The KoLMogorov Test: Compression by Code Generation
Mar 18, 2025Compression is at the heart of intelligence. A theoretically optimal way to compress any sequence of data is to find the shortest program that outputs that sequence and then halts. However, such 'Kolmogorov compression' is uncomputable, and code generating LLMs struggle to approximate this theoretical ideal, as it requires reasoning, planning and search capabilities beyond those of current models. In this work, we introduce the KoLMogorov-Test (KT), a compression-as-intelligence test for code generating LLMs. In KT a model is presented with a sequence of data at inference time, and asked to generate the shortest program that produces the sequence. We identify several benefits of KT for both evaluation and training: an essentially infinite number of problem instances of varying difficulty is readily available, strong baselines already exist, the evaluation metric (compression) cannot be gamed, and pretraining data contamination is highly unlikely. To evaluate current models, we use audio, text, and DNA data, as well as sequences produced by random synthetic programs. Current flagship models perform poorly - both GPT4-o and Llama-3.1-405B struggle on our natural and synthetic sequences. On our synthetic distribution, we are able to train code generation models with lower compression rates than previous approaches. Moreover, we show that gains on synthetic data generalize poorly to real data, suggesting that new innovations are necessary for additional gains on KT.
Soft Policy Optimization: Online Off-Policy RL for Sequence Models
Mar 07, 2025

RL-based post-training of language models is almost exclusively done using on-policy methods such as PPO. These methods cannot learn from arbitrary sequences such as those produced earlier in training, in earlier runs, by human experts or other policies, or by decoding and exploration methods. This results in severe sample inefficiency and exploration difficulties, as well as a potential loss of diversity in the policy responses. Moreover, asynchronous PPO implementations require frequent and costly model transfers, and typically use value models which require a large amount of memory. In this paper we introduce Soft Policy Optimization (SPO), a simple, scalable and principled Soft RL method for sequence model policies that can learn from arbitrary online and offline trajectories and does not require a separate value model. In experiments on code contests, we shows that SPO outperforms PPO on pass@10, is significantly faster and more memory efficient, is able to benefit from off-policy data, enjoys improved stability, and learns more diverse (i.e. soft) policies.
Does equivariance matter at scale?
Oct 30, 2024Given large data sets and sufficient compute, is it beneficial to design neural architectures for the structure and symmetries of each problem? Or is it more efficient to learn them from data? We study empirically how equivariant and non-equivariant networks scale with compute and training samples. Focusing on a benchmark problem of rigid-body interactions and on general-purpose transformer architectures, we perform a series of experiments, varying the model size, training steps, and dataset size. We find evidence for three conclusions. First, equivariance improves data efficiency, but training non-equivariant models with data augmentation can close this gap given sufficient epochs. Second, scaling with compute follows a power law, with equivariant models outperforming non-equivariant ones at each tested compute budget. Finally, the optimal allocation of a compute budget onto model size and training duration differs between equivariant and non-equivariant models.
What Makes Large Language Models Reason in (Multi-Turn) Code Generation?
Oct 10, 2024



Prompting techniques such as chain-of-thought have established themselves as a popular vehicle for improving the outputs of large language models (LLMs). For code generation, however, their exact mechanics and efficacy are under-explored. We thus investigate the effects of a wide range of prompting strategies with a focus on automatic re-prompting over multiple turns and computational requirements. After systematically decomposing reasoning, instruction, and execution feedback prompts, we conduct an extensive grid search on the competitive programming benchmarks CodeContests and TACO for multiple LLM families and sizes (Llama 3.0 and 3.1, 8B, 70B, 405B, and GPT-4o). Our study reveals strategies that consistently improve performance across all models with small and large sampling budgets. We then show how finetuning with such an optimal configuration allows models to internalize the induced reasoning process and obtain improvements in performance and scalability for multi-turn code generation.
RLEF: Grounding Code LLMs in Execution Feedback with Reinforcement Learning
Oct 02, 2024


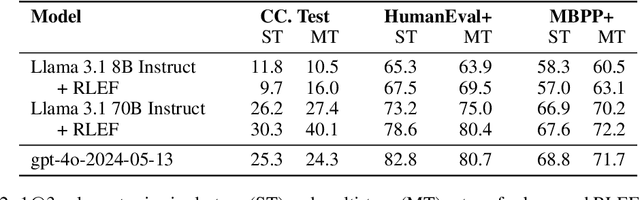
Large language models (LLMs) deployed as agents solve user-specified tasks over multiple steps while keeping the required manual engagement to a minimum. Crucially, such LLMs need to ground their generations in any feedback obtained to reliably achieve desired outcomes. We propose an end-to-end reinforcement learning method for teaching models to leverage execution feedback in the realm of code synthesis, where state-of-the-art LLMs struggle to improve code iteratively compared to independent sampling. We benchmark on competitive programming tasks, where we achieve new start-of-the art results with both small (8B parameters) and large (70B) models while reducing the amount of samples required by an order of magnitude. Our analysis of inference-time behavior demonstrates that our method produces LLMs that effectively leverage automatic feedback over multiple steps.
Information-driven Affordance Discovery for Efficient Robotic Manipulation
May 06, 2024Robotic affordances, providing information about what actions can be taken in a given situation, can aid robotic manipulation. However, learning about affordances requires expensive large annotated datasets of interactions or demonstrations. In this work, we argue that well-directed interactions with the environment can mitigate this problem and propose an information-based measure to augment the agent's objective and accelerate the affordance discovery process. We provide a theoretical justification of our approach and we empirically validate the approach both in simulation and real-world tasks. Our method, which we dub IDA, enables the efficient discovery of visual affordances for several action primitives, such as grasping, stacking objects, or opening drawers, strongly improving data efficiency in simulation, and it allows us to learn grasping affordances in a small number of interactions, on a real-world setup with a UFACTORY XArm 6 robot arm.
CodeIt: Self-Improving Language Models with Prioritized Hindsight Replay
Feb 07, 2024



Large language models are increasingly solving tasks that are commonly believed to require human-level reasoning ability. However, these models still perform very poorly on benchmarks of general intelligence such as the Abstraction and Reasoning Corpus (ARC). In this paper, we approach ARC as a programming-by-examples problem, and introduce a novel and scalable method for language model self-improvement called Code Iteration (CodeIt). Our method iterates between 1) program sampling and hindsight relabeling, and 2) learning from prioritized experience replay. By relabeling the goal of an episode (i.e., the target program output given input) to the realized output produced by the sampled program, our method effectively deals with the extreme sparsity of rewards in program synthesis. Applying CodeIt to the ARC dataset, we demonstrate that prioritized hindsight replay, along with pre-training and data-augmentation, leads to successful inter-task generalization. CodeIt is the first neuro-symbolic approach that scales to the full ARC evaluation dataset. Our method solves 15% of ARC evaluation tasks, achieving state-of-the-art performance and outperforming existing neural and symbolic baselines.
A Hitchhiker's Guide to Geometric GNNs for 3D Atomic Systems
Dec 12, 2023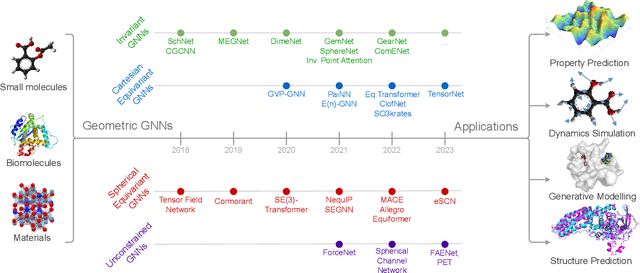
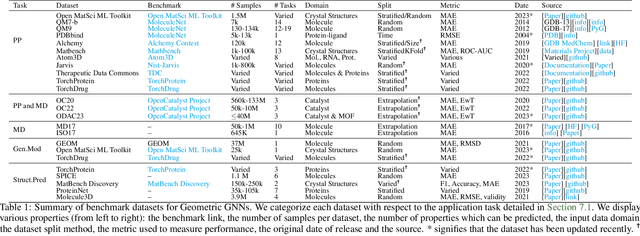
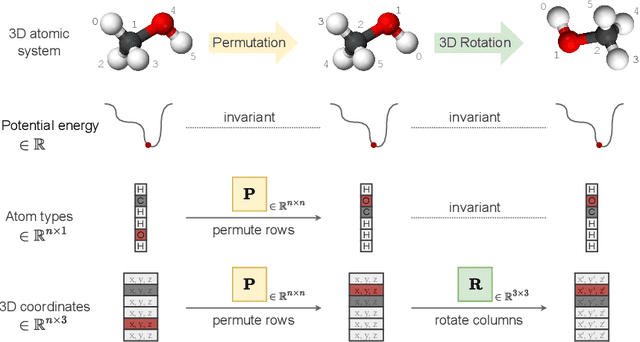
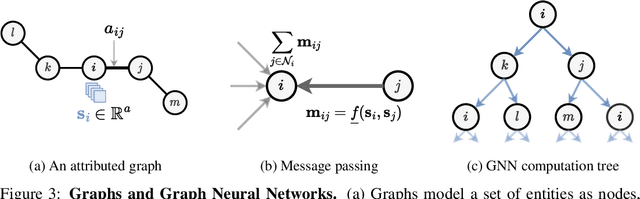
Recent advances in computational modelling of atomic systems, spanning molecules, proteins, and materials, represent them as geometric graphs with atoms embedded as nodes in 3D Euclidean space. In these graphs, the geometric attributes transform according to the inherent physical symmetries of 3D atomic systems, including rotations and translations in Euclidean space, as well as node permutations. In recent years, Geometric Graph Neural Networks have emerged as the preferred machine learning architecture powering applications ranging from protein structure prediction to molecular simulations and material generation. Their specificity lies in the inductive biases they leverage -- such as physical symmetries and chemical properties -- to learn informative representations of these geometric graphs. In this opinionated paper, we provide a comprehensive and self-contained overview of the field of Geometric GNNs for 3D atomic systems. We cover fundamental background material and introduce a pedagogical taxonomy of Geometric GNN architectures:(1) invariant networks, (2) equivariant networks in Cartesian basis, (3) equivariant networks in spherical basis, and (4) unconstrained networks. Additionally, we outline key datasets and application areas and suggest future research directions. The objective of this work is to present a structured perspective on the field, making it accessible to newcomers and aiding practitioners in gaining an intuition for its mathematical abstractions.